







🏡 个人主页:IT贫道-CSDN博客
🚩 私聊博主:私聊博主加WX好友,获取更多资料哦~
🔔 博主个人B栈地址:豹哥教你学编程的个人空间-豹哥教你学编程个人主页-哔哩哔哩视频
目录
3.1 下载“Bringing-Old-Photos-Back-to-Life”项目
1. AI老照片修复原理-VAE
1.1 自编码器模型
自编码器模型基本思路很容易理解:把一堆真实样本通过编码器网络变换成一个理想的数据分布,然后这个数据分布在传递给一个解码器网络,得到一堆生成样本,生成样本与真实样本足够接近的话,就训练出来一个自编码器模型。
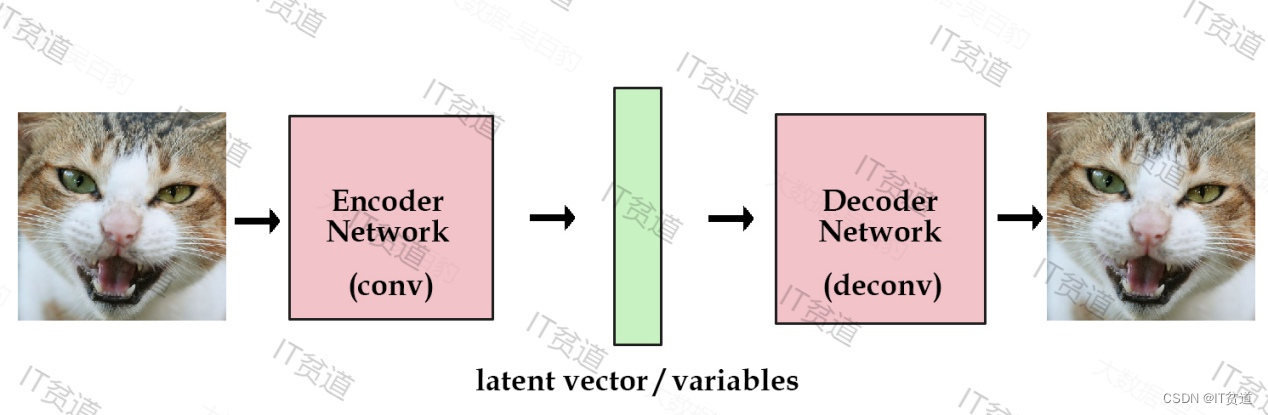

如图,X本身是一个矩阵,通过一个变换W变成了一个低维矩阵c,因为这一过程是线性的,所以再通过一个WT变换就能还原出一个,现在我们要找到一种变换W,使得矩阵X与X帽子 能够尽可能地一致,这大致可以理解为编码解码的原理。
一般我们在训练模型时都会使用神经网络来进行多层编码转换,这种模型叫做Deep Auto-Encoder模型,如下图:
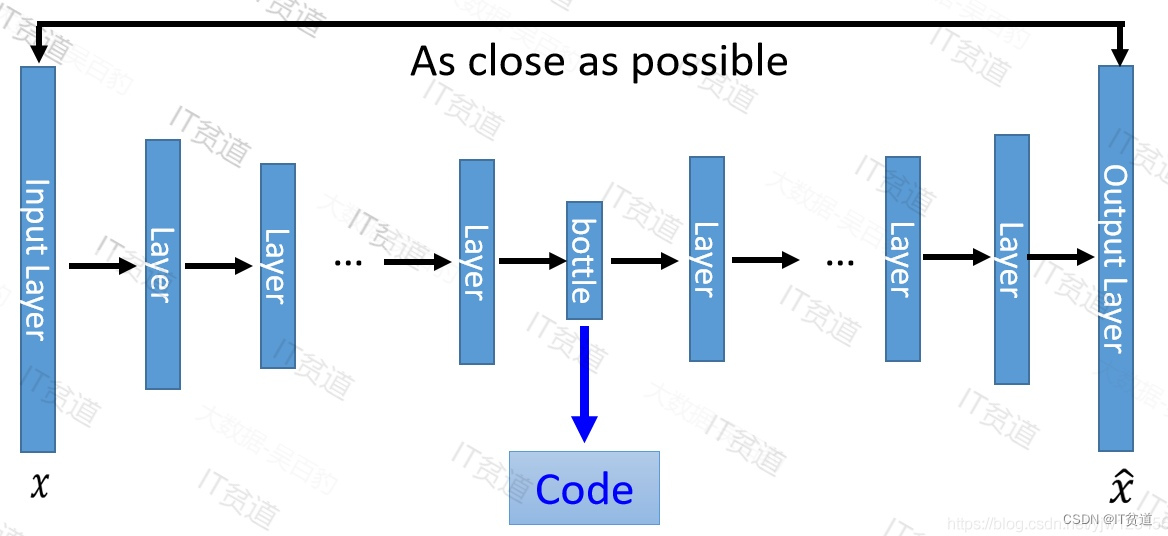
这一替换的明显好处是,引入了神经网络强大的拟合能力,使得编码(Code)的维度能够比原始图像(X)的维度低非常多。在一个手写数字图像的生成模型中,Deep Auto-Encoder能够把一个784维的向量(28*28图像)压缩到只有30维,并且解码回的图像具备清楚的辨认度(如下图)
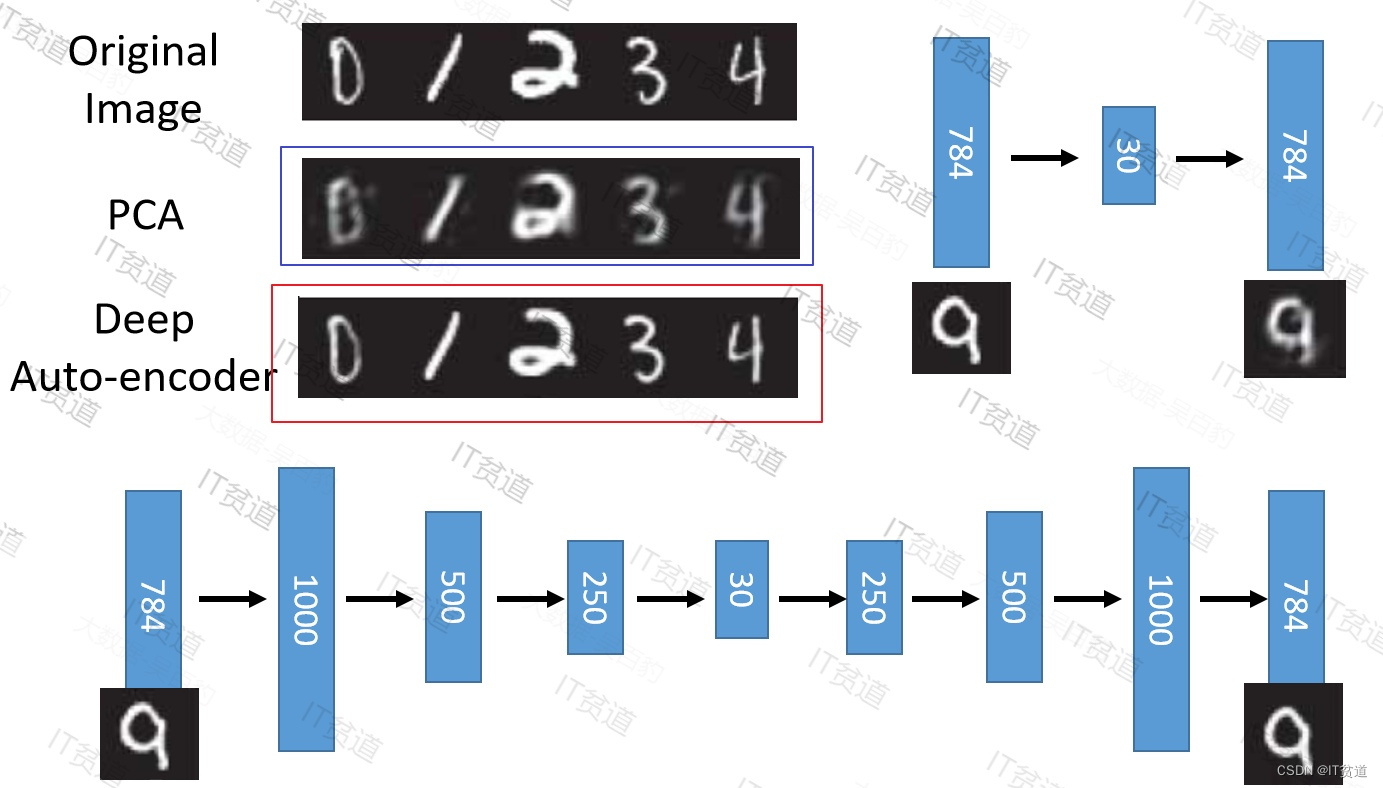
至此我们构造出了一个重构图像比较清晰的自编码模型。简单来说,AI就是一个擅长总结和“学习”的高级算法,比如,人类只需要为AI同学提供大量同类型图片,看得足够多,量足够大,AI就能从其中得出一个基本算法公式,再举一反三,根据不同的图像上已知的点,算出周围若干点的位置。人脸识别道理也是一样。

当我们"喂"给AI模型一张它从没有在训练中处理过的且有很大缺陷的图片,AI模型可能会失控并且产生不可用的结果,可能不能正确分类图片。解决这种问题就需要在训练模型时加入缺陷图片,增大训练集,以防止使用模型时应对各种情况。
那么假设现在我们需要一种模型,这种模型能在一堆图片中给我们识别出哪些图像是清洗的,哪些图像不是清晰的,那么我们要按照以上方式来构建模型的话,几乎不可能,因为我们不可能将每张图片清洗到模糊的情况都准备出来,就算准备出来,所以无法使用以上自编码器模型实现清晰图像和非清晰图像的区分。
1.2 变分自编码器模型VAE原理
自编码器模型可以根据很多图像来训练模型,如果保存了某张图像的编码向量,我们随时就能用解码组件来重建该图像,这个过程仅需要一个自编码器模型即可。那么假设我们现在要的是一个生成式模型,而非仅仅是“记忆”图像数据的模糊结构,除了像前面那样从已有图像中编码出潜在的向量,我们还不知道如何创造这些向量,也就无法凭空生成任何图像,可以通过VAE模型来生成不同的图像。
VAE (Variational autoencoder)就是在自编码器模型上做进一步的变分处理,使得编码器的输出结果能对应到目标分布的均值和方差,如下图所示:
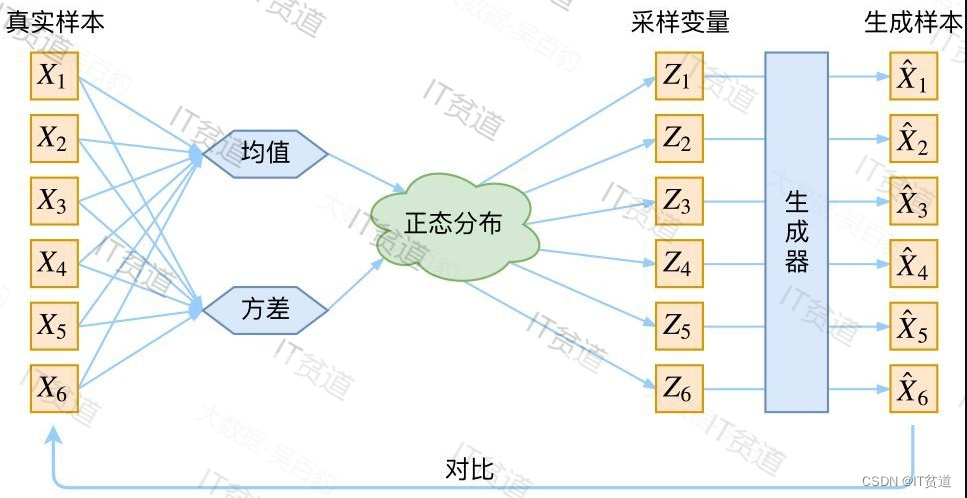
VAE最想解决的问题是什么?当然是如何构造编码器和解码器,使得图片能够编码成易于表示的形态,并且这一形态能够尽可能无损地解码回原真实图像。
举个例子:假设我们需要构建一个模型需要判断月亮是大于半月还是小于半月,但是现在的问题是我们手上有很少的数据,只有初一和十五的月亮图片,如下图:

如果使用以上数据来训练分类模型,模型只能区分以上两种月亮类型,那么如果未来有一张如下的月亮图形,就有可能不能正常分类:

那么我们可以通过VAE根据最初的两类数据来搞出一些数据来,模拟出从初一到三十每天的月亮情况。如下:

假设月亮的样子是由南北半球和每个月的日期这两个因素所决定的,假设这些因素服从正态分布(当然这里这两个因素不服从正态分布),那么我们的任务就是通过初一和十五这两个数据(当然实际上要更过一些)用VAE来训练处这些正态分布的均值和方差,如南北半球的维度和每个月的日期。训练的目标就是假设初一和十五的月亮的影响因素也是服从这个正态分布的,那么通过这个分布一样可以还原出初一到十五的月亮。
我们先来分析一下现有标准自编码模型无法达到这一标准的原因。
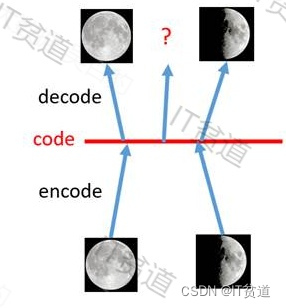
如上图所示,假设有两张训练图片,一张是全月图,一张是半月图,经过训练我们的自编码器模型已经能无损地还原这两张图片。接下来,我们在code空间上,两张图片的编码点中间处取一点,然后将这一点交给解码器,我们希望新的生成图片是一张清晰的图片(类似3/4全月的样子)。但是,实际的结果是,生成图片是模糊且无法辨认的乱码图。一个比较合理的解释是,因为编码和解码的过程使用了深度神经网络,这是一个非线性的变换过程,所以在code空间上点与点之间的迁移是非常没有规律的。
如何解决这个问题呢?我们可以引入噪声,使得图片的编码区域得到扩大,从而掩盖掉失真的空白编码点。

如上图所示,现在在给两张图片编码的时候加上一点噪音,使得每张图片的编码点出现在绿色箭头所示范围内,于是在训练模型的时候,绿色箭头范围内的点都有可能被采样到,这样解码器在训练时会把绿色范围内的点都尽可能还原成和原图相似的图片。然后我们可以关注之前那个失真点,现在它处于全月图和半月图编码的交界上,于是解码器希望它既要尽量相似于全月图,又要尽量相似于半月图,于是它的还原结果就是两种图的折中(3/4全月图)。
由此我们发现,给编码器增添一些噪音,可以有效覆盖失真区域。不过这还并不充分,因为在上图的距离训练区域很远的黄色点处,它依然不会被覆盖到,仍是个失真点。为了解决这个问题,我们可以试图把噪音无限拉长,使得对于每一个样本,它的编码会覆盖整个编码空间,不过我们得保证,在原编码附近编码的概率最高,离原编码点越远,编码概率越低。在这种情况下,图像的编码就由原先离散的编码点变成了一条连续的编码分布曲线,如下图所示。

那么上述的这种将图像编码由离散变为连续的方法,就是变分自编码的核心思想。

1.3 VAE与GAN的对比
VAE相比GAN的优势在于,GAN是implicit density,意思是它对潜变量的分布隐式建模,整个GAN训练完后我们是不知道潜变量具体分布是怎么样的,也就无法随心所欲生成想要的图片,我们只能任意的输入一个噪声,然后网络的生成数据看起来像训练数据集中的数据。但是VAE是explict density,它对潜变量的分布显式建模,我们训练完VAE后是可以得到潜变量的具体分布的,因此也就可以指定生成的数据的样子。
VAE相比GAN的劣势在于,它没有GAN那样的判别器,所以最后生成的数据会比较模糊(以图片数据为例)。当然也有结合VAE和GAN的工作。
2. AI老照片修复基础环境准备
2.1 安装Anconda3
Anaconda是一个开源的Python发行版本,python是一个编译器,如果不使用Anaconda那么安装起来会比较痛苦,各个库之间的依赖性就很难连接的很好。Anaconda可以看做Python的一个集成安装,里面集成了很多关于python科学计算的第三方库,安装它后就默认安装了python、IPython、集成开发环境Spyder和众多的包和模块,包含了conda(conda 是开源包(packages)和虚拟环境(environment)的管理系统。)、Python等180多个科学包及其依赖项。因为包含了大量的科学包,Anaconda 的下载文件比较大,大概几百兆左右,如果只需要某些包,或者需要节省带宽或存储空间,也可以使用Miniconda这个较小的发行版(仅包含conda和 Python)。
我们可以从Anaconda官网 Anaconda | The World’s Most Popular Data Science Platform 下载Anaconda,一般官网下载比较慢,可以选择使用镜像下载,地址如下:
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
现在之后直接双击安装即可,注意安装路径中不要有中文和空格。安装完成之后,配置环境变量,如下图:
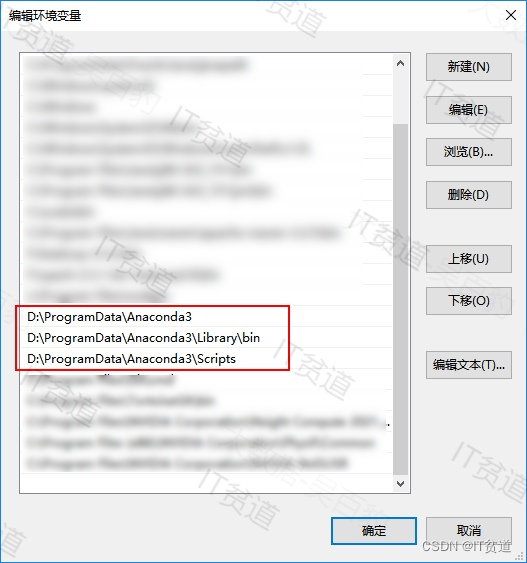
配置完成之后,打开CMD命令窗口输入:conda,验证是否安装成功:

2.2 安装Python3
基于Anconda安装Python3,这里安装python使用至少python3.7版本。命令如下:
#安装python环境
conda create --name python37_face python=3.7
#卸载python环境
conda remove --name python37_face --all2.3 安装CUDA
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU(图形处理器)能够解决复杂的计算问题。
在Window中安装CUDA,可以进入网址:
CUDA Toolkit 12.3 Update 2 Downloads | NVIDIA Developer

也可以从这里下载:链接:https://pan.baidu.com/s/1VqzN4hgOHanP_gGYOgTG9g?pwd=8888
提取码:8888
下载后直接双击exe文件安装即可。默认安装在了C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3,也可以指定路径安装。




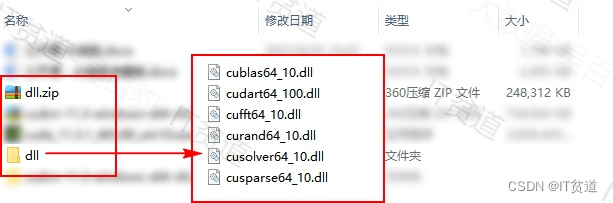
另外,可能某些电脑环境问题,安装CUDA时缺少dll库,不能自动准备dll文件,那么我们将下载好的dll目录中的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin 目录下(这里下载dl:https://download.csdn.net/download/qq_32020645/88714133)。这样后期GPU能正常工作。下载解压后的dll文件如下:
2.4 安装CUDNN
NVIDIA CUDNN是用于深度神经网络的GPU加速库。它强调性能、易用性和低内存开销。NVIDIA CUDNN可以集成到更高级别的机器学习框架中,如谷歌的Tensorflow、加州大学伯克利分校的流行caffe软件。简单的插入式设计可以让开发人员专注于设计和实现神经网络模型,而不是简单调整性能,同时还可以在GPU上实现高性能现代并行计算。
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。CUDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作的工具,比如它就是个扳手。但是CUDA这个工作台买来的时候,并没有送扳手。想要在CUDA上运行深度神经网络,就要安装CUDNN,就像你想要拧个螺帽就要把扳手买回来。这样才能使GPU进行深度神经网络的工作,工作速度相较CPU快很多。
在https://developer.nvidia.com/zh-cn/cudnn网站中下载CUDNN,可能需要科学上网需要注册后,需要填写问卷才能下载,这里需要与CUDA版本对应关系。也可以从这里下载:链接:https://pan.baidu.com/s/1vVKPMWe0AYFzBbzCjBGurg?pwd=8888
提取码:8888
下载完成之后解压,进入解压目录,如下图:
找到CUDA的安装目录,替换对应目录里面对应的文件即可:
- bin文件夹里面有一个文件需要替换。
- include文件夹里面有一个文件需要替换。
- lib文件夹里面有个x64文件夹中有一个文件需要替换。
3. AI老照片修复步骤
3.1 下载“Bringing-Old-Photos-Back-to-Life”项目
项目下载地址:
https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life
下载后解压到没有中文路径,这里解压路径为J:\Bringing-Old-Photos-Back-to-Life-master。
3.2 下载项目依赖
项目需要一些依赖的文件,下载地址:
下载的文件名称为:Synchronized-BatchNorm-PyTorch-master.zip。(也可以从这里下载:链接:https://pan.baidu.com/s/1-BnABnKORAE1tUsDzg_xqw?pwd=8888
提取码:8888)将下载后的文件解压,将解压目录中的“sync_batchnorm”目录整个拷贝到“J:\Bringing-Old-Photos-Back-to-Life-master\Face_Enhancement\models\networks”目录下和“J:\Bringing-Old-Photos-Back-to-Life-master\Global\detection_models”目录下。
3.3 下载人脸识别模型
这里下载的就是人脸识别模型,是别人训练好的模型,大小为61M。下载地址:
http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
下载好的文件名称为:“shape_predictor_68_face_landmarks.dat.bz2”(也可从这里下载:链接:https://pan.baidu.com/s/1ijg8MGrf5zL_IYwruGlUBA?pwd=8888
提取码:8888),下载完成后把里面文件“shape_predictor_68_face_landmarks.dat”放入“J:\Bringing-Old-Photos-Back-to-Life-master\Face_Detection”路径下。
3.4 下载预训练模型
预训练好的模型有2个,第一个下载地址:https://facevc.blob.core.windows.net/zhanbo/old_photo/pretrain/Face_Enhancement/checkpoints.zip
下载完成后,对应的文件名称“checkpoints.zip”(326M),(也可从这里下载:链接:https://pan.baidu.com/s/1Mz9iQUw2SaPvvqUy7nhfOQ?pwd=8888
提取码:8888)解压,将“checkpoints”这个目录拷贝到“J:\Bringing-Old-Photos-Back-to-Life-master\Face_Enhancement”目录下。

第二个下载地址:
https://facevc.blob.core.windows.net/zhanbo/old_photo/pretrain/Global/checkpoints.zip,下载完成后,对应的文件名称“checkpoints.zip”(1.61G),(也可从这里下载:链接:https://pan.baidu.com/s/1_YducU9TeJE3efpfeLV2qw?pwd=8888
提取码:8888)解压,将“checkpoints”这个目录拷贝到“J:\Bringing-Old-Photos-Back-to-Life-master\Global”目录下。
3.5 安装需要python依赖包
进入D:\ProgramData\Anaconda3\envs\python36_oldimage\Scripts,安装需要的python依赖包。
安装python包中torch、torchvision、torchaudio需要自己在pytorch官网下载,这个关于此项目能否正常使用GPU。如果直接pip install 安装对应的包后期会报错。可以在pytorch官网找到正确pip安装的方式:pip3 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html ,涉及到的torch 大概3G多,下载非常慢,所以手动下载whl文件安装最好,手动下载依赖包地址:https://download.pytorch.org/whl/torch_stable.html,下载好的文件名称如下(这里也可下载:链接:https://pan.baidu.com/s/1ypyS40kc8OFLY50J4Jxxnw?pwd=8888
提取码:8888):
torch-1.9.0+cu111-cp36-cp36m-win_amd64.whl
torchvision-0.10.0+cu111-cp36-cp36m-win_amd64.whl
torchaudio-0.9.0-cp36-cp36m-win_amd64.whl使用pip命令安装以上包需要按照顺序安装,安装命令如下:
pip install torch-1.9.0+cu111-cp36-cp36m-win_amd64.whl
pip install torchvision-0.10.0+cu111-cp36-cp36m-win_amd64.whl
pip install torchaudio-0.9.0-cp36-cp36m-win_amd64.whl除了以上pytorch相关包下载非常难之外,还有一个包需要手动下载:dlib,这个pip安装问题不大,但是pip安装时会检测环境导致缺其他包安装不成功。所以这里也手动下载,python3.6对应下载地址:
https://pypi.org/packages/da/06/bd3e241c4eb0a662914b3b4875fc52dd176a9db0d4a2c915ac2ad8800e9e/dlib-19.7.0-cp36-cp36m-win_amd64.whl#md5=b7330a5b2d46420343fbed5df69e6a3f
python3.7对应下载地址:
https://github.com/daiera/some_resources/blob/master/dlib-19.17.0-cp37-cp37m-win_amd64.whl
同样,下载完成之后,直接pip安装即可:
pip install dlib-19.17.0-cp36-cp36m-win_amd64.whl除了以上包之外,还需要安装python的包如下,直接pip安装即可。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-image
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple easydict
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyYAML
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple dominate>=2.3.1
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple dill
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple tensorboardX
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scipy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple einops
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PySimpleGUI3.6 照片修复
准备老照片路径:
“J:\Bringing-Old-Photos-Back-to-Life-master\old-image”
准备修复后的路径:
“J:\Bringing-Old-Photos-Back-to-Life-master\repair-image”
执行如下步骤修复照片:
1) 切换python36环境
在“J:\Bringing-Old-Photos-Back-to-Life-master”路径下右键打开命令行,执行如下命令切换python36_oldimage python环境
conda activate python36_oldimage2) 启动程序修复图片
在打开的cmd窗口中执行如下命令:
python J:\Bringing-Old-Photos-Back-to-Life-master\run.py --input_folder J:\Bringing-Old-Photos-Back-to-Life-master\old-image --output_folder J:\Bringing-Old-Photos-Back-to-Life-master\repair-image --GPU 0如果照片中有褶皱,那么可以在命令最后执行 --with_scratch参数,命令如下:
python J:\Bringing-Old-Photos-Back-to-Life-master\run.py --input_folder J:\Bringing-Old-Photos-Back-to-Life-master\old-image --output_folder J:\Bringing-Old-Photos-Back-to-Life-master\repair-image --GPU 0 --with_scratch

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











