







摘要
减少深度网络的激活位宽和网络的权重可以使它们高效地计算和存储在内存中,这在它们部署到移动设备等资源化设备上至关重要。然而,随着量化而减少的位宽通常会大大降低精度。为了解决这个问题,我们建议通过一个可训练的量化器来量化激活和离散它们。具体地说,我们参数化 quantization intervals(量化区间),并通过直接最小化网络的任务损失来获得其最优值。这种quantization-interval-learning量化区间学习(QIL)允许量化网络保持位宽低至4位的全精度(32位)网络的精度,并通过进一步降低位宽(即3位和2位)来最小化精度退化。此外,我们的量化器可以在异构数据集上进行训练,因此可以用于量化预先训练过的网络,而无需访问它们的训练数据。我们在ImageNet数据集上演示了我们的可训练量化器的有效性,如ResNet-18,-34和AlexNet,在这些网络架构上,它优于现有的方法,以达到最先进的精度。
1. 引言
- 我们提出了一种具有参数化区间的可训练量化器,它同时执行剪枝和剪切。
- 我们将我们的可训练量化器应用于深度网络的权值和激活,并以端到端方式对其进行优化和目标网络权值,以实现任务特定的损失。
- 我们的实验表明,我们的量化器在极低的位宽(2、3和4位)网络的ImageNet上达到了最先进的分类精度,并且即使在使用异构数据集进行训练和应用于预训练的网络时也能达到高性能。
我们提出了在训练过程中同时进行剪枝和剪切的可训练量化区间,并通过将该参数化应用于权值和激活量化,我们保持分类精度与全精度网络相同,同时显著降低了位宽。
3. 方法
可训练的量化区间在区间内有量化范围,修剪和剪辑范围在区间之外。我们将可训练的量化区间应用于激活和权重量化,并根据任务损失对其进行优化(图1)。在本节中,我们首先回顾和解释低位宽网络的量化过程,然后给出我们的具有量化区间的可训练量化器。
3.1.低位宽网络中的量化
对于全精度卷积神经网络(CNN)的第l层,权值Wl与输入激活Xl进行卷积,其中Wl和Xl是实值张量。我们分别用wl和xl表示Wl和Xl的元素。为了便于符号,我们将下标l去掉。减少位宽本质上涉及一个量化过程,其中我们通过量化器获得量化权值¯w∈¯W和量化输入激活¯x∈¯X,

在本文中,我们参数化量化器(变压器),使其可训练而不是固定。因此,这些量化器可以与神经网络模型的权值一起进行联合优化。我们可以得到最优的¯W和¯X,直接最小化整个网络的任务损失(即分类阳离子损失)(图1(b)),而不是简单地近似全精度的权重/激活,或者用 W ∗ X W*X W∗X ≈ \approx ≈ W ‾ \overline{W} W * X ‾ \overline{X} X卷积简单计算,其中,∗为卷积运算。
3.2.可训练的量化间隔
为了设计量化器,我们考虑了两种操作:剪切和剪枝(图1(a))。剪切的基本思想是限制量子化[27,4]的上界。减小上界可以增加上界内的量化分辨率,从而提高低位宽网络的精度。另一方面,如果上限设置得太低,精度可能会降低,因为会裁剪太多的值。因此,设置一个适当的剪切阈值对于保持网络的性能是至关重要的。剪枝删除低值权重参数[7]。增加剪枝阈值有助于提高量化分辨率,降低模型的复杂度,而将剪枝阈值设置得过高会导致性能下降,其原因与剪切方案造成的原因相同。
我们定义了量化区间来同时考虑剪枝和剪切。为了自动估计区间,每一层的区间分别由c∆和d∆(∆∈{W,X})参数化,其中c∆和d∆分别表示区间的中心和距离中心的距离。请注意,这只是一个设计选择,而其他类型的参数化,如具有下界和上界的参数化,也是可能的。让我们首先考虑权重的量化。因为权值同时包含正值和负值,所以量化器在正值和负边上都具有对称性。给定间隔参数cW和dW,我们对转换器TW的定义如下:


该量化器由可训练的区间参数cW、dW和 γ 设计。带有 γ 的非线性函数考虑了区间内的分布。图2中的图表显示了具有不同γ的转换器(蓝色虚线)及其相应的量化器(红色实线)。如果γ=为1,则变压器是一个分段线性函数,其中区间的内部值被均匀量化(图2(a))。通过调整 γ,可以对内部值进行非均匀量化(图2(b、c))。γ 可以设置为固定值,也可以经过训练。我们在实验中证明了γ的作用。如果γ
≠
\neq
= 1,则函数复杂。然而,权重量化器在训练后被删除,我们只使用量化的权值进行推理。因此,这个复杂的非线性函数根本不会降低推理速度。实际修剪阈值thp ∆和剪切阈值thc ∆随参数cW、dW和 γ 而变化,如图2所示。例如,γ=1情况下的thp ∆和thc ∆导出如下: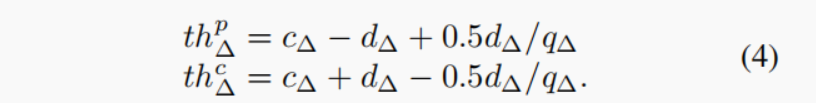
注意,权重的量化级别数qW可以计算为qW=2NW~−1^−1(一侧,0除外),给定位宽NW。因此,2位的权值实际上是三元的{−1,0,1}。
由于ReLU操作,输入到卷积层的激活是非负的。对于激活量化,将大于cX+dX的值裁剪并映射为1,我们将小于cX−dX的值修剪为0。中间的值被线性映射到[0,1],这意味着这些值在量化区间内被均匀地量化。与权重量化不同,激活量化应该在推理过程中在线进行,因此我们将γ固定为1以进行快速计算。然后,激活的转换器TX定义如下(图2(a)):

其中,αX=0.5/dX和βX=−0.5cX/dX+0.5。给定激活的位宽NX,量化级别qX(0除外)可以计算为qX=2NX−1;即,对于2位激活,量化值为{0、1、2、3}。
我们使用随机梯度下降来优化权值和量化器的参数。这些转换器是分段可微的,因此我们可以计算出相对于区间参数c∆,d∆和γ的梯度。我们使用直接估计器[2,27]计算离散化的梯度。
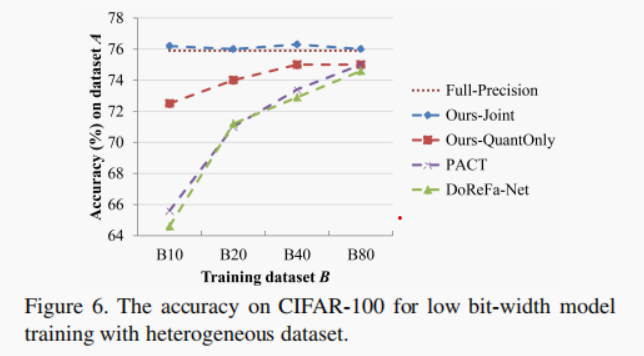
基本上,我们的方法与量化器联合训练权值参数。然而,也有可能在一个具有全精度权值的预先训练过的网络上训练量化器。令人惊讶的是,只训练量化器而没有更新权重也能产生相当好的精度,尽管其精度低于联合训练(见图6)。

4. 实验结果
4.1 ImageNet

初始化
具有良好的参数初始化性能,提高了训练后的低比特宽网络[17,19]的精度。为了实现良好的初始化,我们采用了一种微调的方法。在[17]中,它们逐步进行从高位宽到低位宽的量化,以获得更好的初始化。我们比较了全精度网络的直接微调结果与1位高位宽网络的逐步微调的结果(表2)。为了进行渐进式的微调,我们依次训练4/4、3/3和2/2位网络(即,2/2位网络的FP→5/5→4/4→3/3→2/2)。一般来说,渐进微调的精度高于直接微调。渐进微调对于2/2位网络(9.7%的点精度提高)至关重要,但对4/4和3/3位网络的影响很小(分别仅为0.2%和0.5%的点提高)。
联合训练vs仅量化
权重参数可以与量化参数共同进行优化或者我们只能优化量化器,同时保持权重参数不变。表3显示了ResNet-18网络在这两种情况下的top1个精度。这两种情况都利用了渐进式的微调。量化器和权值的联合训练比只训练量化器效果更好,这与我们的直觉是一致的。与仅训练量化器相比,联合训练在减少比特宽的同时表现出优雅的性能下降。然而,量化器在4位或更高的位宽时的精度是相当优秀的。例如,4/4位模型的精度下降仅为2.1%(70.1%→68.0%)。

修剪比例
为了看到我们的量化器的剪枝效果,我们计算剪枝比率,即零的个数占权值或激活总数的比例。图3显示了ResNet-18和AlexNet的整个网络的平均剪枝率。正如预期的那样,剪枝比随着位宽的减小而增加。当位宽高时,由于量化分辨率高,可以放宽量化区间。然而随着位宽减少,应该找到更紧凑的间隔来保持准确性,因此,剪枝比增加。对于2/2位网络,AlexNet和ResNet-18的权重平均分别为91%和81%被修剪(图3)。AlexNet比ResNet-18被修剪多,因为AlexNet有全连接层,参数比卷积层大18∼64倍,全连接层更有可能被修剪。激活受位宽的影响较小。图4为ResNet-18的区块级剪枝率。我们计算每个由两个卷积层和一个跳跃连接组成的ResBlock的修剪比。对于激活,上层更有可能被修剪,这可能是因为更多的抽象发生在更高的层。


训练 γ γ γ
对于权重量化,我们用γ(Eq.3)它考虑了区间内的分布。我们研究了训练γ的效果。表4显示了根据3/3和2/2位AlexNet的各种γ的top1个精度。我们报告了可训练的γ和固定的γ。对于3/3位模型,可训练γ不影响模型精度;即可训练γ为61.4%,γ=1为61.3%。然而,可训练的γ对于2/2位模型是有效的,与γ=1相比,前1的精度提高了0.9%,而固定的γ为0.5和0.75的精度与γ=1相似。固定的γ值为1.5 性能下降。

权重量化
为了证明我们的方法在权重量化上的有效性,我们只量化了权重,并保持了激活的全精度。我们测量了ResNet-18上具有不同位宽的权重的精度,并将其与现有的其他方法进行了比较(表6)。用我们的方法量化的网络的精度略高于使用第二优方法(LQ-Nets[26])。
权重和激活量的分布
图5显示了不同时期的权重和激活量的分布。由于我们同时训练权值和量化器,因此权值和量化区间的分布在训练过程中发生了变化。请注意,权重分布的峰值出现在每个量化值的过渡处。如果目标是最小化量化误差,那么这种分布是不可取的。由于我们的目标是最小化任务损失,在训练过程中,只有当量化水平不同时,损失才变会不同。因此,权重值向过渡边界移动。我们还绘制了具有修剪和剪切阈值的激活分布。(图5:(d))。

4.2 CIFAR-100
在本实验中,我们从一个没有原始训练数据集的预先训练好的全精度网络中训练一个低位宽网络。本实验的目的是为了验证在没有给出原始训练数据集时,是否有可能训练低位宽模型。为了演示这个场景,我们使用了CIFAR-100[14],它由100个类组成,每个类包含500个训练图像和100个验证图像,其中100个类被分成20个超类(每个超类有5个类)。我们将数据集划分为两个不相交的组A(4个超类,20个类)和B(16个超类,80个类),其中A是原始训练集,B作为异构数据集用于训练低位宽模型(本实验中为4/4位模型)。B进一步分为4个子集B10、B20、B40和B80(B10⊂B20⊂B40⊂B80=B),分别为10、20、40和80类。
5.结论
提出了一种具有参数化量化区间的可训练量化器来训练低比特宽网络。我们的可训练量化器对权重和激活同时进行修剪和剪切,同时通过学习适当的量化间隔来保持全精度网络的准确性。我们没有像之前的工作那样,最小化与全精度网络的权值/激活相关的量化误差,而是通过直接最小化任务损失来联合训练量化参数和权值。因此,我们在大规模的ImageNet分类数据集上取得了非常有希望的结果。使用我们的方法获得的4位网络保持了具有各种体系结构的全精度网络的精度,3位网络产生的精度与全精度网络相当,而2位网络的精度损失最小。我们的量化器也实现了良好的量化性能,即使在异构数据集上进行训练时也优于现有的方法,这使得它在预训练网络没有访问原始训练数据的情况下非常实用。未来的工作可能包括用分段线性函数更精确的参数化量化区间和使用贝叶斯方法。















 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









