









 本文介绍了特征选择在信贷风控中的重要性,探讨了通用的特征选择方法(包裹法、过滤法、嵌入法),并着重于基于特征属性的选择,如缺失率和变异系数。还提供了Python中使用SciPy库进行变异系数计算的例子。
本文介绍了特征选择在信贷风控中的重要性,探讨了通用的特征选择方法(包裹法、过滤法、嵌入法),并着重于基于特征属性的选择,如缺失率和变异系数。还提供了Python中使用SciPy库进行变异系数计算的例子。

目录
简介
基于好样本构建出好模型是我们的目标。构建好模型是指在经过预处理的数据中进行特征选择、特征提取、模型训练、分数转化和效果评估等。
特征选择
特征选择(feature selection)是指选择能够使模型获得最佳性能的特征子集。特征选择的必要性包括:
- 特征池中的特征并非都对模型有益,如果选取不稳定的特征训练模型,那么最终生成的模型的稳定性较差;
- 线性模型要求特征间不能多重共线性,因此,我们需要选择无严重多重共线性的特征建模;
- 选取可能对模型有增益的特征,剔除无用特征,从而降低特征维度,可以缩短模型训练时间和减少对机器资源的消耗。特征选择一般需要反复迭代、验证,并且和模型训练过程循环进行,最终训练得到性能优异的模型。
通用方法
特征选择有包裹法、过滤法和嵌入法。
- 包裹法(wrapper):从初始特征集合中不断选择特征子集,训练学习器(算法在工程中的具体实现对象),根据学习器的性能对子集进行评价,直到选出最佳子集。包裹法为每个特征子集训练一个新模型,计算量很大,不过,它往往能为特定类型的模型找到性能较好的特征子集。逐步回归和递归特征消除是常见的两种基于包裹法的特征选择方式。
- 过滤法(filter):首先设定阈值或待选特征个数,然后根据特征统计指标选择特征。在风控模型的建模过程中,通常根据IV、PSI和相关性等指标进行特征筛选。过滤法的计算量一般比包裹法小,但这类方法找到的特征子集不能被特定类型的预测模型调校。由于缺少调校,因此过滤法选取的特征子集比包裹法选取的特征子集通用,但这往往导致过滤法的预测能力比包裹法低。
- 嵌入法(embedded):先使用某些机器学习算法和模型进行训练,得到特征系数或特征重要度,再根据特征重要度选择特征。嵌入法类似于过滤法,但嵌入法是通过模型训练确定特征优劣的。利用树模型筛选特征是常见的基于嵌入法的特征选择方式。
包裹法和嵌入法均涉及模型训练,并且根据模型结果评价特征,最终选择特征子集。需要注意的是,此过程中的模型训练仅以选择特征为目的,不同的模型参数设置对选择的特征会有较大影响。因此,我们建议尝试多组参数并取结果的并集。
具体方法
上述3种方法是通用的特征选择方法,它们主要从模型预测效果的角度来评价特征选择的好坏。站在风险控制角度,我们除关注准确性以外,还格外关注稳定性。特征的稳定性在很大程度上决定了模型的稳定性,因此,选择稳定的特征进行建模尤为重要。站在风控业务角度从基于特征属性选择、基于特征效果选择和基于特征稳定性选择3个方面介绍特征选择,并将通用特征选择方法融入其中。
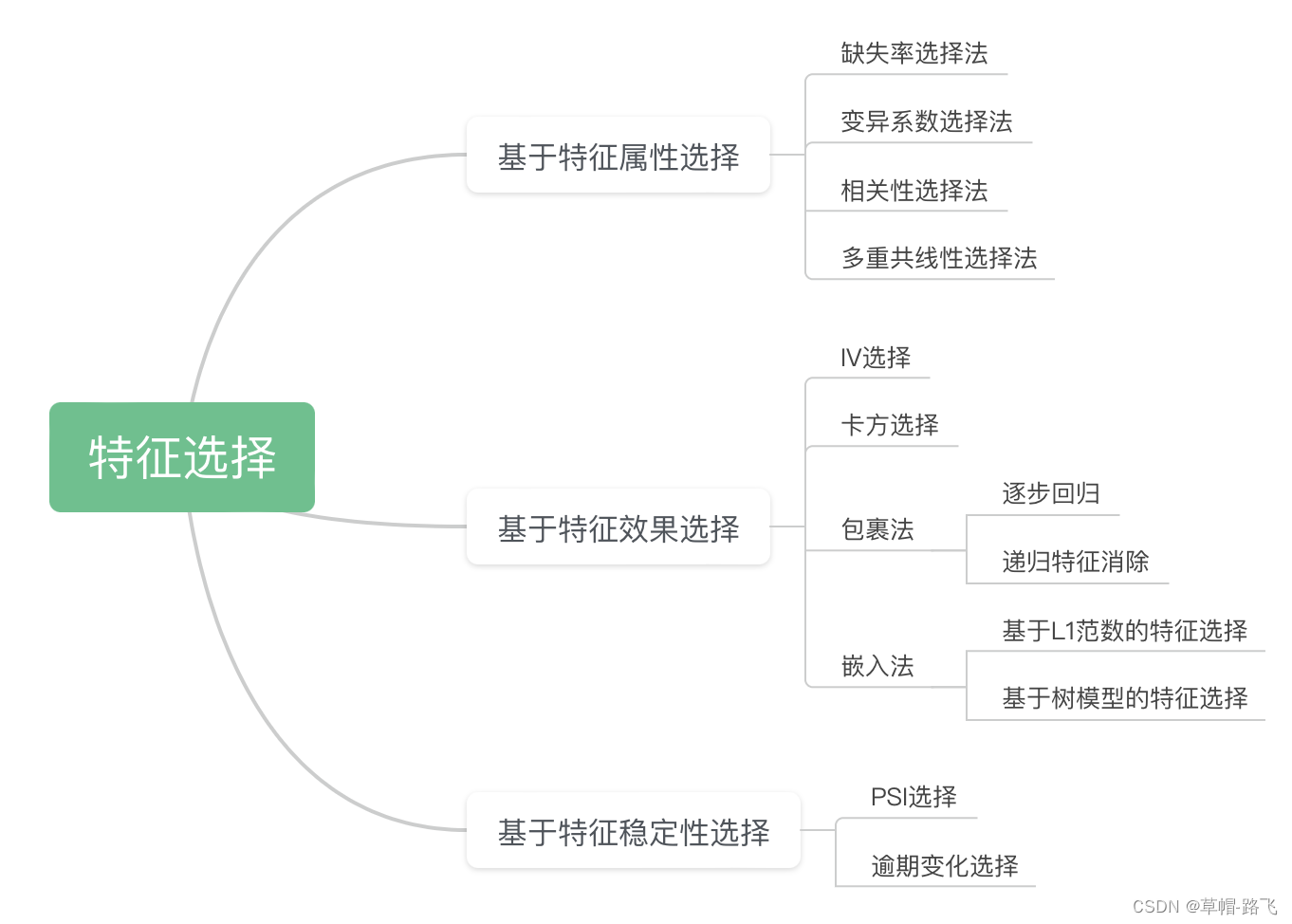
基于特征属性选择
基于特征属性选择特征,不需要任何标签信息,直接根据特征值分布或特征之间的关系进行选择,计算速度快,一般用于特征初筛。主要方法有缺失率选择法、变异系数选择法、相关性选择法和多重共线性选择法。
缺失率选择法
一般情况下,当特征缺失率超过95%时,就不再适合参与建模,首先要做的是剔除特征;而当特征缺失率不超过95%时,可以使用缺失值处理方法进行处理。对于缺失率阈值,我们可根据具体业务场景灵活调整。
变异系数选择法
变异系数(coefficient of variation),又称“离散系数”,是概率分布离散程度的一个归一化量度,其定义为标准差与均值之比。变异系数反映了特征分布的离散程度。相比方差,变异系数是一个无量纲量,因此,在比较两组量纲不同或均值不同的数据时,应该用变异系数而不是标准差。如果某个特征的变异系数很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同。特征选择过程中会首先过滤变异系数为0的特征。
在Python中,我们可以利用SciPy库中的variation(方法计算变异系数,通过参数nan_policy指定缺失值处理方法,该参数设为“omit”时,忽略缺失值,设为“raise”时,抛出异常,设为“propagate”时,返回NaN
待续:【信贷风控30分钟精通17】特征工程2
print('一定要每天开心啊')


















 326
326

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











