







目录
在绝大多数关于因果关系的材料中,研究人员使用合成数据来检查他们的方法是否有效。就像我们在“当预测失败时”一章中所做的那样,他们在 和
上生成数据,以便他们可以检查他们的模型是否正确捕获了干预效果
。这对于学术目的来说很好,但在现实世界中,我们没有那么奢侈的待遇。在工业界中应用这些技术时,我们会一次又一次地被问到为什么我们的模型更好,为什么要在生产中替换当前的模型,或者为什么它不会惨遭失败。这非常重要,以至于我无法理解为什么我们没有看到任何解释我们应该如何用真实数据评估因果推理模型的材料。
因此,想要应用因果推理模型的数据科学家很难说服管理层信任他们。他们采用的方法之一是展示理论的合理性以及他们在训练模型时的谨慎程度。不幸的是,在一个以训练-测试分割范式为常态的世界中,这么做没有什么用。你的模型的质量必须建立在比漂亮的理论更具体的东西上。想想看,机器学习之所以取得巨大成功,是因为预测模型的验证非常直接。看到预测与实际发生的情况相符,这让人放心。
不幸的是,在因果推理的情况下,我们如何实现像训练-测试范式这样的东西并不明显。这是因为因果推理对估计一个不可观察的量感兴趣,。好吧,如果我们看不到它,我们怎么知道我们的模型是否擅长估计它呢?请记住,就好像每个实体都有潜在的,用从干预到结果的估计线的斜率表示的反应,但我们无法衡量它。

这是一件非常非常非常困难的事情,我花了很多年才找到接近答案的东西。不是一个确定的模型,但它在实践中有效,并且很具体,我希望它能够从类似于机器学习的训练-测试范式中进行因果推理。诀窍是使用弹性的聚合测量。即使你不能单独估计弹性,你也可以为一个群体做,这就是我们将在这里利用的。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from toolz import curry
import statsmodels.formula.api as smf
import statsmodels.api as sm
from sklearn.ensemble import GradientBoostingRegressor在本章中,我们将使用非随机数据来估计我们的因果模型,并使用随机数据来评估它。 同样,我们将讨论价格如何影响冰淇淋销售。 正如我们将看到的,随机数据对于评估目的非常有价值。 然而,在现实生活中,收集随机数据通常是昂贵的(如果你知道其中一些价格不是很好,只会让你赔钱,为什么还要随机定价???)。 最终发生的情况是,我们经常拥有大量数据,其中处理不是随机的,而随机数据(如果有的话)非常少。 由于使用非随机数据评估模型非常棘手,因此如果我们有任何随机数据,我们倾向于将其留作评估目的。
以防万一您忘记了,这是数据的样子。
prices = pd.read_csv("./data/ice_cream_sales.csv") # loads non-random data
prices_rnd = pd.read_csv("./data/ice_cream_sales_rnd.csv") # loads random data
print(prices_rnd.shape)
prices.head()
(5000, 5)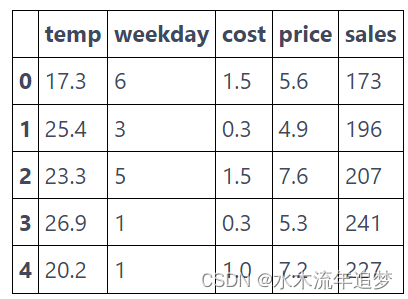
出于比较目的,让我们训练两个模型。 第一个将是具有交互项的线性回归,以便允许弹性在单位之间变化。
一旦我们拟合了这个模型,我们将能够进行弹性预测。
m1 = smf.ols("sales ~ price*cost + price*C(weekday) + price*temp", data=prices).fit()第二个模型将是完全非参数、基于机器学习的预测模型:
X = ["temp", "weekday", "cost", "price"]
y = "sales"
np.random.seed(1)
m2 = GradientBoostingRegressor()
m2.fit(prices[X], prices[y]);为了确保模型没有严重过度拟合,我们可以比较我们使用训练它的数据的到的和使用新的、看不见的数据得到的
。 (对于那些更精通机器学习的人,请注意性能会有所下降,因为存在概念漂移。模型是在价格不是随机的数据中训练的,但测试集只有随机价格)。
print("Train Score:", m2.score(prices[X], prices[y]))
print("Test Score:", m2.score(prices_rnd[X], prices_rnd[y]))
Train Score: 0.9251704824568053
Test Score: 0.7711074163447711在训练我们的模型之后,我们将从回归模型中获得弹性。 同样,我们将求助于数值近似
我们的模型接受了非随机数据的训练。 现在我们转向随机数据进行预测。 就这样我们将所有东西都放在一个地方,我们将把机器学习模型的预测和因果模型的弹性预测添加到单个数据帧“prices_rnd_pred”中。
此外,我们还包括一个随机模型。 这个想法是这个模型只输出随机数作为预测。 它显然不是很有用,但它可以很好地作为基准。 每当我们谈论进行评估的新方法时,我总是喜欢思考随机(无用)模型会如何做。 如果随机模型能够在评估标准上表现良好,那就说明评估方法的真正好坏。
def predict_elast(model, price_df, h=0.01):
return (model.predict(price_df.assign(price=price_df["price"]+h))
- model.predict(price_df)) / h
np.random.seed(123)
prices_rnd_pred = prices_rnd.assign(**{
"m1_pred": m2.predict(prices_rnd[X]), ## predictive model
"m2_pred": predict_elast(m1, prices_rnd), ## elasticity model
"m3_pred": np.random.uniform(size=prices_rnd.shape[0]), ## random model
})
prices_rnd_pred.head()
弹性模型带
现在我们有了预测,我们需要评估它们的好坏。请记住,我们无法观察到弹性,因此没有可以比较的简单基本事实。相反,让我们回想一下我们想要从弹性模型中得到什么。也许这会给我们一些关于如何评估它们的见解。
制作干预弹性模型的想法来自于需要找出哪些单位对干预更敏感,哪些更不敏感。它来自对个性化的渴望。也许营销活动只在一部分人群中非常有效。也许折扣只适用于某些类型的客户。一个好的因果模型应该可以帮助我们发现哪些客户对提议的干预反应更好和更差。他们应该能够将单位分成他们对干预的弹性或敏感程度。在我们的冰淇淋示例中,该模型应该能够计算出人们在哪几天愿意在冰淇淋上花费更多,或者在哪几天价格弹性的负值较小。
如果这是目标,那么如果我们能以某种方式将单位从更敏感到不太敏感排序,那将非常有用。由于我们有预测的弹性,我们可以按该预测对单位进行排序,并希望它也按实际弹性对它们进行排序。遗憾的是,我们无法在单位级别上评估该排序。但是,如果我们不需要呢?相反,如果我们评估由排序定义的组怎么办?如果我们的处理是随机分布的(这是随机性进入的地方),那么估计一组单位的弹性很容易。我们所需要的只是比较干预与否的结果。
为了更好地理解这一点,描绘二元处理案例很有用。让我们保留定价示例,但现在的干预量是折扣。换句话说,价格可以高(未处理)或低(处理)。让我们在 Y 轴上绘制销售额,在 X 轴上绘制我们的每个模型,并将价格作为颜色。然后,我们可以将模型轴上的数据分成三个大小相等的组。 如果干预是随机分配的,我们可以轻松估计每组的 ATE E[Y|T=1]−E[Y|T=0]。
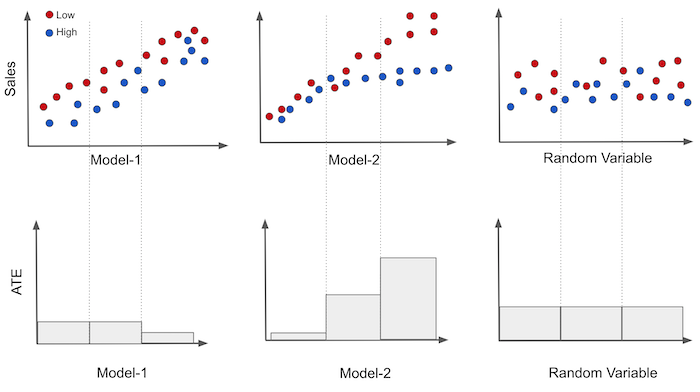
在图像中,我们可以看到第一个模型在预测销售额方面有些好(与销售额相关性高),但它产生的组具有大致相同的处理效果,如下图所示。三个部分中有两个具有相同的弹性,只有最后一个具有不同的较低弹性。
另一方面,第二个模型产生的每一组都有不同的因果效应。这表明该模型确实可以用于个性化。最后,随机模型产生具有完全相同弹性的组。这不是很有用,但它是预期的。如果模型是随机的,则它产生的每个片段都是随机且具有代表性的数据样本。因此,其组中的弹性应该与整个数据集上的 ATE 大致相同。
只需查看这些图,您就可以了解哪个模型更好。弹性看起来越有序,带之间的差异越大,越好。在这里,模型 2 可能比模型 1 更好,这可能比随机模型更好。
为了将其推广到连续情况,我们可以使用单变量线性回归模型来估计弹性。
如果我们使用一组样本运行该模型,我们将估计该组内的弹性。
根据简单线性回归的理论,我们知道
其中 是处理的样本平均值,
是结果的样本平均值。 这是代码中的样子
def elast(data, y, t):
# line coeficient for the one variable linear regression
return (np.sum((data[t] - data[t].mean())*(data[y] - data[y].mean())) /
np.sum((data[t] - data[t].mean())**2))现在让我们将其应用于我们的冰淇淋价格数据。 为此,我们还需要一个函数,将数据集分割成大小相等的分区,并将弹性应用于每个分区。 以下代码将处理该问题。
def elast_by_band(df, pred, y, t, bands=10):
return (df
.assign(**{f"{pred}_band":pd.qcut(df[pred], q=bands)}) # makes quantile partitions
.groupby(f"{pred}_band")
.apply(elast(y=y, t=t))) # estimate the elasticity on each partition最后,让我们使用我们之前所做的预测按波段绘制弹性。 在这里,我们将使用每个模型来构建分区,然后估计每个分区的弹性。
fig, axs = plt.subplots(1, 3, sharey=True, figsize=(10, 4))
for m, ax in enumerate(axs):
elast_by_band(prices_rnd_pred, f"m{m+1}_pred", "sales", "price").plot.bar(ax=ax)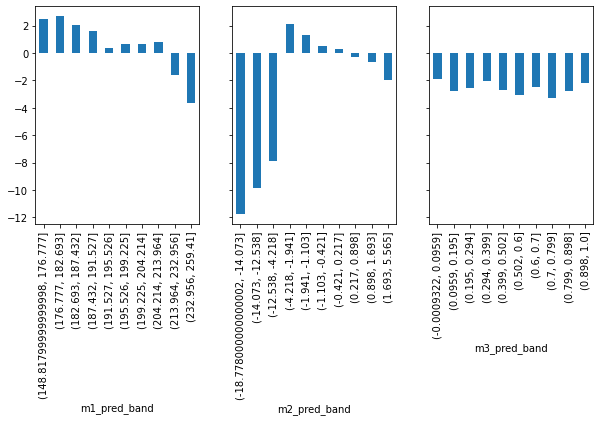
首先,查看随机模型 (m3)。它在每个分区中具有大致相同的估计弹性。通过查看该图,我们已经可以看出,它对个性化没有太大帮助,因为它无法区分高价格弹性日和低价格弹性日。接下来,考虑预测模型 m1。该模型实际上是有前途的!它设法构建弹性高的组和弹性低的组。这正是我们所需要的。
最后,因果模型 m2看起来有点奇怪。它识别出弹性非常低的群体,这里的低实际上意味着高价格敏感度(随着我们提高价格,销售额将大幅下降)。检测那些价格敏感的日子对我们非常有用。如果我们知道它们是什么时候,我们会小心不要在这些日子继续涨价。因果模型还识别了一些不太敏感的区域,因此它可以成功地区分高弹性和低弹性。但是排序不如预测模型好。
那么,我们应该如何决定呢?哪个更有用?预测模型还是因果模型?预测模型具有更好的排序,但因果模型可以更好地识别极端情况。带状图的弹性是一个很好的初步检查,但它不能准确回答哪个模型更好。我们需要转向更精细的东西。
















 1392
1392











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











