







目录
Test Statistic
除了置信区间外,有时将拒绝零假设的想法以检验统计量的形式表达也很有用。这些统计量常常构建得使得更高的值指向对零假设的拒绝。最常用的检验统计量之一是t统计量。它可以通过归一化产生置信区间的分布来定义:
这里 是由你的零假设定义的值。
注意分子仅仅是观测到的平均差异与零假设之间的差值。如果零假设成立,这个分子的期望值应该是零:。分母是标准误差,它将统计量标准化为单位方差。这确保了如果零假设为真,
将遵循标准正态分布——N(0, 1)。既然在零假设下
围绕零中心分布,那么高于或低于1.96的值会极为罕见(出现少于95%的时间)。这意味着如果你观察到如此极端的t统计量,你也可以拒绝零假设。在我们的示例中,与零效果的
相关的统计量大于2,意味着你可以在95%的置信水平下拒绝它:
t_stat = (diff_mu - 0) / diff_se
t_stat
2.2379512318715364此外,因为t统计量在零假设下服从正态分布,你可以轻松地使用它来计算p值。
p-values
之前我已经说过,如果收到无邮件和简短邮件的客户的转化率相同,观察到如此极端差异的可能性小于5%。但是你能精确估计这个可能性是多少吗?观察到如此极端值的可能性有多大?这就引出了p值的概念!
如同置信区间(实际上,大多数频数统计学概念亦是如此),p值的真实定义可能非常令人困惑。为了避免任何风险,我将引用维基百科上的定义:“p值是在假设零假设正确的情况下,获得至少与实际测试中观察到的结果一样极端的测试结果的概率。”
更简洁地说,p值是在零假设为真的情况下,观察到如此数据的概率(见图2-4)。它衡量的是在零假设为真的前提下,你正在观察的测量结果有多么不可能。自然而然地,这经常会被误解为零假设为真的概率。请注意其中的区别。p值不是P(H0|data),而是P(data|H0)。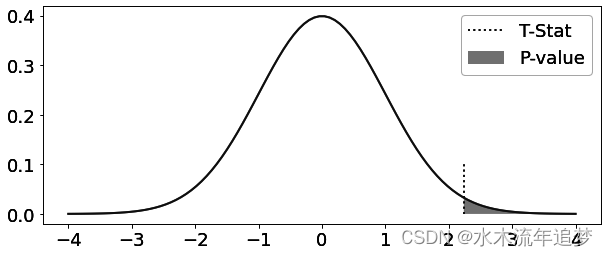
要得到p值,你所需要做的就是计算标准正态分布中,在单侧零假设(“差异大于x”或“差异小于x”)的检验统计量之前的面积,并对于双侧零假设(“差异等于x”),将结果乘以2:
print("p-value:", (1 - stats.norm.cdf(t_stat))*2)
P-value: 0.025224235562152142p值之所以有趣,是因为它使你免去了指定置信水平的需要,如95%或99%。但是,如果你想报告一个置信水平,从p值中,你可以确切知道你的检验将在哪个置信水平上通过或失败。例如,具有0.025的p值,你的显著性可达2.5%的水平。因此,虽然差异的95%置信区间不会包含零,但99%的置信区间将会包含。这个p值也意味着,如果差异真正为零,观察到如此极端的检验统计量的概率只有2.5%。
Power
到目前为止,你从一个数据分析师的角度研究了这些统计概念,他被给予了一项现有测试的数据。你把数据视为已定的。但如果要求你设计一项实验而不是仅仅解读已经设计好的实验呢?在这种情况下,你需要决定每个变体的样本量。例如,如果你还没有运行交叉销售电子邮件实验,而是需要决定给多少客户发送长邮件,多少客户发送短邮件,以及完全不发邮件的数量是多少?
从这个角度来看,目标是拥有足够大的样本,以便在零假设实际上为假的情况下正确地拒绝它。测试正确拒绝零假设的概率被称为测试的效能(power)。这不仅是在确定实验所需的样本量时一个有用的概念,也是在检测运行不良的实验中的问题时的一个重要概念。
效能与统计显著性密切相关。虽然α是当零假设实际上是真时拒绝它的概率,但效能(1-β)是当零假设为假时拒绝它的概率。在某种程度上,效能也由α定义,因为为了正确地拒绝零假设,你需要指定你拒绝它所需要的证据量。
回想一下,95%的置信区间意味着95%的实验将包含你试图估计的真实参数。这也意味着5%的实验不会包含真实参数,这会导致你5%的时间错误地拒绝零假设。在α=0.05的情况下,你所需要的是参数估计和零假设之间的差异δ至少要离零1.96倍的标准误差(SE)远,才能得出它是统计上显著的结论。这是因为δ-1.96SE是95%置信区间的低端。
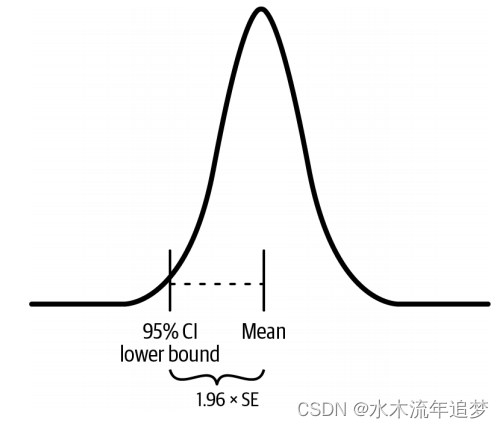
好的,所以你需要δ-1.96SE>0才能声称结果是显著的。但是,看到这种显著差异的可能性有多大呢?这就是你考虑效能的时候了。效能是正确拒绝零假设的概率,即1-β,其中β是在零假设为假时没有拒绝它的概率(假阴性的概率)。行业标准的效能是80%,这意味着你只有20%(β=0.2)的机会,在零假设确实为假时不拒绝它。为了达到80%的效能,你需要在零假设为假时80%的时间内拒绝它。既然拒绝零假设意味着δ-1.96SE>0,你就需要80%的时间内获得这么大的差异。换句话说,你需要80%的时间让95%置信区间的低端超过零。
值得注意(或不值得)的是,95%置信区间的低端也遵循正态分布。就像样本平均数的分布一样,95%CI低端的分布也有等于SE的方差,但现在均值是δ-1.96SE。它只是样本平均数分布的平移版,移动了1.96SE的距离。
因此,为了在80%的时间里(80%的效能)有δ-1.96SE>0,你需要差异至少离零1.96+0.84SE远:1.96是为了给你95%的置信区间,而0.84是为了让那个区间的低端80%的时间落在零以上。这里0.84是与标准正态分布的第80百分位点相对应的z值,确保了在零假设为假的情况下,你有80%的概率拒绝零假设。这在规划实验时非常重要,因为它帮助你确定为了实现所需效能水平所需的样本量。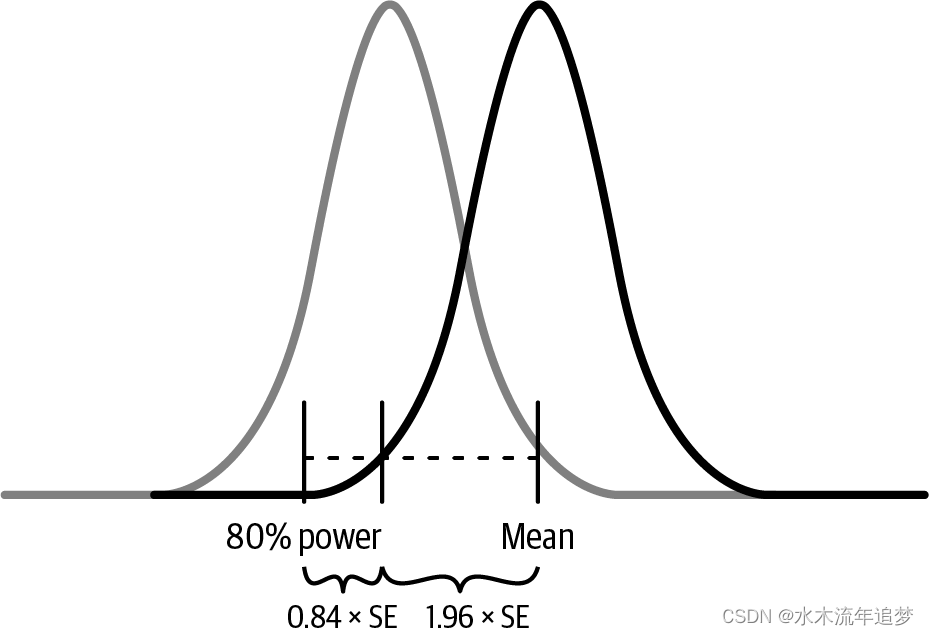
















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











