







目录
1) Birth: The Promise of Panel Data
在讨论了治疗效果异质性之后,我们现在将转换一下思路,回到平均治疗效果上来。在接下来的几章中,我们将介绍面板数据方法的一些最新进展。面板数据是一种跨时间重复观测的数据结构。我们在多个时间段内观察同一单位,可以了解治疗前后发生的情况。这就使得面板数据成为在无法进行随机化时确定因果效应的一种有前途的替代方法。
为了鼓励使用面板数据,我们将主要讨论因果推理在市场营销中的应用。市场营销因其难以进行随机实验而特别有趣。在市场营销中,我们往往无法控制谁接受了治疗,也就是说,谁看到了我们的广告。当一个新用户访问我们的网站或下载我们的应用程序时,我们无法很好地知道该用户是因为看到了我们的广告活动还是因为其他因素。
(OBS:对于那些更熟悉营销归因的人来说,我知道有很多归因工具旨在解决这个问题。但我也知道它们有很多局限性)。
线下营销的问题更大。你怎么能知道电视营销活动是否带来了超出成本的价值?因此,市场营销中的一种常见做法是地理实验:我们在某些地理区域部署营销活动,而不在其他区域部署,然后进行比较。在这种设计中,面板数据方法尤为有趣:我们可以在多个时间段内收集整个地理区域(单位)的数据。要理解这类数据并确定因果效应,最常用的方法可能是差分法(DiD)系列。
2020 年和 2021 年对我们大多数人来说都不容易。但对 DiD 来说尤其艰难。最近的大量研究凸显了这些方法的一些严重缺陷,而这些缺陷在过去并不为人所知。因此,尽管我们在第一部分中已经有一章涉及 DiD,但其中的内容都是介绍性的。它没有涵盖围绕面板数据方法的新发现和热烈讨论。现在,我们应该从 Diff-in-Diff 开始,对它们进行更深入的研究。在本章中,我将尝试总结最近发现的差分法问题,并说明如何解决这些问题。本章分为三节:
出生: 回顾为什么面板数据对因果推断如此有吸引力,以及 DiD 和双向固定效应(TWFE)如何利用时间结构对其有利。
死亡: 解读 DiD 和 TWFE 模型中隐含的一个被忽视的关键假设。了解该假设何时以及如何失效。
启迪: 知道了 DiD 和 TWFE 的问题所在,我们现在就可以想办法解决它了。本部分展示了解决第 2 节中探讨的问题的简单方法。
让我们直接进入正题!
1) Birth: The Promise of Panel Data

就像我说过的,面板数据是指多个单位 i 在多个时间段 t 内的数据。想一想美国的政策评估方案,您想检查大麻合法化对犯罪率的影响。您有多个州 i 在多个时间段 t 内的犯罪率数据。您还可以观察每个州在哪个时间点通过了大麻合法化方向的立法。我希望你能明白为什么这对因果推论来说非常有力。将大麻合法化称为处理 D(因为 T 是取值,代表时间)。我们可以跟踪某个最终得到治疗的州的犯罪率趋势,看看在治疗时间是否有任何趋势中断。在某种程度上,一个州可以作为自己的控制单元,进行前后对比。此外,由于我们有多个状态,我们还可以将治疗状态与对照状态进行比较。当我们把这两种比较(治疗前与对照组、治疗前与治疗后)放在一起时,我们就拥有了一个非常强大的工具来推断反事实,进而推断因果效应。
面板数据方法通常用于政府政策评估,但我们也可以很容易地论证为什么面板数据方法对(科技)行业也非常有用。公司通常会在多个时间段内跟踪用户数据,从而形成丰富的面板数据结构。不仅如此,有时实验是不可能的,因此我们必须依靠其他识别策略。为了进一步探讨这一观点,我们不妨举一个假设的例子:一家年轻的科技公司跟踪多个城市中安装其应用程序的人数。2021 年的某一天,这家科技公司在其应用程序中推出了一项新功能。它现在想知道该功能给公司带来了多少新的使用。新功能的推出是循序渐进的。一些城市在 2021-06-01 获得了该功能。其他城市则是在 2021-07-15。其余城市要到 2022 年才全面推广。由于我们的数据仅截止到 2021-07-31,因此最后一组可视为对照组。从因果推论的角度来看,推出这一功能可视为处理,而安装数量可视为结果。我们想知道治疗对结果的影响,即新功能对安装次数的影响。
请注意,科技公司无法在这里做实验。他们无法控制哪个人知道他们有了新功能。我们说他们对处理分配的控制是有限的。这是因为分析的单位是尚未成为他们客户的人。他们想知道有多少人可以通过安装他们的应用程序转化为客户。当然,他们无法对这些人进行随机分配。因此,他们将分析单位改为城市。城市与城市之间的发布量是他们可以控制的,而一个人与另一个人之间的发布量则无法控制。
在特定时间点获得该功能(接受治疗)的城市群体被称为队列。在我们的案例中,我们有三个队列:一个是在 2021-06-01 年接受治疗的队列,另一个是在 2021-07-15 年接受治疗的队列,还有一个是在数据结束后才接受治疗的对照队列。为了了解这些数据的外观,让我们绘制一下按队列分组的日均安装量。
date = pd.date_range("2021-05-01", "2021-07-31", freq="D")
cohorts = pd.to_datetime(["2021-06-01", "2021-07-15", "2022-01-01"]).date
units = range(1, 100+1)
np.random.seed(1)
df = pd.DataFrame(dict(
date = np.tile(date, len(units)),
unit = np.repeat(units, len(date)),
cohort = np.repeat(np.random.choice(cohorts, len(units)), len(date)),
unit_fe = np.repeat(np.random.normal(0, 5, size=len(units)), len(date)),
time_fe = np.tile(np.random.normal(size=len(date)), len(units)),
week_day = np.tile(date.weekday, len(units)),
w_seas = np.tile(abs(5-date.weekday) % 7, len(units)),
)).assign(
trend = lambda d: (d["date"] - d["date"].min()).dt.days/70,
day = lambda d: (d["date"] - d["date"].min()).dt.days,
treat = lambda d: (d["date"] >= d["cohort"]).astype(int),
).assign(
y0 = lambda d: 10 + d["trend"] + d["unit_fe"] + 0.1*d["time_fe"] + d["w_seas"]/10,
).assign(
y1 = lambda d: d["y0"] + 1
).assign(
tau = lambda d: d["y1"] - d["y0"],
installs = lambda d: np.where(d["treat"] == 1, d["y1"], d["y0"])
)
plt.figure(figsize=(10,4))
[plt.vlines(x=cohort, ymin=9, ymax=15, color=color, ls="dashed") for color, cohort in zip(["C0", "C1"], cohorts[:-1])]
sns.lineplot(
data=(df
.groupby(["cohort", "date"])["installs"]
.mean()
.reset_index()),
x="date",
y = "installs",
hue="cohort",
);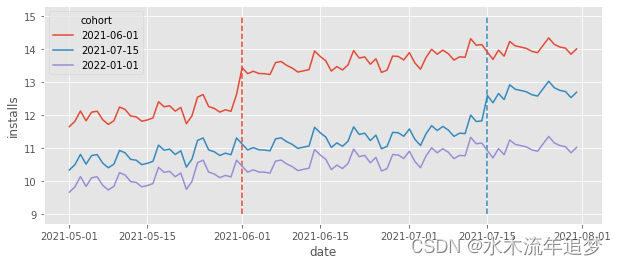
虚线标记的是队列获得治疗(功能推出)的时间。请花点时间欣赏上图中丰富的数据。首先,我们可以看到每个队列都有自己的基线水平。这只是因为不同城市的人口数量不同,导致安装量的多寡取决于城市规模。例如,与其他组群的城市相比,第一组群(06/01 接受治疗)的城市基线较高。此外,对照组的基线安装量也较低。这就意味着,简单地将治疗队列与对照队列进行比较会产生有偏差的结果,因为对照队列的 低于治疗队列的
,或
(我们用 G 表示队列)。幸运的是,这不是一个问题。面板数据允许我们进行跨城市和跨时间的比较,从而可以调整不同的基线。
说到时间,请注意总体趋势是上升的,但也有一些波动(看起来像是每周的季节性)。以对照组为例,日安装量从 5 月份的 10 个左右上升到 6 月份的 11 个左右,上升了约 1 个百分点。这意味着,简单地比较不同时间段的相同城市也会产生有偏差的结果。我们再次感到幸运的是,面板数据结构使我们不仅可以进行跨时间比较,还可以进行跨城市比较,并对趋势进行调整。
理想情况下,为了推断新功能的推出对安装量的影响,我们想知道,如果没有获得该功能,获得该功能的群组会发生什么情况。我们希望估算出治疗后各组群的反事实结果 。如果我们用获得治疗的时间 g 来表示每个群组(记住,群组只是在同一时间获得治疗的一组城市),我们就可以把这个反事实写成
,这样我们就可以定义群组 g 的治疗效果(ATT)如下:
下一个问题是,我们如何从现有数据中进行估算。一种方法是利用面板数据结构的力量来估计这些反事实。例如,我们可以使用线性回归和 "差异中的差异 "公式来建立双向固定效应模型。假设每个城市 i 都有一个基础安装水平 g。这又回到了我们之前看到的情况:也许一个城市的安装量更多,是因为它的人口更多,或者是因为它的文化更符合我们科技公司的产品。不管原因是什么,即使我们不知道为什么,我们也可以说,这些单位的特异性可以通过一个时间固定参数 来捕捉。同样,我们可以说,每个时间段 t 都有一个基线安装水平,我们可以通过一个单位固定参数
来捕捉。如果是这样的话,建立安装模型的一个好方法就是说它取决于城市(单位)效应
和时间效应
,再加上一些随机噪声。
为了将治疗纳入其中,让我们定义一个变量 ,如果单位接受了治疗,该变量为 1,否则为 0。在我们的例子中,对于从未接受过治疗的组群,这个变量始终为 0。在开始时,所有其他组群也都为 0,但在 06/01 日接受治疗的组群,该变量会在 06/01 日变为 1,并在此之后保持为 1。此外,对于 07/15 日接受治疗的组群,该指标也会在 07/15 日变为 1。我们可以在安装模型中加入这些处理指标,如下所示:
用 OLS 估计上述模型就是所谓的双向固定效应模型(TWFE)。请注意, 将是处理效应,因为它告诉我们一旦单位被处理,安装量会发生多大变化。
另一种方法是利用线性回归的 "保持不变 "特性。如果我们对上述模型进行估计,我们可以将 的估计值理解为,在单位 i 和时间 t 保持不变的情况下,如果我们将处理效果从 0 变为 1,安装量会发生多大变化。
请注意这是多么大胆的想法!如果说在观察 D 如何改变结果的同时,我们将固定每个单位,这就意味着我们控制了所有单位的特定特征,这些特征在时间上是不变的,无论是已知的还是未知的。例如,我们要控制城市的基线安装水平(我们可以测量),但也要控制一些我们不知道的因素,如城市文化与我们产品的一致性程度。唯一的要求是,这一特征在分析期间是固定的。此外,如果我们说每个时间段都是固定的,这就意味着我们控制了所有年份的特定特征。例如,由于我们将年份固定不变,因此在研究 D 的影响时,我们将控制我们之前看到的趋势和季节性。
要了解所有这些影响,我们只需运行一个 OLS 模型,其中包含治疗指标 D(此处为治疗),以及单位和时间的虚拟变量。在我们的例子中,我生成数据的方式是,处理(新功能)的效果是安装量增加 1:
formula = f"""installs ~ treat + C(unit) + C(date)"""
twfe_model = smf.ols(formula, data=df).fit()
twfe_model.params["treat"]
1.0000000000000533由于我已经对上述数据进行了模拟,因此我很清楚真实的个体治疗效果,它存储在 tau 栏中。由于 TWFE 应该恢复对被治疗者的治疗效果,我们可以验证真实的 ATT 是否与上面估计的一致。我们所要做的就是过滤治疗单位和时期(treat==1),然后取 tau 列的平均值。
df.query("treat==1")["tau"].mean()
1.0在有人说大数据不可能为每个单元生成一个虚拟列之前,请允许我站出来告诉大家,是的,确实如此。但有一个简单的解决方法。我们可以利用 FWL 定理将单一回归分为两个。事实上,运行上述模型在数值上等同于估计以下模型
换句话说,为了防止计算过于繁琐,我们从治疗指标和结果变量中减去跨时间的单位平均值(第一项)和跨单位的时间平均值(第二项),以限制残差。这个过程通常被称为去平均值,因为我们从结果和治疗中减去了平均值。最后,下面是相同的内容,但用代码表示:
@curry
def demean(df, col_to_demean):
return df.assign(**{col_to_demean: (df[col_to_demean]
- df.groupby("unit")[col_to_demean].transform("mean")
- df.groupby("date")[col_to_demean].transform("mean"))})
formula = f"""installs ~ treat"""
mod = smf.ols(formula,
data=df
.pipe(demean(col_to_demean="treat"))
.pipe(demean(col_to_demean="installs")))
result = mod.fit()
result.summary().tables[1]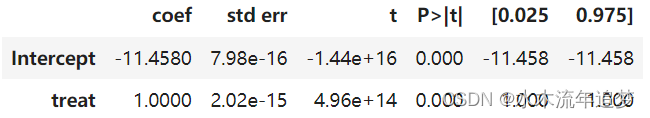
要了解 TWFE 模型的另一个方法是绘制反事实预测 。这很有帮助,因为我们的模型所认为的治疗效果
只是
的估计差值。通过观察这个明确的差值,我们可以了解模型在做什么。在下图中,我们可以看到
用虚线表示。
df_pred = df.assign(**{"installs_hat_0": twfe_model.predict(df.assign(**{"treat":0}))})
plt.figure(figsize=(10,4))
[plt.vlines(x=cohort, ymin=9, ymax=15, color=color, ls="dashed") for color, cohort in zip(["C0", "C1"], cohorts[:-1])]
sns.lineplot(
data=(df_pred
.groupby(["cohort", "date"])["installs_hat_0"]
.mean()
.reset_index()),
x="date",
y = "installs_hat_0",
hue="cohort",
alpha=0.7,
ls="dotted",
legend=None
)
sns.lineplot(
data=(df_pred
.groupby(["cohort", "date"])["installs"]
.mean()
.reset_index()),
x="date",
y = "installs",
hue="cohort",
);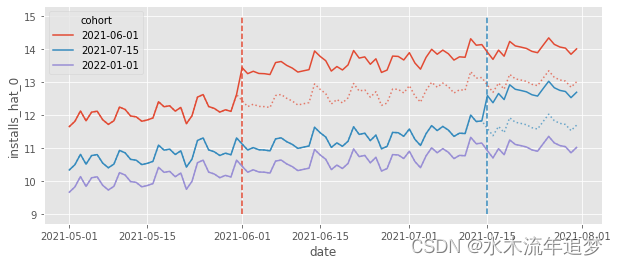
该图向我们展示了 TWFE 如何将其在对照组中看到的趋势投射到治疗组中,并对水平进行调整。例如,如果我们观察红色组群,则反事实 Y0 是蓝色和紫色组群的平均趋势(趋势预测),但转移到了红色组群的水平(水平调整)。这就是我们将 TWFE 视为差分法的原因。它也进行趋势预测和水平调整,但它适用于多个时间段和多个单位(在 2 个单位 2 个时间段的情况下,TWFE 和 DiD 是等价的)。
















 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











