








矩阵乘法通过缓存命中率提升运算效率
import numpy as np
n = 512
a = np.full([n,n],1,dtype='int32')
a
b = np.full([n,n],2,dtype='int32')
b
c = np.random.randint(0,5,[n,n])
c
%%timeit
for i in range(0,a.shape[0]):
for j in range(0,b.shape[1]):
for k in range(0,a.shape[1]):
if k == 0:
c[i,j] = 0
c[i,j] += a[i,k]*b[k,j]
%%timeit
for i in range(0,a.shape[0]):
for k in range(0,a.shape[1]):
for j in range(0,b.shape[1]):
if k == 0:
c[i,j] = 0
c[i,j] += a[i,k]*b[k,j] 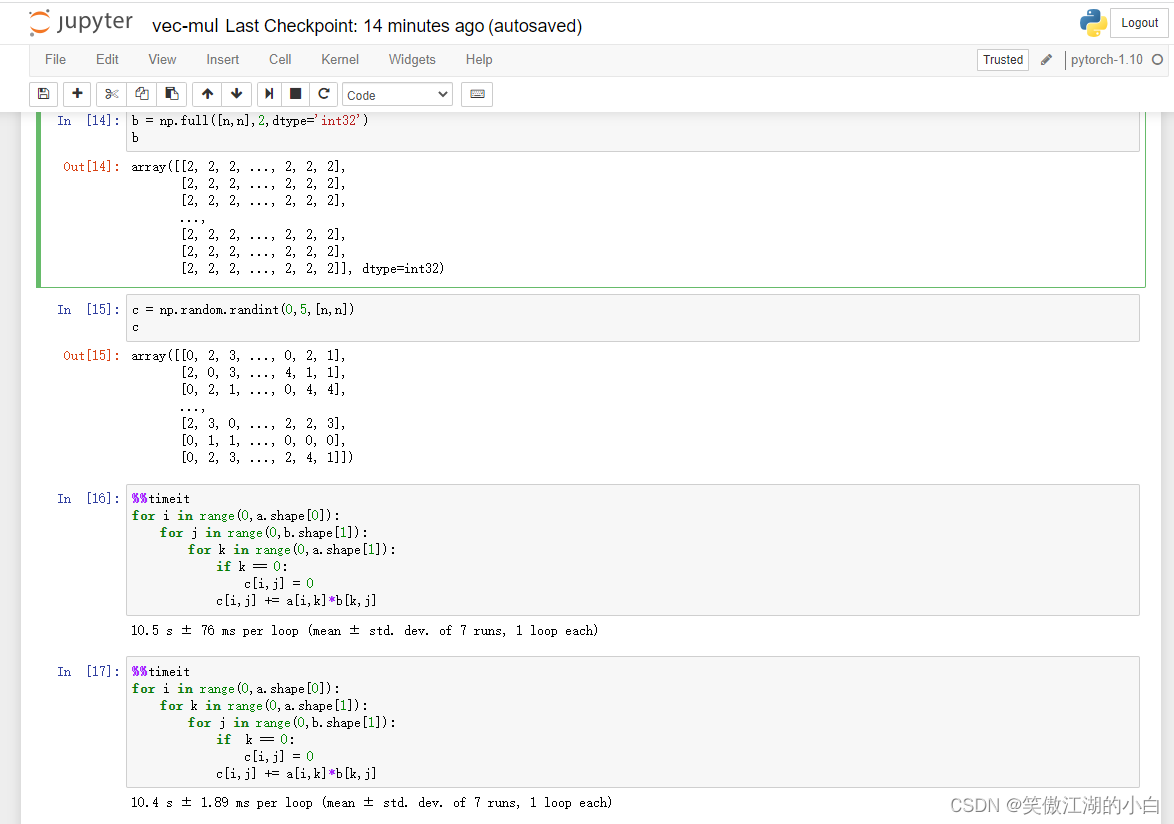
测试环境为:ubuntu 18.04
CPU MHz: 800.682
CPU max MHz: 2101.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 11264K
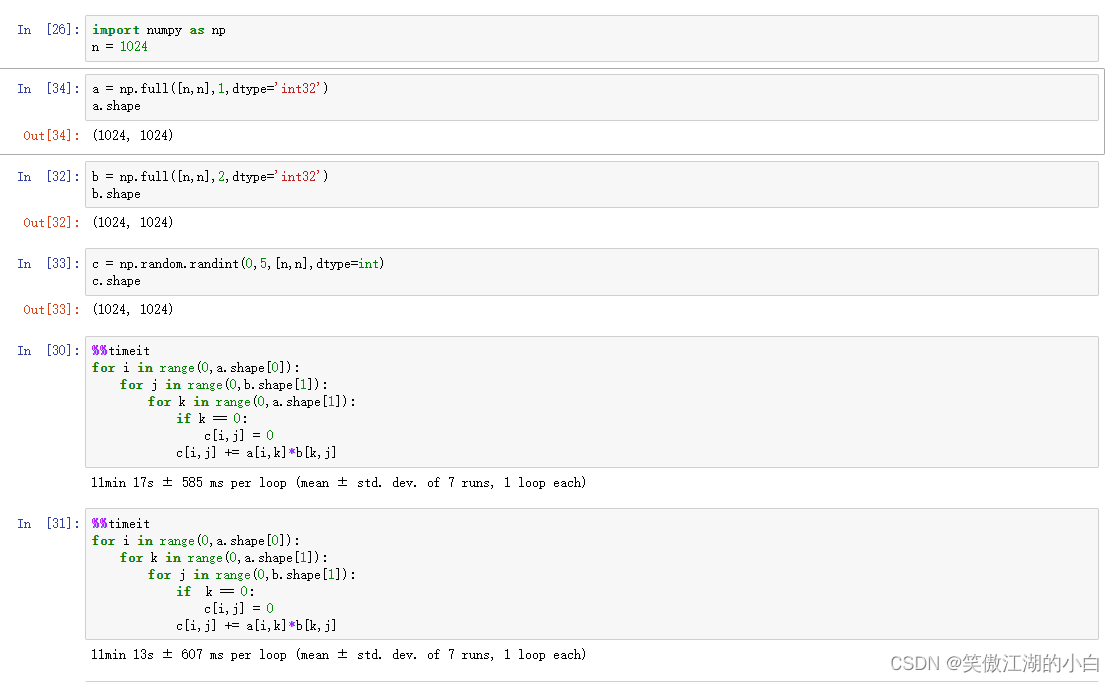
这里32KB,一个32位的int占字节数为4B,这里可以L1缓存可以存放8k个int,矩阵相乘每次需要3个矩阵空间,这里测试矩阵宽度为1024
测试结果为:
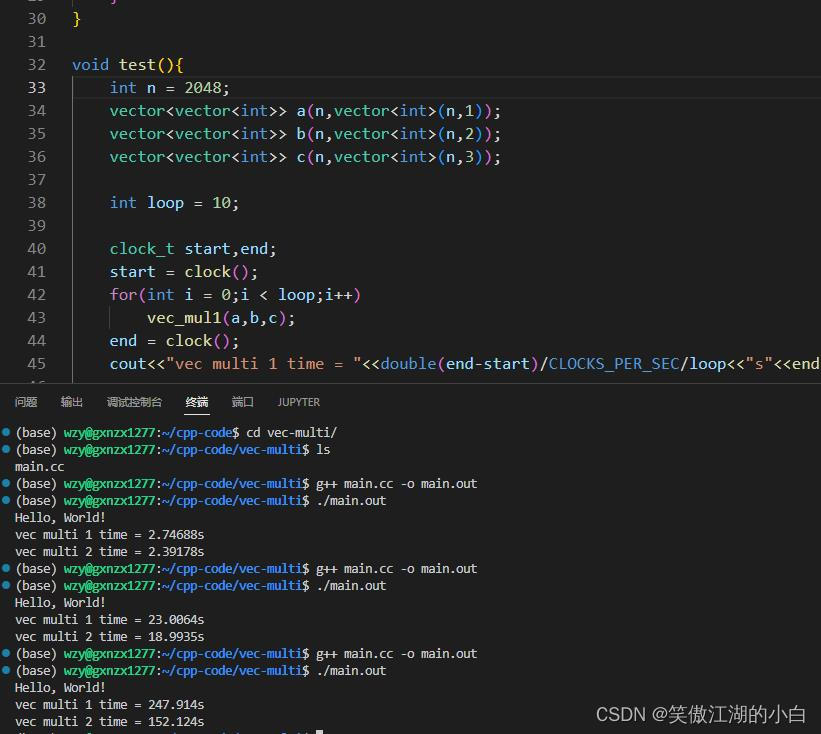
下面采用cpp做了同样的测试,在矩阵维度越大效果越明显。下面依次是矩阵维度在512,1024,2048三个维度下两种矩阵乘法的计算效率。
代码如下:
#include <iostream>
#include <vector>
#include <time.h>
using namespace std;
void vec_mul1(const vector<vector<int>> a,const vector<vector<int>> b,vector<vector<int>> c){
for(int i = 0;i < a.size();i++){
for(int j = 0;j < b[0].size();j++){
for(int k = 0;k < a[0].size();k++){
if(k == 0)
c[i][j] = 0;
c[i][j] += a[i][k]*b[k][j];
}
}
}
}
void vec_mul2(const vector<vector<int>> a,const vector<vector<int>> b,vector<vector<int>> c){
for(int i = 0;i < a.size();i++){
for(int k = 0;k < a[0].size();k++){
for(int j = 0;j < b[0].size();j++){
if(k == 0)
c[i][j] = 0;
c[i][j] += a[i][k]*b[k][j];
}
}
}
}
void test(){
int n = 2048;
vector<vector<int>> a(n,vector<int>(n,1));
vector<vector<int>> b(n,vector<int>(n,2));
vector<vector<int>> c(n,vector<int>(n,3));
int loop = 10;
clock_t start,end;
start = clock();
for(int i = 0;i < loop;i++)
vec_mul1(a,b,c);
end = clock();
cout<<"vec multi 1 time = "<<double(end-start)/CLOCKS_PER_SEC/loop<<"s"<<endl;
start = clock();
for(int i = 0;i < loop;i++)
vec_mul2(a,b,c);
end = clock();
cout<<"vec multi 2 time = "<<double(end-start)/CLOCKS_PER_SEC/loop<<"s"<<endl;
}
int main() {
std::cout << "Hello, World!" << std::endl;
test();
return 0;
}















 2133
2133











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









