







改进算法的常用方法:
1.尝试减少特征的数量
2.尝试获得更多的特征
3.尝试增加多项式特征
4.尝试减少正则化程度?
5.尝试增加正则化程度?
6.尝试获取更多的训练样本
实际情况下不应该随机选择上面的方法,而是用“机器学习诊断法”
机器学习诊断法
这是一种测试法,通过执行这种测试,能够深入了解某种算法到底是否有用,通常也能够告诉我们改进算法应该进行怎样的尝试。
(1)将数据7:3分配为训练集和测试集,注意要随机选择分配。

(2)模型选择,交叉验证:
将数据按照 6:2:2 分配为 训练集,交叉验证集,测试集,


(3) 诊断偏差和方差
偏差大:欠拟合
方差大:过拟合

训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
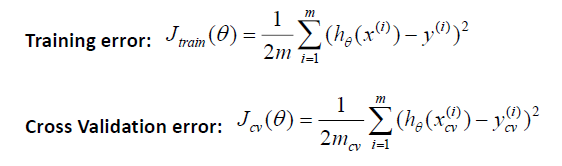
(4)正则化和偏差、方差
?太小:过拟合
?过大:欠拟合(近似一条平滑直线)


验证集模型的代价函数误差与?的值绘制在一张图表上


(5)利用学习曲线来对算法进行合理检验
学习曲线就是将训练集误差和交叉验证集误差作为训练实例数量的函数绘制的图表

在高偏差(欠拟合)的情况下,增加训练集数据(样本数)并不一定有帮助(如下图,训练集数量增加到一定程度之后,误差趋近于一个定值)

在高方差(过拟合)情况下,增加更多训练集数据可能可以提高算法效果。

关于归一化,所有数据集应该都用训练集的均值和样本标准差处理。切记。所以要将训练集的均值和样本标准差存储起来,对后面的数据进行处理。
注意样本标准差不是总体标准差,使用np.std()时,将ddof=1则是样本标准差,默认=0是总体标准差。而pandas默认计算样本标准差。
总结


![]()
机器学习系统设计
(1)误差分析
当要实现一个机器学习的算法时最好的实践方法不是建立一个
非常复杂的系统,拥有很多复杂的变量;而是构建一个简单的算法,可以很快实现它。

![]()
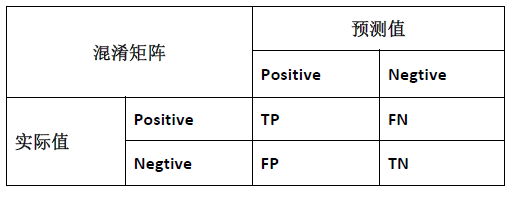
(2)偏斜类误差度量

(注:查全率即为召回率)


















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









