







ES优化 开篇之作,由于时间紧张和能力有限,时间没来得及详细整理,望不要吐槽
1. 【 ES分词 空闲的时候整理一波 】
相关性算分是指文档与查询语句间的相关度,英文为relevance
Q: 通过倒排索引可以获取与查询语句相匹配的文档列表,那么 如何将最符合用户查询需求的文档放在前列呢 ?
A: 本质是一个排序问题,排序是依据是相关性算分。
实例
倒排索引
| 单词 | 文档ID列表 |
| alfred | 1,2 |
| way | 1 |
相关性算分的几个重要概念:
1. Term Frequency( TF )词频,即单词在该文档中出现的次数。词频越高,相关度越高。
2. Document Frequency ( DF ) 文档频率,即单词出现的文档数。
3. Inverse Document Frequency ( IDF ) 逆向文档频率,与文档频率相反,简单理解为 1/DF。即单词出现的文档数越少,相关度越高。
4. Field-length Norm 文档越短,相关性越高。
2. ES如何做到亿级数据查询毫秒级返回 ?
今日一名高级开发小伙伴儿突然问道这个问题,刚开始听到这个命题,也是有点儿一头雾水。
当前ES的数据总量是300万,距离规划每天500万有些差距。第一次查询时间500毫秒,二次查询5毫秒。
有一个组件叫 filesystem 可以值得一探究竟
【未完待续】
https://cloud.tencent.com/developer/article/1511890
https://mp.weixin.qq.com/s/yNXcFhZ3OKEXXMq2lw085w
reflush&flush
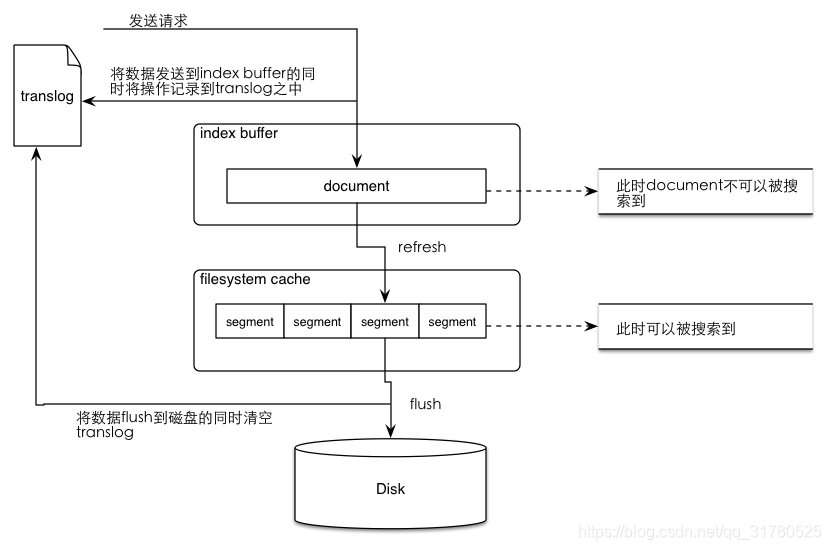
ES索引写入性能优化
1.用bulk批量写入
2.默认的refresh间隔是1s,用index.refresh_interval参数可以设置,这样会其强迫es每秒中都将内存中的数据写入磁盘中,创建一个新的segment file。
正是这个间隔,让我们每次写入数据后,1s以后才能看到。
但是如果我们将这个间隔调大,比如30s,可以接受写入的数据30s后才看到,那么我们就可以获取更大的写入吞吐量,因为30s内都是写内存的,每隔30s才会创建一个segment file。
3.使用自动生成的id
如果我们要手动给es document设置一个id,那么es需要每次都去确认一下那个id是否存在,这个过程是比较耗费时间的。
如果我们使用自动生成的id,那么es就可以跳过这个步骤,写入性能会更好。对于你的业务中的表id,可以作为es document的一个field
4.禁止refresh和replia
如果我们要一次性加载大批量的数据进es,可以先禁止refresh和replia复制,将index.refresh_interval设置为-1,将index.number_of_replicas设置为0即可。
这可能会导致我们的数据丢失,因为没有refresh和replica机制了。
但是不需要创建segment file,也不需要将数据replica复制到其他的replica shasrd上面去。
此时写入的速度会非常快,一旦写完之后,可以将refresh和replica修改回正常的状态。














 3882
3882











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









