






练习的时候使用linux+ipython,ipython安装
python的元字符
# 元字符 :
# . ^ $ * + ? {} [] \ | ()

注:\w还可以匹配下划线和汉字
[ab\d]表示只要匹配该集合中的任一一个表达式都OK
注意并不是按照集合的顺序来匹配的。而是返回第一个符合条件的字符串


注:^$匹配的是行首和行尾, \A\Z匹配的是字符串的首尾【没整没明白】

*? +? ??
首先明确一点,他们必须结合左右的正则进行匹配,左边必须有内容,右边可以没有,即为''
?? =(匹配字符1?)?匹配字符2, 字符1{0,1}+字符2, 字符1出现次数<=1,字符2出现次数>=1
In [149]: re.match(r'\w??\d','123wer123') # 第一个\d即数字之前,\w匹配最少可以一次都不匹配,返回第一个数字
Out[149]: <re.Match object; span=(0, 1), match='1'>
In [150]: re.match(r'\w??\d','w123wer123') # 第一个\d数字之前,\w最少可以只匹配一次,返回一个字母+第一个数字
Out[150]: <re.Match object; span=(0, 2), match='w1'>
In [151]: re.match(r'\w??\d','wx123wer123') # 第一个\d数字之前,\w最少会匹配超过一次,最终匹配失败,返回None
In [152]: re.match(r'\w??\d','wxwer') #\d没匹配到,所以最终匹配失败,返回None
In [153]: re.match(r'\w??','wxwer') # 在第一个''之前,\w最少可以只匹配0次,最多匹配1次, 非贪婪模式选择最少匹配次数,\w匹配0次,所以返回''
Out[153]: <re.Match object; span=(0, 0), match=''>
*? = 其实可以拆分看 字符1*?字符2,相当于 (字符1*)?字符2, 字符1{0,}+第一个字符2, 字符1次数>=0,字符2出现次数>=1
In [154]: re.match(r'\w*?\d','123wer123') # \w匹配0次,返回第一个数字
Out[154]: <re.Match object; span=(0, 1), match='1'>
In [155]: re.match(r'\w*?\d','wx123wer123') # \w匹配2次, 返回2个字母+一个数字
Out[155]: <re.Match object; span=(0, 3), match='wx1'>
In [156]: re.match(r'\w*?\d','wxe') # \d没有匹配项,最终匹配失败,返回None In [157]: re.match(r'\w*?','wxe') # 遇到第一个''之前\w可以最多匹配三个,最少可以一次都不匹配,非贪婪模式按\w匹配次数最少的来, \w匹配0次,最终返回'' Out[157]: <re.Match object; span=(0, 0), match=''>
+?=(字符1+)?字符2, 字符1{1,}+第一个字符2, 字符1出现次数>=1,字符2出现次数>=1
In [160]: re.match(r'\w+?\d','%123wer123') # \w匹配0次,最终匹配失败,返回None
In [161]: re.match(r'\w+?\d','wsx123wer123') #\w匹配3次,最后返回三个字母+第一个数字
Out[161]: <re.Match object; span=(0, 4), match='wsx1'>
In [162]: re.match(r'\w+?\d','wsxwer') # \d匹配0次,最终匹配失败,返回None
In [163]: re.match(r'\w+?','wsxwer') # 遇到第一个''之前,\w在这里最多可以匹配6次,最好必须匹配一次,非贪婪模式就是按最少的次数来,所以返回第一个字母+'',即第一个字母
Out[163]: <re.Match object; span=(0, 1), match='w'>
In [165]: re.match(r'w+?\w','wsxwer') # 注意返回的是ws而不是wsxwe,w+表示w可以出现1到多次,ws中w只匹配一次,wsxwe却匹配了2次,非贪婪模式就是捡w匹配次数最少的来,所以返回ws
Out[165]: <re.Match object; span=(0, 2), match='ws'>
看如下示例应该能更好的理解

理解了*?,+?就更好理解了,单独使用同{1},配合后面的表达式使用的时候意味着如果能匹配到后面的表达式则前面无限长匹配,
如果不能匹配到后面一个表达式则只返回匹配到的第一个字符
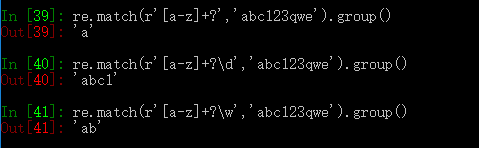

|单独使用只匹配左右紧邻的表达式,可以和()结合使用

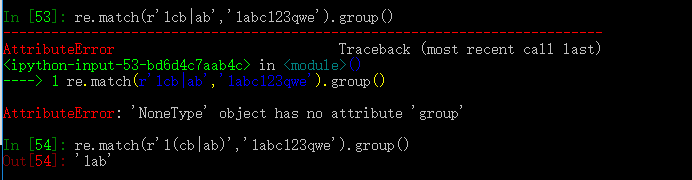
如下示例可以看出分组结合|的妙用, r'1cb|ab' 只能匹配到1cbb和1cab
但是r'1(cb|ab)'则表示匹配1cb和1ab,是把ab和cb当做一个整体
引用编号分组和别名分组,如果分组比较多的时候建议用别名分组

- \元字符 表示匹配元字符本身

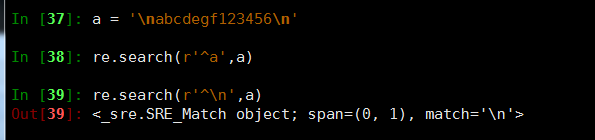
- ^ 脱字符,匹配输入字符串的开始的位置
整个字符串的第一个字符
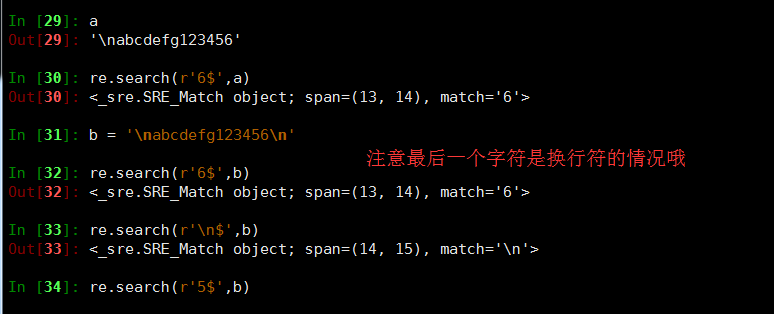
- $ 匹配输入字符串的结束位置
整个字符串结束字符,但如果最后一个是换行符那按照倒数第二个也可以匹配到,当然直接按照换行符也可以匹配到
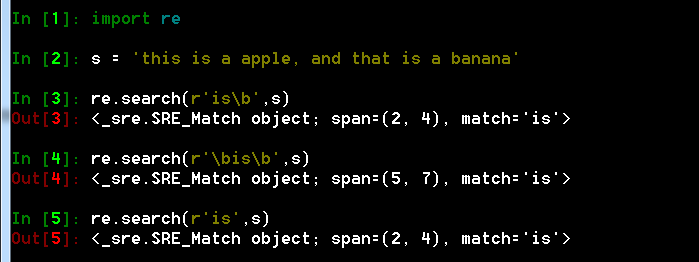
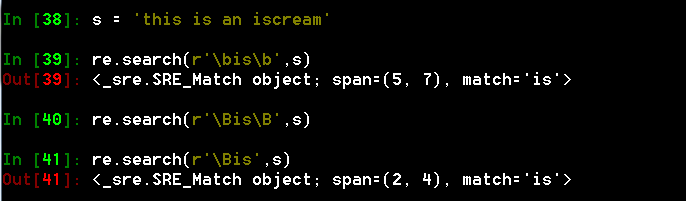
- \b 表示单词的边界,\B与\b相反
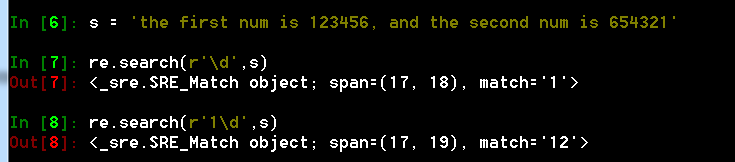
- \d 匹配0~9的数字
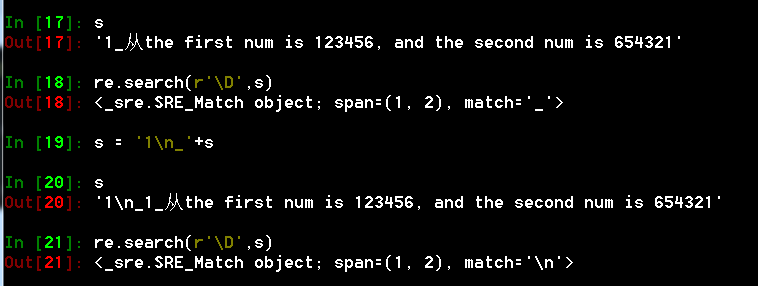
- \D 匹配数字以外的字符
- \w 匹配字母或数字或下划线或汉字等
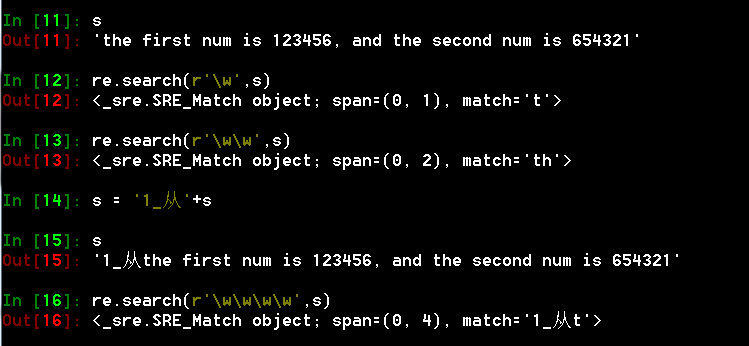
- \W与\w的含义相反,是匹配特殊字符的
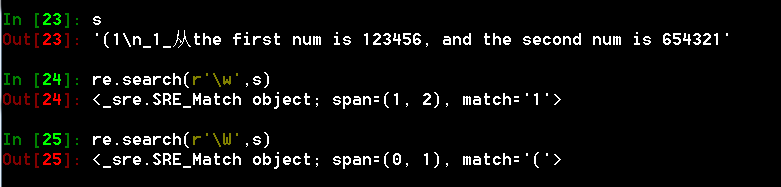
- \s 匹配任意的空白符,包括空格,制表符(Tab),换行符等,\S匹配非空白字符
















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









