







第一步:文本预处理
一般的文本的常见预处理包括四个步骤:
-
将文本作为字符串加载到内存中。
-
将字符串拆分为词元(如单词和字符)。
-
建立一个词表,将拆分的词元映射到数字索引。
-
将文本转换为数字索引序列,方便模型操作。
1.读取数据集
- 进行忽略标点符号,和大写处理。
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
2.词元化(tokenize)
token的意思是词元,而-ize的后缀则是“使动用法”可以翻译为化字。
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
3.词表(vocabular)
词表是一个字典,用来把字符串类型的词元映射到从0开始的数字索引中。训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus),然后根据词元出现的频率分配索引,很少出现的词元通常被移除,这可以降低复杂性。
第一步:统计词元频率并排序
def count_corpus(tokens): #@save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 将词元列表展平成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
# 按出现频率排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
第二步:根据排序后的token进行构建词表
对于Vocab类,有两个成员,一个idx_to_token,通过索引找token(列表的形式),一个是token_to_idx,通过token找id(字典的形式)
tips:每一条文字行转换成一个数字索引列表
for i in [0, 10]:
print('文本:', tokens[i])
print('索引:', vocab[tokens[i]]) # vocab['the'] = vocab.token_to_idx.items()
第二步:读取长序列数据
序列数据一般是长并且连续的,可以通过使用随机采样和顺序分区两种方法进行读取。
下面的引例中,减去1,是因为我们需要考虑标签。
下面我们生成一个从 0 到 34 的序列。 假设批量大小为 2 ,时间步数为 5 ,这意味着可以生成 ⌊(35−1)/5⌋=6 个“特征-标签”子序列对。 如果设置小批量大小为 2 ,我们只能得到 3 个小批量。
第三步:循环神经网络
n为批量大小,q为词表大小(因为X转换为one-hot编码了)
模型介绍
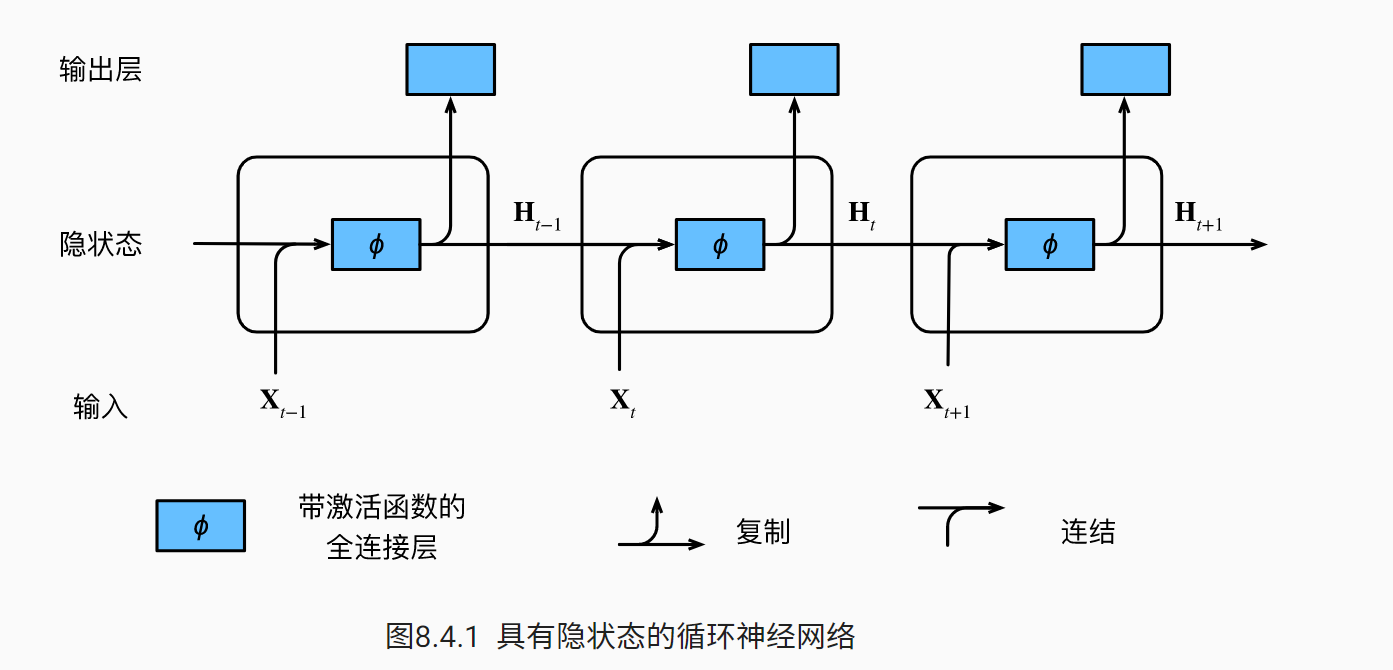
该图展现了RNN在三个相邻时间步的计算逻辑,在任意时间步t,隐状态的计算可以被看为:
拼接当前时间步 t 的输入 Xt 和前一时间步 t−1 的隐状态 Ht−1 ;
将拼接的结果送入带有激活函数 ϕ 的全连接层。 全连接层的输出是当前时间步 t 的隐状态 Ht 。
数学公式:
X为n x d大小的矩阵,Ht为n x h大小的矩阵其中Ht:
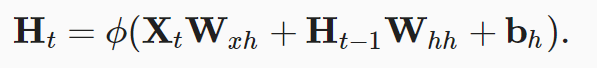
Ot的大小为n x q:

注意,输出的形状有时候我发现有(时间步数 x 批量大小,词表大小),X一般为(时间步数量,批量大小,词表大小)
模型评价方法:困惑度(perplexity)
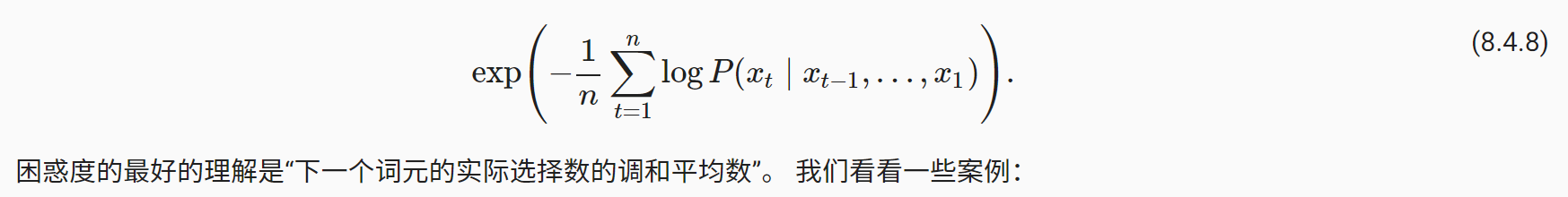
通过时间的反向传播
先略了。
1.独热码
因为在train_iter中每个词元都表示为一个数字索引,但直接输入网络会很困难,一般把词元表示为更有表现力的特征向量,最简单的表示就是独热码(one-hot),
简言之,将每个索引映射为相互不同的单位向量:假设词表中不同词元的数目为 N (即len(vocab)), 词元索引的范围为 0 到 N−1 。 如果词元的索引是整数 i , 那么我们将创建一个长度为 N 的全 0 向量, 并将第 i 处的元素设置为 1 。 此向量是原始词元的一个独热向量。
2.RNN模型
- 初始化模型返回隐状态(H0)
- 定义rnn网络
- 整合为RNNModelScratch类方便调用
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
Y.shape, len(new_state), new_state[0].shape
3.梯度裁剪
通过下面的公式进行梯度裁剪

代码实现
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params)) # 一个参数可能会有很多个偏导,所以求和。
if norm > theta:
for param in params:
param.grad[:] *= theta / norm
4.训练
- 序列数据的不同采样方法(随机采样和顺序分区)将导致隐状态初始化的差异。
- 我更新模型参数之前裁剪梯度。 这样的操作的目的是:即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
- 用困惑度来评价模型。
5.预测
定义预测函数来生成prefix之后的新字符, 其中的prefix是一个用户提供的包含多个字符的字符串,在预测前有一个预热期。
















 865
865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











