







目录
我们要讨论的下一个元学习器,实际上出现在元学习器被称为元学习器之前。据我所知,它来自 2016 年的一篇出色论文,这篇论文在因果推理文献中开创了一个成果丰硕的领域。这篇论文叫做《治疗和因果参数的双重机器学习》(Double Machine Learning for Treatment and Causal Parameters),写这篇论文的人可真不少: 维克托-切尔诺茹科夫、丹尼斯-切特维里科夫、梅尔特-德米雷尔、埃斯特-杜夫洛(顺便说一下,杜夫洛与阿比吉特-班纳吉和迈克尔-克雷默 "因其减轻全球贫困的实验方法 "而获得了 2019 年经济学诺贝尔奖)、克里斯蒂安-汉森、惠特尼-纽威和詹姆斯-罗宾斯。
这篇论文只有一个问题:读起来非常困难(这是意料之中的,因为这是一篇计量经济学论文)。既然本书的宗旨是让因果推理成为主流,那么我们就在这里尝试让偏差/正交机器学习变得直观。
但是,除了其他元学习器之外,是什么让它如此特别,以至于值得单独成章呢?引起我注意的是去偏/全交机器学习的合理性。迄今为止,我们所见过的其他方法,如 T 学习器、S 学习器和 X 学习器,看起来都有点黑。我们可以直观地解释它们的工作原理,但它们似乎不是很通用。相比之下,有了 Debiased/Orthogonal Machine Learning,我们就有了一个可以应用的通用框架,它既非常直观,又非常严谨。另一个好处是,Debiased/Orthogonal ML 既适用于连续处理,也适用于离散处理,这是 T 学习器和 X 学习器都无法做到的。更不用说,介绍它的论文对这种估计器的渐近分析做得非常出色。废话不多说,让我们开始吧。
作为一个激励性的例子,我们将再次使用冰淇淋销售数据集。提醒一下,在这里我们试图找到价格对销售额影响的异质性。我们的测试集有随机分配的价格,但我们的训练数据只有观察到的价格,这可能存在偏差。
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import seaborn as sns
from nb21 import cumulative_gain, elast
import statsmodels.formula.api as smf
from matplotlib import style
style.use("ggplot")
test = pd.read_csv("./data/ice_cream_sales_rnd.csv")
train = pd.read_csv("./data/ice_cream_sales.csv")
train.head()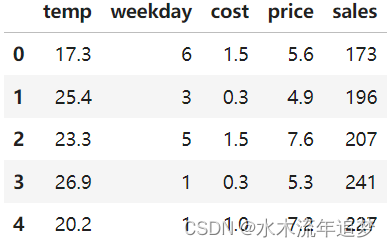
np.random.seed(123)
sns.scatterplot(data=train.sample(1000), x="price", y="sales", hue="weekday")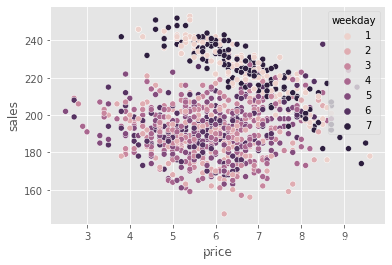
偏差的一个来源非常明显。我们可以看到,周末(工作日 1 日和 7 日)的价格要高得多,但也可能有其他混杂因素,如温度和成本。因此,如果我们想利用它进行任何因果推断,就需要纠正这种偏差。
ML for Nuisance Parameters
我们可以尝试消除这种偏差,方法之一是使用线性模型来估计价格对销售额的影响,同时控制混杂因素。
其中 是与每个工作日虚拟值相关的参数向量。
请注意,我们只对 参数感兴趣,因为这是我们的治疗效果。我们将其他参数称为干扰参数,因为我们并不关心它们。但是,事实证明,即使我们不关心它们,我们也必须把它们弄对,因为如果弄不对,我们的治疗效果就会有偏差。这有点恼人。
例如,如果我们仔细想想,温度和销售额之间的关系可能不是线性的。首先,随着气温的升高,会有更多的人去海边买冰淇淋,因此销售额会增加。但是,到了某一时刻,天气变得太热,人们决定最好待在家里。这时,销售额就会下降。温度和销售额之间的关系可能会在某处达到顶峰,然后下降。这意味着上述模型可能是错误的。应该是这样的‘’
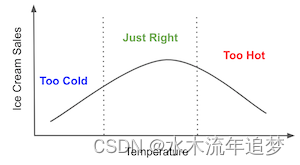
如果只有几个协变量,思考如何为干扰参数建模就已经很无聊了。但如果我们有几十个或几百个协变量呢?在现代数据集中,这种情况非常普遍。那么,我们能做些什么呢?答案就是有史以来最酷的计量经济学定理。
Frisch-Waugh-Lovell
弗里施、沃夫和洛弗尔是 20 世纪的计量经济学家,他们注意到了线性回归的最酷之处。这对你来说并不陌生,因为我们在讨论回归残差和固定效应时已经谈到过。但由于该定理是理解Orthogonal-ML的关键,因此非常值得复述一下。
假设你有一个线性回归模型,其中有一组特征 和另一组特征
. 然后你要估计该模型的参数。
其中 和
是特征矩阵(每个特征一列,每个观测值一行),而
和
是行向量。您可以通过以下步骤获得完全相同的
参数
1.将结果 y 对第二组特征进行回归
2.将第一组特征回归到第二组特征上
3.得到残差 和
4. 将结果的残差回归到特征的残差上
这简直太酷了。在这里,我们有一个通用的表示方法,但请注意,一组特征可以只是处理变量。这意味着你可以分别估计所有干扰参数。首先,将结果与特征进行回归,得到结果残差。然后,将治疗与特征进行回归,得到治疗残差。最后,将结果残差与特征残差进行回归。这样得到的估计结果与同时对特征和治疗进行回归得到的结果完全相同。
但不要相信我的话。每个对因果推断感兴趣的人都应该至少做一次 FWL。在下面的例子中,我们首先估计协变量对结果(销售额)和处理(价格)的影响,从而估计处理效果。
my = smf.ols("sales~temp+C(weekday)+cost", data=train).fit()
mt = smf.ols("price~temp+C(weekday)+cost", data=train).fit()然后,利用残差,我们估算出价格对销售额的 ATE。
smf.ols("sales_res~price_res",
data=train.assign(sales_res=my.resid, # sales residuals
price_res=mt.resid) # price residuals
).fit().summary().tables[1]
我们估计 ATE 为-4,这意味着价格每增加一个单位,销售量就会减少 4 个单位。
现在,我们来估算相同的参数,但这次我们要将处理方法和协变量纳入同一个模型中。
smf.ols("sales~price+temp+C(weekday)+cost", data=train).fit().params["price"]
-4.000429145475454正如您所看到的,它们的数字完全相同!这表明,一次性估算治疗效果或在 FWL 步骤中分别估算治疗效果在数学上是相同的。
另一种说法是,治疗效果可以通过残差回归得出,即我们从 Y 对 X 的回归中获得残差,并将其与 T 对 X 的回归残差进行回归。因此我们可以将 FWL 定理概括如下。
这实质上是在以下模型中估计因果参数
正如我所说,FWL 之所以这么棒,是因为它允许我们将因果参数的估计过程与干扰参数的估计过程分开。但我们仍然没有回答最初的问题,那就是如何避免为指定干扰参数的正确函数形式而带来的麻烦?或者换句话说,我们如何才能只关注因果参数,而不必担心干扰参数?这就是机器学习发挥作用的地方。
















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











