









本文你将看到:
- MySQL、SQL、ORM、Sequelize 在概念上的关系
- Sequelize 的用法
- Sequelize 中联表关系的概念、用法、原理、区别
- 如何优化数据库查询
1 概念
MySQL
大部分人对 MySQL、SQL 是有了解的,毕竟教科书里都写着。 MySQL 是一种典型的关系型数据库嘛,怎么叫关系呢?
简单说,关系型数据库是由多张能互相联接的二维行列表格组成的数据库。
这里两个点:::二维行列表::(体现在个体表数据结构上)、::互相连接::(体现在表关系和库引擎特点上)。
相较于 MongoDB 这种 NoSQL,二维行列表带来的优势在于:
- 数据结构严谨带来的可靠:每一列的数据类型甚至大小都被模型定义,一切稳稳当当
- 「平层」带来的理解便利:每一条数据都是「平层」的,毕竟自由嵌套读起来真的太南了
SQL
既然关系型数据库是一个统一的标准,那只要各家都按标准实现,剩下的事就可以统一了,比如对数据库的访问。
SQL 就是干这个的,它只是一句字符串,可以理解为一个命令,在关系型数据库上做任何操作,但考虑关系设计已经把复杂的事情简单化,SQL 无非就做这么几件事:
- 对库、表本身,以及表之间的关系进行定义
- 在一张表内增删改查
- 借助表间关系,一次性联合访问多张表中数据
- 访问一些基础的运算函数
总之这样一些拼起来,理论上你就能「只用一句SQL」为所欲为了。 了解更多:按我的知识水平,只能读 《菜鸟教程》
ORM 和 Sequlize
但 SQL 是远远不够的,因为字符串本身没有任何约束可言,你可能想查一个数据,结果一手抖打错把库删了,就只能跑路了。另外在代码里写一堆字符串着实丑陋。
所以出来一种叫 ORM 的东西,什么是 ORM 呢?字面上意思是::「对象关系映射」::,有点绕。
其实就是把数据库表映射成语言对象;然后暴露出一堆方法用来查库,ORM 负责把方法调用转成 SQL;因为表中的记录就是 key - value 形式,所以查询到的返回结果通常也是个对象,方便使用数据。这样对数据库访问的便捷性和稳定性都得到了提高。
方法 SQL
业务逻辑 <------> ORM <------> 数据库
数据对象 数据然而 ORM 只是一个解决方案。在右侧,不受数据库类型限制,只要是遵循 SQL 的关系型数据库都得到支持;在左侧,不受语言类型限制,各家都有相对成熟的实现方案,甚至会根据语言特性增加一些语言层面的优化支持。
在 nodejs 中,「Sequlizejs」可能是最出类拔萃的 ORM 实现。植根于 nodejs,Sequlizejs 完美支持 Promise 式调用,进一步你可以走 async/await,和业务代码紧密粘合;如果上了 ts,从模型定义带来的类型提醒能让调用更省心。
官方文档在这里:《Sequelize V5》
2 基础用法
表/模型的定义
前面提到,ORM 的第一步就是要建立对象到数据表的映射,在 Sequlize 里是这样的,比如我们关联一个 station 的表
const Model = sequlize.define('station', {
id: {
field: 'id',
type: Sequelize.INTEGER,
allowNull: false,
primaryKey: true,
autoIncrement: true,
},
store_id: Sequelize.STRING(20),
name: Sequelize.STRING(20),
type: Sequelize.TINYINT,
status: Sequelize.TINYINT,
ip: Sequelize.STRING(20),
plate_no: Sequelize.STRING(20),
related_work_order_id: Sequelize.BIGINT,
});
可见在定义过程中,数据类型是从 Sequelize 静态属性上引用的。这些类型能覆盖数据库里的类型,但命名并非对应的,具体参考:lib/data-types.js
你也可以通过 define 的第三个参数做一些自定义,这些配置会被合并到 Sequlize 构造函数的 define 字段中,用来定义模型和数据表的关联行为,比如「自动更新表中的 update_at、create_at」。参考 Model | Sequelize 中的 options
但是模型归模型,是给 ORM 用的,数据库里的表还是要自己去建的。通过客户端或如下这种建表 SQL:
CREATE TABLE `station` (
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`store_id` varchar(20) NOT NULL DEFAULT '',
`name` varchar(20) NOT NULL DEFAULT '',
`type` tinyint(4) NOT NULL DEFAULT '0',
`status` tinyint(4) NOT NULL DEFAULT '0',
`ip` varchar(20) NOT NULL DEFAULT '',
`related_work_order_id` bigint(20) NOT NULL DEFAULT '0',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`plate_no` varchar(20) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8 COMMENT='工位表';基础的CURD
Sequlize 对象提供丰富的 api,诸如:
- findOne、findAll……
- create、upsert……
- aggregate、max……
API 的调用应该不用赘述,文档 /lib/model.js~Model 里都安排的明明白白。这里主要看下当我们调用一个基础 api,Sequlize 转成了什么,对理解 ORM 和 SQL 的对应关系很有帮助。
一个例子:findAll
当没给 attributes,Sequelize 默认会把模型中的定义拿出来做 attributes,这样比 Select * 节约数据库操作成本和传输带宽。
最简单的,当我执行一个
Station.findAll()
Sequlize 转成的 SQL 是这样的
SELECT
`id`,
`store_id`,
`name`,
`type`,
`status`,
`ip`,
`plate_no`
FROM
`station` AS `station`;我们可以简单加一些条件:
Station.findAll({
attributes: [ 'ip' ],
where: {
status: 1,
},
order: [
[ 'name', 'ASC' ],
],
limit: 10,
offset: 5,
});
SQL 这样的(还是很清晰的)
SELECT `ip` FROM `station` AS `station` WHERE `station`.`status` = 1 ORDER BY `station`.`name` ASC LIMIT 5, 10;第二个例子:findOrCreate
有些高级 API 会::触发数据库事务::
事情通常不会这么简单,比如当我调
Station.findOrCreate({
where: {
id: 1,
},
defaults: {
name: 'haha',
},
});
你知道的,在一句 SQL 中是不能实现的,于是 sequlize 开了事务,做「查 -> 判断 -> 增」
START TRANSACTION;
SELECT `id`, `store_id`, `name`, `type`, `status`, `ip`, `plate_no` FROM `station` AS `station` WHERE `station`.`id` = 2;
INSERT INTO `station` (`id`,`name`) VALUES (2,`haha`);
COMMIT;3 联表查询
3.1 为什么要联表
前面我们有了个 Station 表,现在多了个 Car 表,通过 station_id 记录 Car 所在的 Station,那我要查 Station 列表以及它们包含的 Car 怎么办。
先 find Station,再用 where - station_id - in 查 Car,最后写逻辑遍历 Station 把 Car 挨个塞进去,是可行的。但一方面多一次查询会增加数据库资源消耗,另一方面自己也多了处理逻辑。
所以我们需要用到「关系型数据库」所擅长的「表间关系」,一次完成上述查询和数据合并。
3.2 联表关系
在 Sequlize 中,联表关系需要在模型 associate 方法中标记,通常为这种格式:
File.belongsTo(User, {...option});
查的时候用 include
File.findOne({
include: [{ model: User }],
});
同模型定义本身一样,这个标记不会对数据库进行任何操作,只是在 ORM 层建立模型之间的关系。这种关系会在我们调用联表查询时,转换成「JOIN」这样的联表 SQL 语句。
查的操作总是「include」,但是否标记以及采用哪个标记方法,决定了后面查询时是否可用联表查询,以及查询的 SQL 和查询结果的组织方式。
首先明确几个概念,在一个标记行为中
- 两种模型
- 源模型:需要标记和其他模型关系的模型,就是执行联表查询的模型 (上面的 File)
- 目标模型:被标记关系的模型,本身不因此次标记获得联表查询能力 (上面的 User)
- 四种关联键
- foreignKey:外键,用来关联外部模型,::一个模型有了外键,对关联的模型来说就是唯一了::
- targetKey
- sourceKey
- otherKey:当一个 foreignKey 不够用时的替代品
表之间的关系通常包括:一对一、一对多、多对多。
3.3 一对一关系(belongsTo / hasOne)
【误区】这里我之前有个误区,以为「一对一」是像夫妻关系一样「双向唯一」的,其实不然。我们的关系声明只能从源模型单向发起,也就是说「一对一」关系也是单向的,只能保证「源模型记录对应一条目标模型记录」,反过来不保证。
就像「儿子.hasOne(爸爸)」,不保证「爸爸」只有一个儿子。
一对一关系可用 belongsTo、hasOne 两种方式标记。
1 belongsTo
File(源模型)中有一个 creator_id标记自己::所属::的 User(目标模型)。这里 User 不见得只有一个 File,但一个 File 只能关联到一个 User 上。
File.BelongsTo(User, {
foreignKey: 'creator_id', // 如果不定义这个,也会自动定义为「目标模型名 + 目标模型主键名」即 user_id
targetKey: 'id', // 目标模型的关联键,默认主键,通常省略
});
// 这里 creator_id 位于源模型 File 上
2 hasOne
条件还是 File 模型中有一个 creator_id标记自己所属的 User。这时如果反过来把 User 当源模型,在 User 侧,假设一个 User 只有一个 File,我们要从 User 拿 File:
User.HasOne(File, {
foreignKey: 'creator_id', // 如果不定义这个,也会自动定义为「源模型名 + 源模型主键名」即 user_id
sourceKey: 'id', // 源模型的关联键,默认主键,通常省略
}
// 这里 creator_id 位于目标模型 File 上
hasOne 把 foreignKey 反转到源模型上,所以在 targetKey、sourceKey 用默认值的前提下(通常也是这样的),foreignKey 的位置可以决定用 BelongsTo 还是 HasOne 方便。
3 BelongsTo 和 HasOne
BelongsTo 和 HasOne 都可以定义「一对一」关系,借助三种 key 二者理论上可以互相替代。

事实上转换后的 SQL 也是一样的::LEFT JOIN::
# File.BelongsTo(User)
SELECT `FileClass`.`id`, `user`.`id` AS `user.id`
FROM `file` `FileClass`
LEFT JOIN `user` ON `FileClass`.`creator_id ` = `user`.`id`
# User.HasOne(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `但区别在「概念」层面,「属于」和「有一个」是两回事,哪个模型相对于另一个模型真的是「唯一归属」的,那么这个模型就该拥有一个 foreignKey。
3.4 一对多(hasMany)
::hasMany 可以理解为「多选版的 hasOne」,::和 hasOne 一样,这里要求::「目标模型」对「源模型」是唯一归属的::
还是上面的场景,File 模型中有一个 creator_id标记自己创建的 User。这里我们从 User 拿所有他创建的 File。
User.HasMany(File, {
foreignKey: 'creator_id', // 如果不定义这个,也会自动定义为「源模型名 + 源模型主键名」即 user_id
sourceKey: 'id', // 源模型的关联键,默认主键,通常省略
}
// 这里 creator_id 位于目标模型 File 上
和 hasOne 的深层区别
实际上::在 findAll 下,SQL 和「一对一」的一样::(也就是说 ORM 也无法限制 LEFT JOIN 进来的数量,所谓一对一只是「全 JOIN 进来选一个」)。
# User.HasMany(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `::findOne 就不同了::,如果你用 hasOne,SQL 只需要全局给个LIMIT 1,意味着「源模型和 JOIN 进来的目标模型我都只要一条」
# findOne: User.HasOne(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM `user` `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `
LIMIT 1;但如果你标记 hasMany,且用 findOne 查,是在说「源模型要一条,但要它关联的 N 条目标模型」。这时,全局给LIMIT 1就会把目标模型查询结果误杀到 1 个了,所以先 LIMIT 自身查询获得「源模型一条」,再 LEFT JOIN获得「它关联的 N 条目标模型」
# findOne: User.HasMany(File)
SELECT `UserClass`.`id`, `file`.`id` AS `file.id`
FROM (
SELECT `UserClass`.`id`,
FROM `user` `UserClass`
LIMIT 1
) `UserClass`
LEFT JOIN `file` ON `UserClass`.`id ` = `file`.`creator_id `3.5 多对多关系(belongsToMany)
有时候,::「目标模型」和「源模型」互不唯一::。一个 Group(文件夹)可能拥有多个 User,一个 User 也可能拥有多个 Group,这就直接导致::「给任何一个模型添加 foreignKey 都不合理」。::
我们需要「中间模型」做红娘,维护「目标模型」和「源模型」的关系。中间模型有两个 foreignKey(一个被 otherKey 代替),对「目标模型」和「源模型」都是唯一的。
User.BelongsToMany(Group, {
through: GroupUser, //
foreignKey: 'group_id', // 如果不定义这个,也会自动定义为「目标模型名 + 目标模型主键名」即 user_id
otherKey: 'user_id',
}
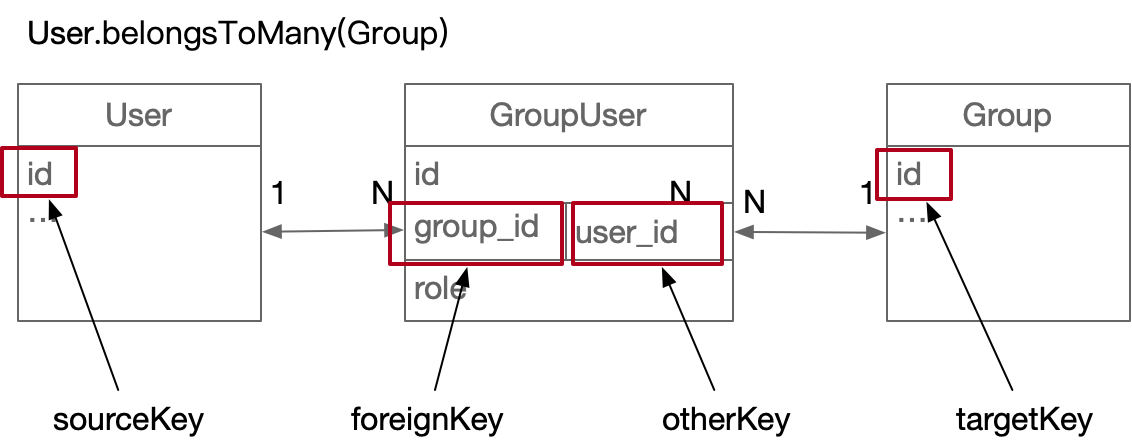
findOne 时,SQL 是这样的:先把 GroupUser INNER JOIN Group,再把结果LEFT JOIN到 User 上
# findOne(User): User.BelongsToMany(Group)
SELECT `UserClass`.`id`, `group`.`id` AS `group.id`
FROM (
SELECT `UserClass`.`id`,
FROM `user` `UserClass`
LIMIT 1
) `UserClass`
LEFT JOIN (`group_user` `group->GroupUser`
INNER JOIN `group` ON `group`.`id` = `group->GroupUser`.`group_id`)
ON `UserModel`.`id` = `group->GroupUser`.`user_id`;3.6 几种 JOIN
- left outer join(等价于 left join,因为默认是 outer):以左侧表行为准,合并并返回左侧出现的行;当没有右侧关联记录,返回行,右侧加进来的字段置空
- right join:和 left 相反,以右侧表行为准
- inner join:只有 join 时,左右都匹配到值才返回,相当于取交集
- full join:两侧任意一个匹配到就返回,相当于取并集
在 include 中,如果配置了required: true,SQL 就会从LEFT JOIN变为INNER JOIN,剔除没有关联记录的行
4 数据库查询的优化
前面提到的东西仅仅做到「能用」,事实上,业务查询场景很可能比较复杂,如果随意写,DBA 会打上门的。
4.1 慢查询、全表扫描和索引
在数据库界,人们常常提到「慢查询」,指的是查询时长超过指定时长的查询。慢查询的危害在于不仅本次查询的请求时间变长,还会较长时间的占用系统资源,对其他查询造成影响或者干脆撑挂数据库。
而「慢查询」最常见的罪魁祸首就是「全表扫描」,指的是数据库引擎为了找到某条记录,对全表进行逐个搜索,直到搜索到这条记录。想象下,如果你有上亿条数据,而要查的数据碰巧比较靠后,这个得查到什么时候?(复杂度在 O(n)) 那怎么样才不「全表扫描」呢?
举个例子,当你用主键查一条记录的时候,就不会全表扫描。
File.findByPk(123);
因为 MySQL 默认给主键列加了「索引」。
::「索引」厉害在哪?MySQL 为这一列建立了一个 btree::(不同数据库的实现是不一样的,但 btree 是主流)。这样查“id 为 318 的 Station”只需要从根节点沿着找下去,类似这个意思:
3xx --> 31x --> 3184.2 给其他列加索引
那么如果我查普通列呢?也可以通过索引提升查询效率。
File.findOne({
where: {
name: 'station1'
}
})
你也可以为这个列手动增加一个索引:
create index index_name on file(name);但这个索引的实现是和主键索引有区别的,它不直接查到数据记录,而是把 btree 建立在主键 id 上,现在查一个「name 为 station1 的记录」的过程变成类似这种:
开始
--> name: sta... --> name: statio --> name: station1
--> 拿到 station1 的 id: 816
--> id: 8xx --> id: 81x --> id: 816
--> 拿到 816 的数据如果嫌这个路径长,还有更近一步的,对于常查的列,比如 File 的 name 和 author,可以建立「覆盖索引」:
create index index_name_and_address on file(name, author);这时候如果我只根据 name 查 author:
File.findOne({
where: {
name: 'station1'
},
attributes: ['author']
})
因为索引里已经存了 address,就不需要再去访问源数据了:
开始
--> name: sta... --> name: statio --> name: station1
--> 拿到 station1 的 address: xxx索引越多越好吗?
然而索引并不是越多越好,索引虽然提升了查询的效率,缺牺牲了插入、删除的效率。想象下以前只要把新数据堆到表上就行,现在还要修改索引,更麻烦的是索引是个平衡树,很多场景需要对整个树进行调整。(主键为什么默认是自增的?我猜也是为了减少插入数据时树操作的成本)
所以我们一般考虑在常用来「where」或者「order」的列上加索引。
4.3 查询语句优化
前面说的给常用列增加索引可以提升查询效率,让查询尽量走「btree」而不是「全表扫描」。 但前提是别上来就 select *,而是要用 attributes 只摘取你要的列:
where: {
attributes: ['id', 'name']
}
但并不是所有的查询都会走「btree」,不优秀的 sql 仍然会触发全表扫描,产生慢查询,应该尽量避免。
当你 where 一个列时,MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。
放到 Sequelize 里就是:
Sequelize.Op.gt|gte|lt|lte|eq|between|in ...比如,能用 in 尽量别用 not in
// 不好
status: {
[Op.notIn]: [ 3, 4, 5, 6 ],
},
// 好
status: {
[Op.in]: [ 1, 2 ],
},
具体的网上一搜「避免全表扫描」一大把,就不展开了。
5 总结
- MySQL 通过 SQL 操作,ORM 基于业务编程语言进一步抽象操作,最终转为 SQL。Sequelize 是 node 上的一种 ORM
- 介绍了 Sequelize 的模型建立、查询语法
- 联表有三种关系,通过四种标记关联,讨论了这些关联中的概念、用法、原理、区别
- 索引对数据库优化意义很大,同时也要在语句上避免不走索引

















 3514
3514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









