







MaskTrack-RCNN《Video Instance Segmentation》论文解读
代码地址:
https://github.com/ youtubevos/MaskTrackRCNN
数据集地址:
https://competitions.codalab.org/competitions/2898
相似任务区别
| 任务 | 定义 | 区别 |
|---|---|---|
| VSS(Video Semantic Segmentation) | 在每一帧进行语义分割 | 没有考虑不同帧之间目标实例的匹配 |
| VOS (Video Object Segmentation) | 半监督:给定第一帧的mask,将目标从视频背景中分离出来 无监督:不需要给第一帧mask,不需要区分实例,只需要分分割出单个目标即可 | 没有考虑实例信息 |
| VOD (Video Object Detection) | 检测目标,但是不需要分割 | 没有分割和追踪 |
| VOT(video Object Tracking) | DBT(Detection-Based Tracking):在每一帧进行目标检测,再利用目标检测的结果来进行目标跟踪 DFT(Detection-Free Tracking):在第一帧给定初始框,无需检测器进行追踪 | 只进行检测,没有分割 |
要解决什么问题?
- 实例分割仅局限于图像领域,未扩展到视频领域。
- 没有合适的针对视频实例分割的数据集(无benchmark)。
- 相较于传统图像实例分割,视频实例分割要考虑在不同帧之间实例的追踪。
如何解决该问题?
- 提出了新的计算机视觉任务:视频实例分割VIS
目标是同时检测、分割和追踪视频中的实例。

- 提出了大规模基准数据集YouTube-VIS,包含2883个高分辨率YouTube视频,40个种类,131k个高质量实例掩码标注。
- 提出了新的算法MaskTrackRCNN,在Mask R-CNN的基础上添加追踪分支。预测的实例信息被保存在外部存储器中,之后会和其它帧的实例进行匹配。
具体实现细节?
(1) 首先定义任务VIS:
- 给定预定义类别集合C, K是种类数量
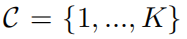
-
给定视频序列T帧,假设该视频序列有N个属于C的目标
-
对于每个物体i,ci表示其类别
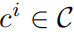
-
对于每个目标i,下式表示其在视频序列中的分割掩码,p属于[1,T],q属于[p,T],分别表示开始和结束时间
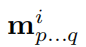
-
对于每一个视频序列,模型生成H个实例的预测信息,对于其中一个实例j,预测信息应包括:类别,置信度,掩码序列。(在最后生成预测结果时,p取第一帧,q取最后一一帧,如果某些帧该实例未存在,则该帧mask为NULL
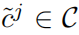
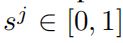
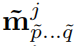
(2) 评测标准
使用AP和AR进行评测,但IOU的计算稍有不同,因为是针对一个视频序列进行评测,因此把某个实例GT的mask序列和预测的mask序列都扩展到从视频帧开始到结束的时间段,如果某一帧不存在,就padding为0。
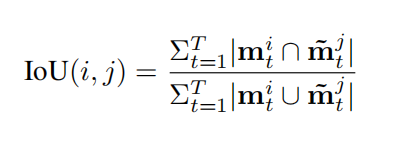
(3) YouTube-VIS
- 每个视频长度为3-6s,速度为30fps,每1s取5帧图像,也就是每个视频大约15-30张图像。
- 共4453个视频。
- 总共有40个种类,131k个实例标注。
- 在YouTube-VOS数据集的基础上采样并重新标注得到的。
(4) MaskTrack R-CNN算法
x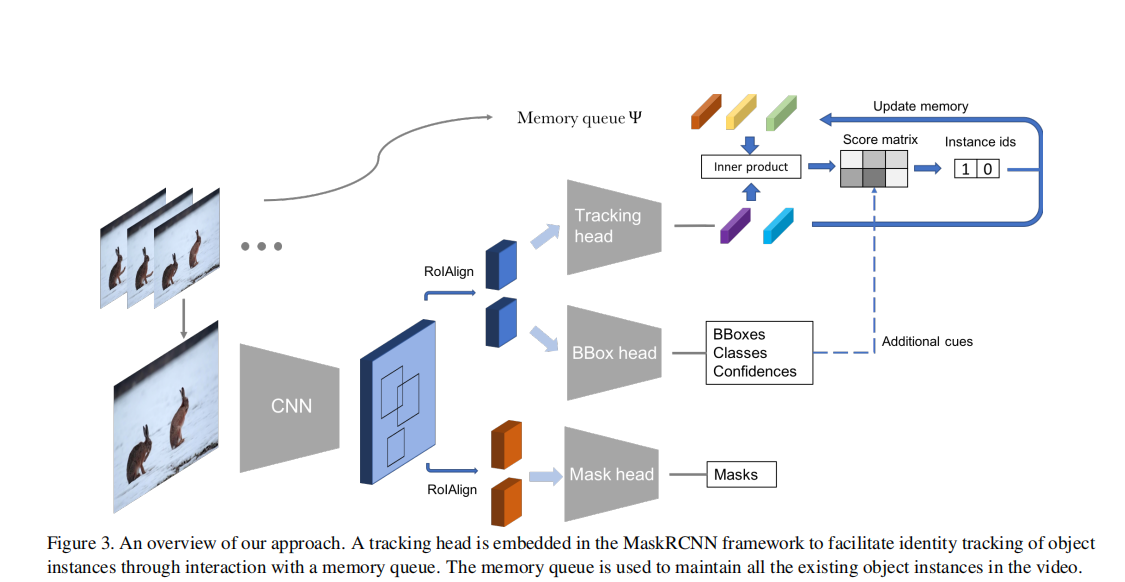
- 在Mask R-CNN原有的分类、回归和掩码生成分支上,增加了第四个分支,利用外部的存储空间(externel memory)来追踪不同帧之间的实例。追踪分支主要是利用物体的外观相似性(appearance similarity)来进行实例之间的匹配。同时,本文也提出了一种简单却有效的方法来结合其它线索,比如语义一致性(semantic consistency)和空间关联(spatial correlation)。
- 推理阶段使用的在线推理的方法(只知道当前帧前面帧的信息,而不知道后面帧的信息)。
- 追踪分支
目的:给每个候选框分配实例标签(给实例标一个序号,以区分不同实例)。
-
假设已经有了N个确认的实例,给新的候选框分配标签就只有两种可能
(a) 新的候选框就是N个实例之一
(b) 新的候选框是未曾出现的实例
-
从而将问题转化为:多标签分类问题(N+1类,N代表已经确认的实例,1代表未曾出现的实例,用数字0表示),将标签分配给候选框的概率可以定义为下式(衡量两个实例的相似度)
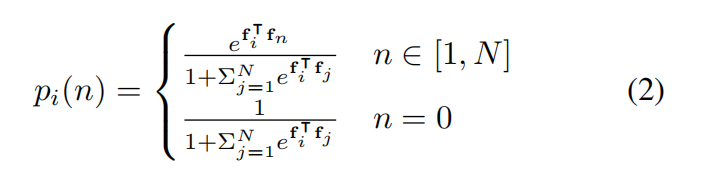
- 其中,fi代表新的候选框的特征,fj代表已经确认的N个候选框中第j个候选框的特征,它们都是一维向量(追踪分支用两层全连接层实现,输入是候选框的RoIAlign特征,输出是新的特征)。既然之前帧已经识别出的实例的特征已经经过计算,可以利用外部空间来存储其新特征提高效率。
- 当一个新的候选框被分配实例标签时,我们会动态更新外部空间(如果候选框已经属于某个存在的实例,我们会将memory中的该实例的特征更新,换成最新的)。
- 如果候选物体被分配为标签0,那么将他的特征嵌入memory中,并将所有已经识别出的实例标签增加1。loss
- 该分支的损失使用交叉熵损失,yi是GT

- 总体网络的损失:
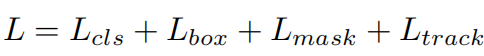
- 训练过程(训练追踪分支)
随机从一个视频中选取两帧,第一帧为参考帧,第二帧为查询帧
- reference frame 参考帧:不通过网络得到候选框,而是直接从GT的实例区域中提取特征,将他们保存到外部空间
- query frame 查询帧:在第一阶段产生候选框,将IOU大于70%的候选框作为正样本,送入追踪分支,进行实例匹配。
- 结合其它线索
仅用外观特征相似度来计算实例匹配是否不太够,那么能否结合其它视觉线索,比如语义一致性、空间关联和检测置信度共同作为匹配标准?
- 具体来说对于一个候选框i,bi、ci、si分别代表预测的bbox,class和score。bn、cn代表匹配的在外部空间中的实例的bbox和class,那么就可以定义分配分数(pi在上面有定义)
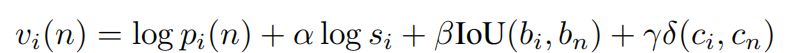
- 其中关于class的函数是一个脉冲函数,当类别相同时返回1,不同时返回0。
注意,分配分数只适用于在测试阶段,训练时仍只使用外观相似度
- 推理过程
- 给出一个新的视频,外部空间设为空,已经识别出的实例个数设置为0。我们的方法会以online的方式顺序的处理每一帧。每一帧会产生很多预测的实例,这些实例先经过NMS(阈值为0.5),然后经过过滤的预测框会和之前帧产生的实例进行匹配。
注意:为了防止歧义,匹配的实例是之前所有帧产生使的实例,而不仅仅是上一帧。
- 在预测第一帧时,其所有实例都会被送入memory中存储,对于我们的方法,一个标签可能会被分配给多个预测的实例,这个常识违背(一个视频中的每一个实例只能有一个),我们只保留得分最高的实例。
- 当处理完所有帧,会产生一系列实例的预测,每个预测包含要给独一无二的实例标签、一个视频序列的二值分割图像和列别标签和检测置信度。我们将检测置信度取平均值作为整个视频序列中该实例的置信度,使用投票法获得该实例的类别。
效果如何?
1. 数据集划分
| 集合 | 数量 | 性质 |
|---|---|---|
| 训练集 | 2238 | |
| 验证集 | 302 | 保证每个种类至少4个实例 |
| 测试集 | 343 | 保证每个种类至少4个实例 |
2. 参数:
- backbone:resnet-50-fpn(在coco上预训练)
- 跟踪分支:两个全连接层(第一层将77256的特征图→1024维向量,第二次将1024→1024)
- epochs:12
- lr:0.05 [8, 11](缩小10倍)
- 超参数:a:1,b:2,y:10
- 输入图像大小:640*360
3. 结果
在单块nvidia 1080ti上推理速度可以达到20FPS

4. badcase分析:

e:dear鹿在不同的姿势下其外形变换很大,算法将其视为两类不同的物体。
d:在水箱中有很多🐟移动,互相形成遮挡,算法在第二帧和第三帧将两个互相遮挡的🐟视为了同一条🐟,影响了后续的识别。
5. 消融实验:
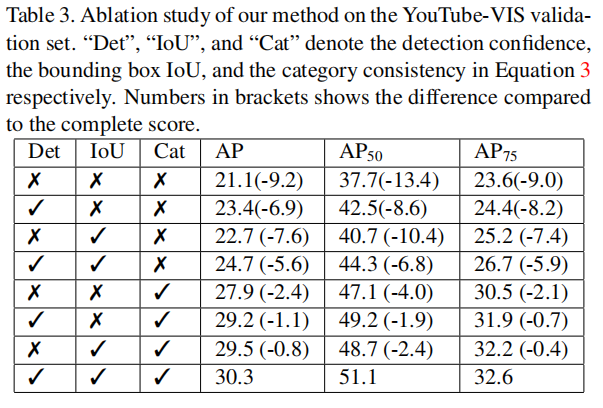
- 对不同视觉线索对该方法的影响做了消融实验,分别有:检测置信度,bbox的iou,类别一致性
实验发现,iou和类别一致性影响最大(❓但是,明明看实验结果iou影响不大)
- 解释:iou与空间联系有关,类别一致性提供了强有了的约束(一个视频序列中,一个实例的label应该不发生改变)。
- 但是,过度依赖这些视觉线索会造成错误的预测,因此我们旨在测试阶段将其作为软限制,而不在训练阶段使用他们。
总结
本文的贡献点主要在于提出了新的视觉任务。
















 2720
2720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









