







基于质谱的定量蛋白质组学已成为生物学研究的有力工具,而质谱本质上是不能用于蛋白质定量分析的,因为不同的蛋白质和多肽具有不同的离子化效率,而稳定同位素标记的氨基酸(如 2H(D),13C,15N 和 18O)引入蛋白质中可以很好的解决这个问题。
细胞培养中氨基酸的稳定同位素标记技术 (Stable isotope labeling by amino acids in cell culture, SILAC) 是基于质谱 (MS) 的定量蛋白质组学中一种简单、稳定而强大的方法。它于 2022 年被丹麦 Mann 实验室的 Ong 等人首次用于定量蛋白质组学,可提供准确的相对定量,无需任何化学衍生或者其它操作,广泛用于研究细胞生物学、生物化学、药物学等研究领域[1][2][3][4]。
下面就跟着 M 君先来探索下 SILAC 的技术原理及实验流程吧~
▐ SILAC 基本原理及流程
基于代谢将稳定同位素标记的氨基酸整合到整个蛋白质组中,两组细胞同时培养,一组是包含正常(轻)氨基酸(Light)的培养基培养(图 1a,左),另一组组则为同位素标记或者含有“重型(Heavy)”的氨基酸培养基(图 1a,右)。
细胞传代培养 5-6 代后,稳定同位素标记的氨基酸完全掺入到蛋白中,取代了原有的氨基酸,两个蛋白之间就存在分子量的改变,而无其它化学性质的差异。然后将两组细胞混合,提取出蛋白质后酶解,并用质谱(LC-MS/MS)检测分析[1]。
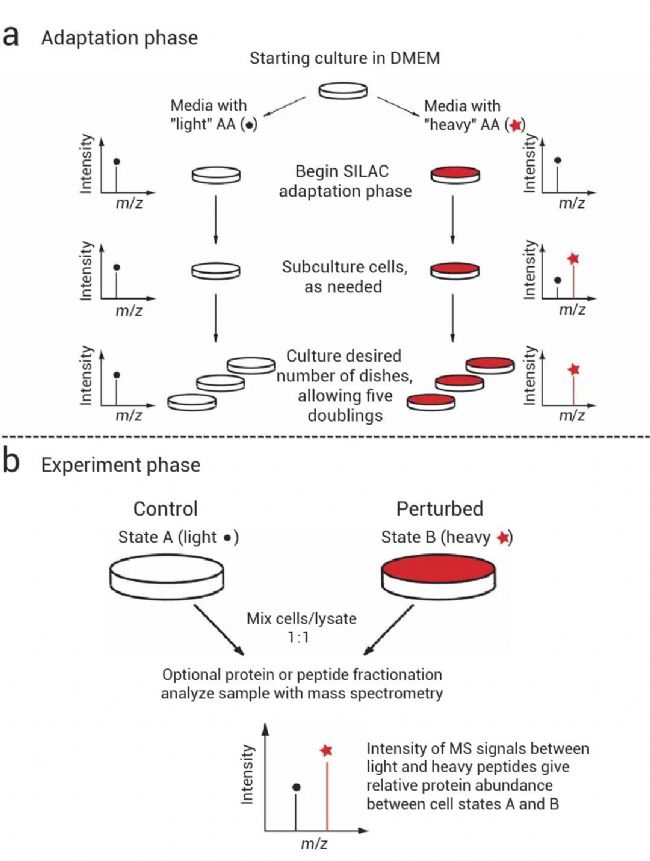
图 1. SILAC 实验概述[1]。
SILAC 实验包括两个不同的阶段 —— 适应 (a) 和实验 (b) 阶段。
(a) 在适应阶段,细胞在轻的和重的 SILAC 培养基中生长,直到重的细胞完全融入重的氨基酸 (红星)。这使得两个 SILAC 细胞池可以通过 MS 完全区分 (黑点和红星,分别表示轻和重 SILAC 肽),然后可以混合并作为一个样品处理。适应阶段可以包括细胞扩增以达到实验所需的皿数。
(b) 在第二阶段,两个细胞群被不同的处理,诱导蛋白质组的变化。混合样品,亚蛋白质组可通过富集步骤或其他分离纯化,消化成肽作为一个单一池,并通过 MS 进行蛋白质鉴定和定量分析[1]。
▐ SILAC 技术中同位素标记氨基酸的选择
理想情况下,SILAC 氨基酸应该是培养细胞存活所必需的氨基酸,从而确保特定氨基酸的唯一来源是培养基。亮氨酸[1][5]、赖氨酸和蛋氨酸是必需氨基酸,已被用于 SILAC[6][7]。
在早期的 SILAC 研究中,选择氘 (2H) 标记的亮氨酸作为标记氨基酸[1][5]。然而,氘标记的肽在反相色谱期间的层析位移影响了定量的准确性。后来使用了 13C 或15N 标记的氨基酸,因为这些 SILAC 肽对在 LC-MS/MS 分析中会发生共洗脱[3]。
虽然精氨酸 (R) 不是一种必需氨基酸,但它已被证明对许多培养的细胞系是必需的,并已成功用于 SILAC 标记。由于在后续的蛋白质谱分析之前,要先用胰蛋白酶 (Trypsin) 将蛋白“切割”成肽段,Trypsin 特异性地从蛋白质的赖氨酸 (K) 和精氨酸 (R) 残基处“切割”,最终超 95% 的肽段都是以 K 和 R 结尾,这也使其质谱定量信息更丰富,定量结果更精准。因此越来越多的研究者采用 13C 和15N 标记的精氨酸和赖氨酸的组合作为标记氨基酸[3]。
酪氨酸是另一种在 SILAC 中使用的非必需氨基酸。采用重标记酪氨酸鉴定酪氨酸激酶的底物,研究蛋白酪氨酸磷酸化的动态变化[8][9]。
常用的培养基中的轻重氨基酸列表如下:
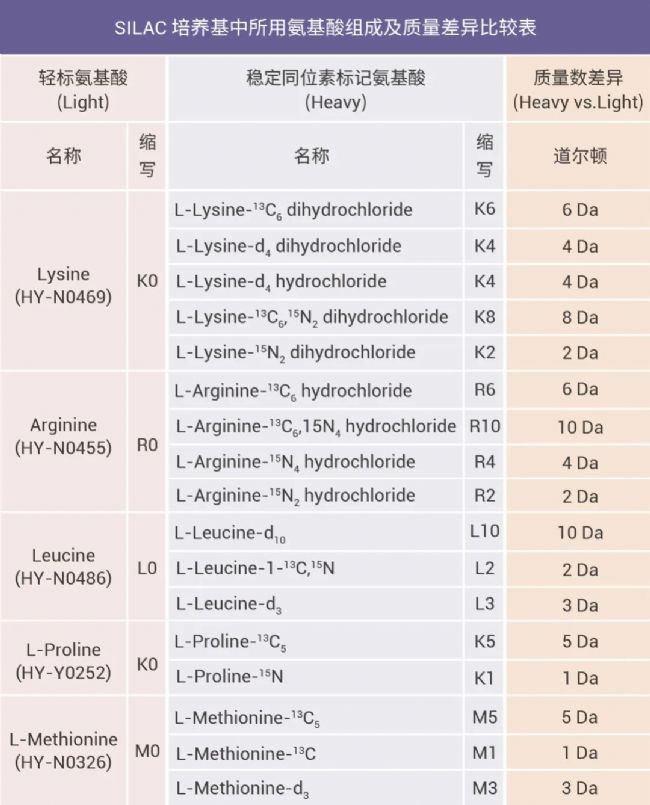
表 1. 常用的培养基中的轻重氨基酸。

基于 SILAC 的定量蛋白质组学可以用于鉴定外源性蛋白质-蛋白质相互作用 (Protein–protein interactions, PPIs)(图 2A)、内源性 PPls (图 2B)、或诱导型 PPls 中的特异性相互作用蛋白 (图 2C)[3]。
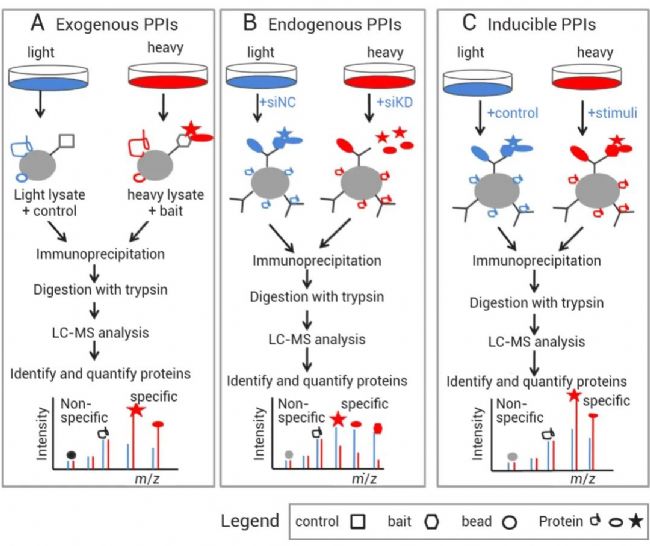
图 2. SILAC 定量相互作用蛋白质组学[3]。
研究外源蛋白复合物时 (图 2A),野生型细胞或表达亲和标签蛋白的细胞在轻或重的培养基中生长。然后从轻和重细胞裂解物的混合物纯化免疫亲和蛋白复合物[3]。
研究内源性蛋白复合物时 (图 2B),在轻或重培养基中生长的细胞中通过 RNAi 敲低所靶蛋白。然后用来自轻和重细胞裂解物混合物的相应抗体对蛋白质复合物进行免疫沉淀[3]。
在诱导型 PPls 的情况下 (图 2C),通过在轻或重培养基中生长的细胞中的特异性刺激来诱导蛋白质复合物,然后从轻和重细胞裂解物的混合物中免疫亲和纯化。获得蛋白质复合物后,将蛋白质消化成肽并用 LC-MS/MS 进行分析。特异性相互作用蛋白或非特异性背景蛋白可以通过它们的 SILAC 比率来区分[3]。
至此,同位素标记氨基酸与 SILAC 的亲密关系解密完成,此外,小 M 还整理了 SILAC 的技术优势 ,一起看看吧~

表 2. SILAC 技术优势。
总之,同位素标记氨基酸为 SILAC 的广泛应用奠定了很好的基础,同时也让同位素标记氨基酸与定量蛋白质之间的关系更加密不可分,你是否也想让你的实验设计更进一步呢?MCE 可为您提供一系列同位素标记氨基酸 ,助力您的科学研究!

| L-Lysine-13C6 dihydrochloride 人类必需的氨基酸。 |
| L-Arginine-13C6 hydrochloride 合成一氧化氮的氮供体,是血管扩张剂。 |
| L-Leucine-d10 一种必需的支链氨基酸。 |
| L-Proline-13C5 人体中二十种氨基酸之一,用于构建蛋白质。 |
| L-Methionine-13C5 一种必需氨基酸。 |
| L-Valine-d8 一种必需氨基酸。 |
| γ-Aminobutyric acid-d6 是成年哺乳动物大脑中主要的抑制性神经递质。 |
| L-Tryptophan-d5 一种必需氨基酸。 |
| 特级胎牛血清,乌拉圭 MCE 胎牛血清 (Fetal Bovine Serum) 来源于非疫区健康牛 (不含 BVDV、PI3、IBR、BTV 等牛源病毒),由剖腹产 6-8 月龄胎牛的血液制备而成,产地乌拉圭。 |
| MEM 非必需氨基酸溶液 (100×) MEM 非必需氨基酸溶液 (100×),是已经过滤除菌,可直接使用的常用细胞培养添加剂,其主要促进细胞生长和存活,减少体外细胞的生物合成负担。 |
| 青霉/链霉素双抗溶液 Penicillin-Streptomycin (100×), Sterile 是已过滤除菌,可直接用于细胞培养的双抗溶液。 |
| 抗生素-抗真菌素溶液 MCE Antibiotic-Antifungal (100 ×), Sterile 含青霉素(10 KU/mL)、链霉素(10 mg/mL)、两性霉素 B(25 μg/mL)。青霉素-链霉素可有效抑制多数革兰氏阳性菌和革兰氏阴性菌的生长,两性霉素 B 可用于抑制真菌、酵母的污染。 |
| 无血清/无蛋白细胞冻存液 MCE 无血清无蛋白细胞冻存液是一种非程序性即用型细胞冻存液。该产品既适用于常规哺乳动物细胞的冻存,也适用于无血清培养细胞的冻存。 |
MCE的所有产品仅用作科学研究或药证申报,我们不为任何个人用途提供产品和服务。
参考文献:
[1] Ong SE, et al. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics. Mol Cell Proteomics. 2002 May; 1(5):376-86.
[2] Krijgsveld J, et al. Metabolic labeling of C. elegans and D. melanogaster for quantitative proteomics. Nat Biotechnol. 2003 Aug; 21(8):927-31.
[3] Chen X, et al. Quantitative proteomics using SILAC: Principles, applications, and developments. Proteomics. 2015 Sep; 15(18):3175-92.
[4] Ong SE, et al. A practical recipe for stable isotope labeling by amino acids in cell culture (SILAC). Nat Protoc. 2006; 1(6):2650-60.
[5] Foster, et al. Unbiased quantitative proteomics of lipid rafts reveals high specificity for signaling factors. Proc. Natl. Acad. Sci. USA 2003, 100,5813–5818.
[6] Everley, et al. Quantitative cancer proteomics: stable isotope labeling with amino acids in cell culture (SILAC) as a tool for prostate cancer research. Mol. Cell Proteomics 2004, 3,729–735.
[7] Ong, et al. Identifying and quantifying in vivo methylation sites by heavy methyl SILAC. Nat.Methods 2004, 1, 119–126.
[8] Ibarrola, et al. A novel proteomic approach for specific identification of tyrosine kinase substrates using [13C] tyrosine. J. Biol. Chem. 2004,279, 15805–15813.
[9] Tzouros, et al., Development of a 5-plex SILAC method tuned for the quantitation of tyrosine phosphorylation dynamics. Mol. Cell Proteomics 2013, 12, 3339–3349.















 1184
1184











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









