







目录
前言
机器学习(machine learning,ML)是一类强大的可以从经验中学习的技术。
1.1 我们将学到什么?
- What?
– 深度学习里有哪些技术? - How?
– 如何实现和调参? - Why?
– 背后的原因(直觉、数学)?
1.2 机器学习的相关组件
1. 数据(data)
如果没有数据,那么数据科学毫无用武之地。
- 每个数据集由一个个样本(example/sample)组成,样本有时也叫作数据点(data point)或数据实例(data instance)。
通常每个样本有一组称为特征(feature)或协变量(covariate)的属性组成。 - 如果在机器学习中,要预测的是一个特殊的属性,它称为标签(label)或目标(target)。
- 当每个样本的特征类别数量都相同的时候,其特征向量是固定长度的,这个长度被称为数据的维数(dimensionality)。固定长度的特征向量是一个方便的属性,它可以用来量化学习大量样本。
深度学习的一个主要优势就是可以处理不同长度的数据。(文本,语音)
更多的数据可以被用来训练出更加强大的模型,从而减少对预先假设的依赖
仅仅拥有海量的数据是不够的,我们还需要正确的数据。
2 . 模型(model)
深度学习与经典方法的区别主要在于:深度学习关注功能强大的模型,这些模型由神经网络错综复杂地交织在一起,包含层层数据转换。
3. 目标函数(objective function)
- 机器学习就是”从经验中学习“,“学习”是指模型自主提高完成某些任务的性能。
- 在机器学习中,我们需要定义对模型的优劣程度的度量,这个度量在大多数情况下是“可优化”的,这被称为目标函数(objective function)。
- 我们通常定义一个目标函数,并希望优化它到最小值。因为越小越好,所以这些函数被称为损失函数(loss/cost function)
- 通常损失函数是根据模型参数定义的,并取决于数据集(dataset)。该数据集由一些为训练而采集的样本组成,称为训练数据集(training dataset)或训练集(training set)。然而在训练数据集上表现良好的模型,并不一定在“”新数据集“上由同样的性能,这里的”新数据集“通常称为测试数据集(test dataset)或测试集(test set)。
所以,可用数据集通常可以分成两部分:训练数据集用于拟合模型参数,测试数据集用于评估拟合的模型。
当一个模型在训练集上表现良好,但不能推广到测试集时,这个模型被称为过拟合(overfitting)。
4. 优化算法(algorithm)
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
1.3 各种机器学习问题
1. 监督学习(supervised learning)
监督学习擅长在“给定输入特征”的情况下预测标签。
- 每个“特征-标签”对都称为一个样本(example)。
- 有时,即使标签是未知的,样本也可以指代输入特征。
- 我们的目标是生成一个模型,能够将任何输入特征映射到标签(即预测)。
监督学习的学习过程一般可以分为3个步骤:
- 从已知大量数据样本中随机选取一个子集,为每个样本获取真实标签。有时,这些样本已有标签(例如,患者是否在下一年内康复?);有时,这些样本可能需要被人工标记(例如,图像分类)。这些输入和相应的标签一起构成了训练数据集;
- 选择有监督的学习算法,它将训练数据集作为输入,并输出一个“已完成学习的模型”;
- 将之前没有见过的样本特征放到这个“已完成学习的模型”中,使用模型的输出作为相应标签的预测。
整个监督学习的过程如下图所示:
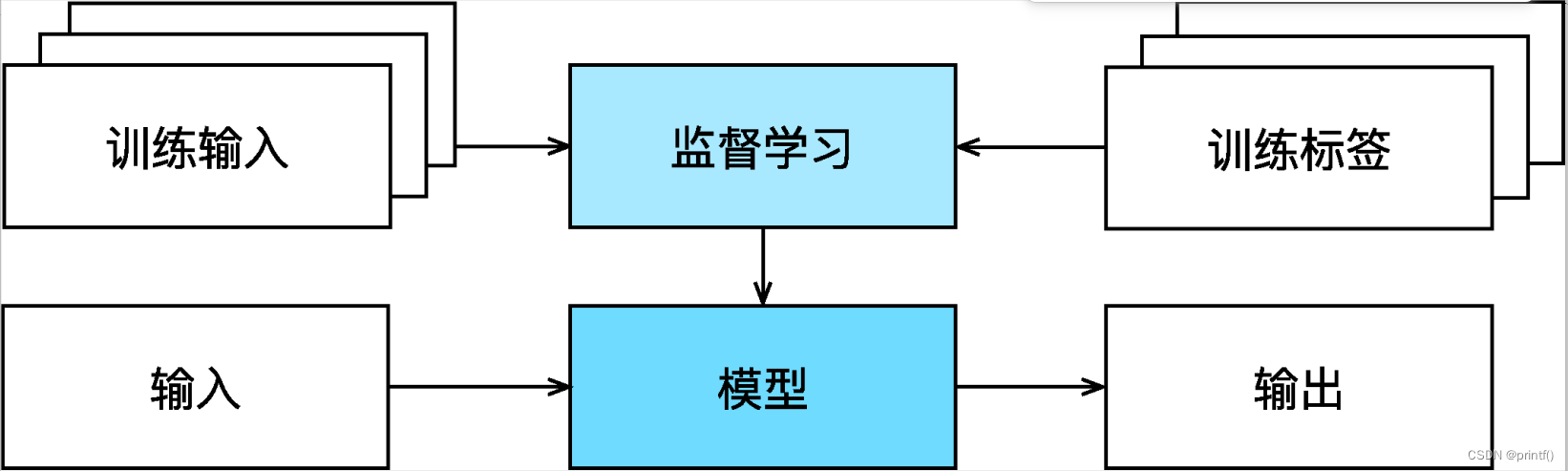
- 常见的监督学习类型
- 回归(regression)
回归是最简单的监督学习任务之一。任何有关”有多少“的问题很可能就是回归问题。例如:气温预测、股票预测、房价预测、费用预测~~~ - 分类(classifiction)
分类问题希望模型能够预测样本属于哪个类别(category),其正式称为类(class)。例如:二项分类:猫狗大战,多项分类:手写数字识别、鲜花识别~~~
注意:最常见的类别不一定是最终用于决策的类别。
假设要寻来你一个毒蘑菇检测分类器,可能输出一个蘑菇的照片,输出显示为毒蘑菇的概率是0.2,但是我们也不能会吃它,因为不值得冒20%的死亡风向。不确定性风险的影响远远大于收益。
因此我们要将”预期风险“作为损失函数,即需要将结果乘以与之相关的收益(或上海)。
在这种情况下,食用蘑菇的损失为0.2∞ + 0.80 = ∞,而丢弃蘑菇的损失为0.20 + 0.81 = 0.8。
- 标注问题
如果训练一个二分类器来区分猫和狗,无论模型有多精确,当分类器遇到新的动物时也可能会束手无策。
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。例如:发布博客的标签、专业名词的批注~~~ - 搜索
以网络搜索为例,目标不是简单的“查询(query)-网页(page)”分类,而是在海量搜索结果中找到用户最需要的那部分。 搜索结果的排序也十分重要,学习算法需要输出有序的元素子集。
换句话说,如果要求我们输出字母表中的前5个字母,返回“A、B、C、D、E”和“C、A、B、E、D”是不同的。 即使结果集是相同的,集内的顺序有时却很重要。
该问题的一种可能的解决方案:首先为集合中的每个元素分配相应的相关性分数,然后检索评级最高的元素。 - 推荐系统
推荐系统的目标时向特定的用户进行”个性化“推荐。
在某些应用中,客户会提供明确反馈,表达他们对特定产品的喜爱程度。 推荐系统会为“给定用户和物品”的匹配性打分,这个“分数”可能是估计的评级或购买的概率。 由此,对于任何给定的用户,推荐系统都可以检索得分最高的对象集,然后将其推荐给用户。
尽管推荐系统具有巨大的应用价值,但单纯用它作为预测模型仍存在一些缺陷。 首先,我们的数据只包含“审查后的反馈”:用户更倾向于给他们感觉强烈的事物打分。 例如,在五分制电影评分中,会有许多五星级和一星级评分,但三星级却明显很少。 此外,推荐系统有可能形成反馈循环:推荐系统首先会优先推送一个购买量较大(可能被认为更好)的商品,然而目前用户的购买习惯往往是遵循推荐算法,但学习算法并不总是考虑到这一细节,进而更频繁地被推荐。 综上所述,关于如何处理审查、激励和反馈循环的许多问题,都是重要的开放性研究问题。
- 序列学习
以上大多数问题都具有固定大小的输入和产生固定大小的输出。
如果输入的样本之间没有任何关系,以上模型可能完美无缺。 但是如果输入是连续的,模型可能就需要拥有“记忆”功能。
序列学习需要摄取输入序列或预测输出序列,或两者兼而有之。 具体来说,输入和输出都是可变长度的序列。例如: 标记和解析、自动语音识别、文本到语音、机器翻译。
2. 无监督学习(unsupervised learning)
- 监督学习:需要向模型提供巨大数据集:每个样本包含特征和相应的标签值。
- 无监督学习:数据集的每个样本中不含标签值的机器学习问题。
- 常见的无监督学习类型
- 聚类(clustering)问题:能否在没有标签的情况下,给数据分类。例如:给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
- 主成分分析(principal component analysis)问题: **能否找到少量的参数来准确地捕捉数据的线性相关属性?**例如:一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。
- 因果关系(causality)和概率图模型(probabilistic graphical model)问题:**能否描述观察到的许多数据的根本原因?**例如:果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
- 生成对抗网络(generative adversarial networks): 能否为我们提供一种合成数据的方法,甚至对于像图像和音频这样复杂的非结构化数据。
3. 与环境互动
不管是监督学习,还是无监督学习,都会预先获取大量数据,然会启动模型,不再与环境交互。都是在算法环境断开后进行的,被称为离线学习(offlinelearning)。
- 优点:我们可以孤立地进行模式识别,而不必分心其他问题。
- 缺点:能解决的问题相当有限。
这时我们可能会期望人工智能不仅能够做出预测,而且能够与真实环境互动。 与预测不同,“与真实环境互动”实际上会影响环境。 这里的人工智能是“智能代理”,而不仅是“预测模型”。 因此,我们必须考虑到它的行为可能会影响未来的观察结果。
4. 强化学习(reinforcement learning)
强化学习:使用机器学习开发与环境交互并采取行动。
强化学习的步骤如下:
智能体(agent)在一系列的时间步骤上与环境交互。 在每个特定时间点,智能体从环境接收一些观察(observation),并且必须选择一个动作(action),然后通过某种机制(有时称为执行器)将其传输回环境,最后智能体从环境中获得奖励(reward)。 此后新一轮循环开始,智能体接收后续观察,并选择后续操作,依此类推。
强化学习的目标是产生一个好的策略(policy)。 强化学习智能体选择的“动作”受策略控制,即一个从环境观察映射到行动的功能。
强化学习的过程图如下:

强化学习的特点:
- 强化学习框架的通用性十分强大。可以将任何监督学习问题转化为强化学习问题。
- 强化学习还可以解决许多监督学习无法解决的问题。在监督学习中,我们总是希望输入与正确的标签相关联。 但在强化学习中,我们并不假设环境告诉智能体每个观测的最优动作。 一般来说,智能体只是得到一些奖励。 此外,环境甚至可能不会告诉是哪些行为导致了奖励。
- 强化学习者必须处理学分分配(credit assignment)问题:决定哪些行为是值得奖励的,哪些行为是需要惩罚的。 就像一个员工升职一样,这次升职很可能反映了前一年的大量的行动。 要想在未来获得更多的晋升,就需要弄清楚这一过程中哪些行为导致了晋升。
- 强化学习可能还必须处理部分可观测性问题。 也就是说,当前的观察结果可能无法阐述有关当前状态的所有信息。 比方说,一个清洁机器人发现自己被困在一个许多相同的壁橱的房子里。 推断机器人的精确位置(从而推断其状态),需要在进入壁橱之前考虑它之前的观察结果。
- 强化学习智能体必须不断地做出选择:是应该利用当前最好的策略,还是探索新的策略空间(放弃一些短期回报来换取知识)。
一般的强化学习问题是一个非常普遍的问题。 智能体的动作会影响后续的观察,而奖励只与所选的动作相对应。 环境可以是完整观察到的,也可以是部分观察到的,解释所有这些复杂性可能会对研究人员要求太高。 此外,并不是每个实际问题都表现出所有这些复杂性。 因此,学者们研究了一些特殊情况下的强化学习问题。
- 当环境可被完全观察到时,强化学习问题被称为马尔可夫决策过程(markov decision process)。
- 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。
- 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
参考文章
[引用链接] (https://zh-v2.d2l.ai/chapter_introduction/index.html)















 6244
6244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









