







0.背景
0.0 交代故事
你是个机器学习从业者,正苦哈哈地研究着产生式模型、贝叶斯深度学习、深度强化学习之类的玩意儿,趁手的工具捉襟见肘。今天我就给你带一件儿不错的东西:标准化流,相信我,它会武装你的算法工具箱,带你飞起。标准化流能把简单的地摊货概率密度(比如高斯分布)形式转换成某种高大上的分布形式。它可以用在产生式模型、强化学习、变分推断之类的地方。至于实现,Tensorflow有一类不错的函数,它们可以搭建出标准化流,并且在真实的数据库上训练得熨熨帖帖。
这个教程分为两部分:
- 部分1:分布和行列式。我将解释概率分布的可逆转换是怎么回事儿,这个技术是怎么用在复杂概率分布的拟合上的,以及这些转换怎么连起来成为一个标准化的“流”。
- 部分2:现代标准化流技术。我将调研最近研究者如何发展了这个技术,并借此诠释一大家子产生式模型——自回归模型(autoregressive models)、MAF、IAV、NICE、Real-NVP、平行波网络(Parallel-Wavenet)——它们彼此关联。
要是你已经掌握了线性代数、概率论、神经网络、Tensorflow的相关知识,那就可以上车啦!能了解一点深度学习、产生式模型的最新进展,就更靠谱了,不知道也没多大关系。
0.1 统计机器学习
统计机器学习旨在获悉参数分布![]() ,以揭示数据的结构。以此出发,你将能达成以下四个目标:
,以揭示数据的结构。以此出发,你将能达成以下四个目标:
1.采样该结构,生成数据。这样就节省了完整的生成过程,若完整的过程纷繁浩杂,则节省巨大[1]。同样,现实数据的维度高,采样后的低维结果就可管中窥豹,节省计算。
2.评估测试数据的似然概率。在拒绝采样或评估模型时有用。【译者按:看到后面你就明白这一条了。】
3.获得变量间的条件依赖关系。如![]() 可用来判别或回归。【译者按:这一条与上一条刚好相对应,一个是unconditional likelihood estimation,一个是conditional likelihood estimation。】
可用来判别或回归。【译者按:这一条与上一条刚好相对应,一个是unconditional likelihood estimation,一个是conditional likelihood estimation。】
4.评判算法。如熵、互信息、高阶矩等指标,均可一试。
以上四个目标,第一个研究的最充分。合成图像、声音,已在谷歌商用。但第二三四个,研究寥寥。仅举几例,GAN的解码器,支撑集(映射到非零值的自变量)不可得;DRAW模型乃至VAE模型,概率密度不可得;哪怕已解析地了解某分布,解析的度量(如KL距离,earth-mover距离)还是不可得。【译者按:这句话说的简单点就是:深度产生式模型不容易甚至不可能进行测试和度量】
即使你能合成个把接近真实数据的样本,你还离目标差得远咧!我们想要了解它们多大程度上“接近真实数据”[2],想要得到灵活的条件密度(如增强学习中复杂的规则),还想要在一大家子的先验分布和后验分布上做变分推断!
0.2 高斯分布
你思索片刻,想起了你的“亲密战友”高斯分布。它在你为复杂的概率分布理出头绪而焦头烂额的时候,雪中送炭:采样方便、解析的密度已知、KL距离容易计算,还有中心极限定理的保证——任何大的数据都趋近于高斯分布,所以你怎么用它几乎都对!更别提重参数化技巧啦,你还能梯度反传。这些易用的性质,让高斯分布在产生式模型和增强学习里风头无两。
不过先别高兴的太早!许多实在的场景,我们还不能用它。在增强学习里,常有连续控制机器的场景,控制规则得用多变量高斯、对角化方差矩阵(motivariate Gaussians with diagonal covariance matrices)才行呐~
相形之下,只用单模式高斯分布模型(uni-modal Gaussian distribution),在需要多模式分布(multi-modal distribution)采样的时候,乏善可陈。试举一例,要机器人绕过湖面,到达湖后的房子,规则该是二者选一:向左绕或向右绕。单模式高斯模型容不下两个规则,所以就线性地中和了它们:直直地走向湖心。糟了个糕!
高斯分布失之过简。它不能容下对立的假设;高维的情况下分布也不够集中,出现边缘效应;还不能应对罕见事物。有没有更好的分布模型,可以满足如下条件呢?
1.足够复杂,容得下多个模式,比如增强学习中的图像和评分函数;
2.足够简单,能采样,能估计密度,能重参数化。
答案是:有!你可以做这几件事。
0.3 你需要这样的分布
以下几个办法,能帮你实现需求:
1.模型融合。一个模型对付一个子任务。
2.立足当下。一次只考虑一步,让复杂的选择在此刻退化,而仅存一端。
3.非定向图模型(undirected graphical models)。
4.标准化流。你将得到一个理想的模型:可逆、可计算分布变换体积、易模拟。
下面介绍标准化流。
1. 改变了自变量,你就改变了体积
为了建立直观,举例如下。让X服从均匀分布,![]() 。Y是X的仿射变换。如下图所示。
。Y是X的仿射变换。如下图所示。

两个方块代表概率在实数域的分布函数p(x)和p(y),函数值代表概率密度的值。概率值的积分必须等于1,任何一个分布都是这样。所以自变量变化范围扩展为两倍后,函数值就要相应地缩减一半,从而二者面积都等于1.【译者按:这就是为什么模型叫标准化流,因为有加和等于1的约束~】
若考虑X上的极小变化, Y也相应发生变化, 如下所示:

左半边的图代表一个局部增函数(),右边则是局部减函数()。p(x)因为dx带来的局部变化一定要等于p(y)随着dy的局部变化:
为了让概率的变化守恒,我们只关心变化的量,而不关心变化的方向。(实际上,不管f(x)随着x变化增或者减,都不影响,我们假设y也做出相应的变化。)那么,我们有。注意到在log空间,这等价于。在log空间中计算有利于保证计算可靠性。【注意到,这里硬生生就多了一项!】
现在考虑多变量的例子。先考虑两个变量的情况。同上面的情况,缩放定义域中的无穷小量,我们就得到一个二维的、边长为dx的小方块。
给这个小方块的顶点标注。我们现在只关心dx相对于边长为1的方块的变化率,不妨假设这个小方块就是一个边长为1的原点处的方块,那么顶点为。
乘以矩阵,我们的方块就会变成一个平行四边形,如下图。(0,0)还在(0,0), (1,0)来到了(a,b), 被送往, 到达。
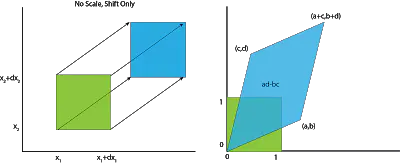
于是,一个X域边长为1的方块,转型为Y域的平行四边形,大小变成了。这个平行四边形的面积,正是转换矩阵的行列式!
三维的情况时,“转换为平行四变形”就对应为“转换为平行六面体”,或者更高维的情况也是以此类推,“转换为平行n维体”。行列式的道理也还是如此,线性变换后的体积,正好对应于变换矩阵的行列式。
要是转换函数f是非线性的咋办?你就不该把它简单地看作全空间的一个简单的平行体,而是对空间的每个点,对应于一个无穷小平行体。数学形式上看,局部线性变换对应的体积变化为,这里代表雅各比矩阵的逆——是的高维变种。于是,
敝人在中学就学了行列式,完全不理解行列式的定义,只知道计算手段。知道真相后,无语凝噎:行列式就是局部线性转换的体积变化率。
2.Tensorflow实现转换分布
Tensorflow有一个优雅的API来实现分布的转换。一个转换后的分布由以下二者唯一确定:1.基础分布,就是我们要转换的那个分布;2.一个双射函数,它由三部分构成 1)前向映射![]() ,f从d维实空间映射到d维实空间;2)反向映射
,f从d维实空间映射到d维实空间;2)反向映射![]() ;3)雅各比矩阵的逆对数行列式
;3)雅各比矩阵的逆对数行列式![]() (inverse log determinant of the Jacobian),后文简称为ILDJ。
(inverse log determinant of the Jacobian),后文简称为ILDJ。
在以上约定下,实现前向采样易如反掌:
bijector.forward(base_dist.sample())
评估转换后分布的对数密度,只需要:
distribution.log_prob(bijector.inverse(x)) + bijector.inverse_log_det_jacobian(x)
【译者按:就是上一节的公式】
更进一步,要是bijector.forward是一个可微函数,那么Y = bijector.forward(x)可以通过x的分布重参数化:x = base_distribution.sample()。这就意味着标准化流可以用在VAE的变分推断的环节,将原来版本的高斯分布改为你需要的形式。【译者按:这里是我觉得该模型最牛的地方。】
这里列出几个常用的Tensorflow分布,它们的实现实际上是通过一下的途径:
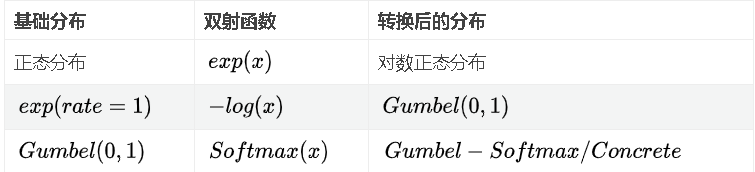
3. 标准化流从约定俗成的叫法,转换后的分布叫做双射的逆函数映射后的基础分布(Bijector^−1BaseDistribution)【译者按:我并不知道标准译法┓( ´∀` )┏】,所以指数双射(ExpBijector)后的正态分布是对数正态分布。当然,这个命名规则也有例外,Gumbel-Softmax分布被命名为约束松弛的幺零类别(RelaxedOneHotCategorical )分布,它通过Softmax函数映射一个Gumbel分布。
用了一个双射就停手吗?停手是不会停手的,这辈子都不会停手的。你可以把一系列双射连起来,在神经网络里像链子一样把它们拴在一起[3]。这个结构就叫“标准化流”。要是双射函数在bijector.log_prob有可变的参数,你就可以优化这个参数,该双射就可以把基础分布转换成任意的分布。每个双射函数可以写成一个网络的层,你可以用一个优化器来学习参数,最终拟合真实数据。算法通过最大似然估计,把拟合真实数据的分布问题变成拟合变换后的概率的对数密度问题。用对数密度的原因是为了计算的稳定性。
这页幻灯片取自Shakir Mohamed和Danilo Rezende在UWA的演讲:
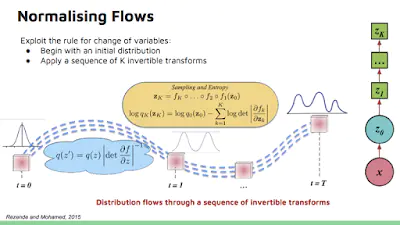
image.png
不过,计算一个的雅各比矩阵的复杂度是,对于神经网络代价颇高。还有一个麻烦,逼近任意一个函数的逆也挺难。最近的标准化流研究重点,就放在利用GPU并行计算的优势、设计出表现力强的双射函数上,也就是放在如何方便地计算ILDJ上。


















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









