







1. 多线程概念
1.1 进程
进程就是运行起来的可执行程序。
1.2 线程
每个进程,都有唯一的一个主线程;当执行可执行程序时候,产生进程,主线程就跟随进程启动了,主线程和进程是唇齿相依;
线程:用来执行代码的。线程可以理解一条代码的执行通路;
除了主线程之外,可以通过写代码来创建其他线程,其他线程走的是不同道路,甚至去不同的地方。
1.3 多线程理解
单CPU内核的多个线程:一个时间片运行一个线程的代码,并不是真正意义的并行计算。
多个cpu或者多个内核:可以做到真正的并行计算。
2. 多线程使用
2.1 如何创建线程
举个例子,如下图代码所示。
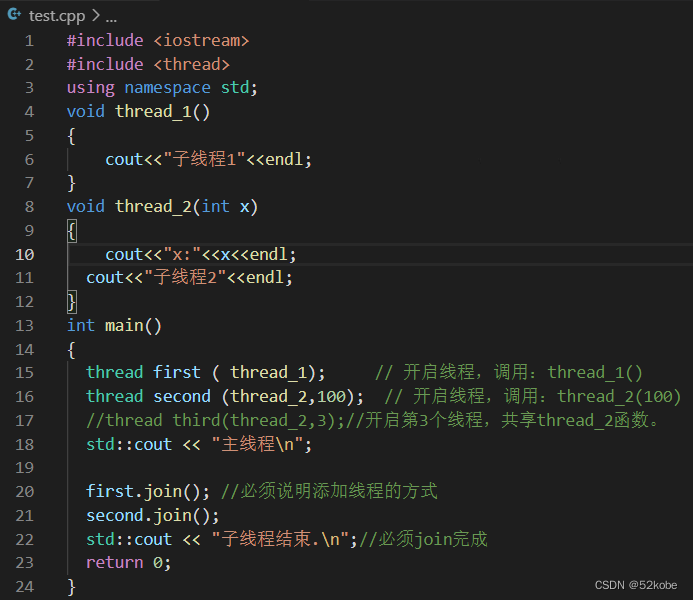
运行结果:

2.2 关于join与detach方式
当线程启动后,一定要在和线程相关联的thread销毁前,确定以何种方式等待线程执行结束。比如上例中的join。
1. detach方式,启动的线程自主在后台运行,当前的代码继续往下执行,不等待新线程结束。
2. join方式,等待启动的线程完成,才会继续往下执行。
以detach方式举个例子:
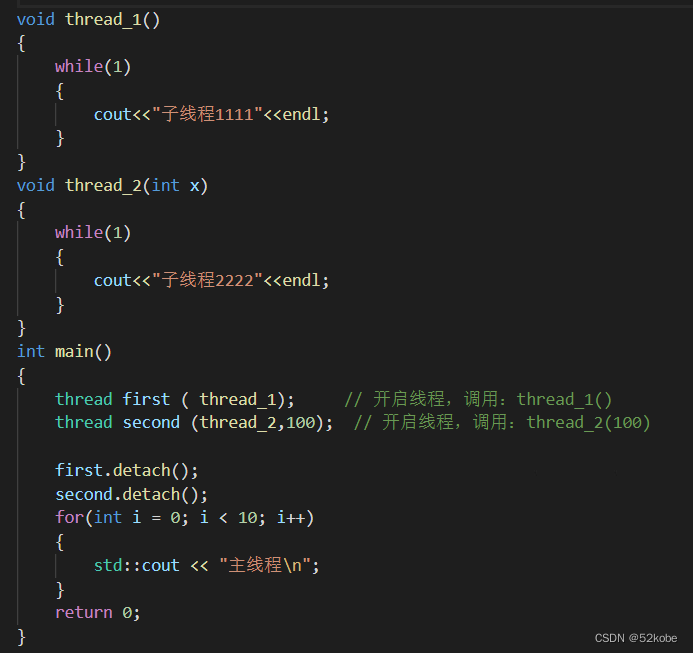
运行结果:
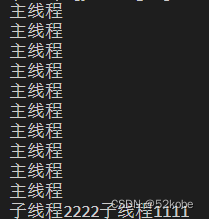
主线程不会等待子线程结束。如果主线程运行结束,程序则结束。
3. 互斥量、锁
3.1 数据共享问题
用代码把共享数据锁住、操作数据、解锁,其他想操作共享数据的线程必须等待解锁、锁住、数据操作、解锁。
如果不加处理:多个线程执行顺序是乱的,跟操作系统内部对线程的运行调度机制有关
多个子线程处理共享数据时候:
1. 只读数据:是安全的
2. 有读有写数据:读的时候不能写,写的时候不能读
3.2 互斥量(mutex)的概念
1. 互斥量就是个类对象,可以理解为一把锁,多个线程尝试用lock()成员函数来加锁,只有一个线程能锁定成功;如果没有锁成功,那么流程将卡在lock()这里不断尝试去锁定。
2.互斥量使用要小心,保护数据不多也不少,少了达不到效果,多了影响效率。
3.3 使用方法
对于共享有读有写数据,需要在某个线程处理时候加锁限制;
lock与unlock
mutex常用操作:
lock(): 资源上锁
unlock(): 解锁资源
trylock(): 查看是否上锁,它有下列3种情况:
1. 未上锁返回false, 并锁住;
2. 其他线程已经上锁,返回true;
3.同一个线程已经对它上锁,将会产生死锁;
3.4 死锁
指两个或两个以上的进程的执行过程中,由于竞争资源或者彼此通信而造成的一种阻塞现象,若无外力作用,它们都将无法推进下去。此时系统处于死锁状态或者系统产生了死锁,永远处于互相等待的进程称为死锁进程。
举个例子对lock和unlock说明。
同一个mutex变量上锁之后,一个时间段内,只允许一个线程访问它。例如:

如果是不同的mutex变量,因为不涉及到同一个资源的竞争,所以下列代码运行可能会出现交替打印的情况,或者另一个线程可以修改共同的全局变量。
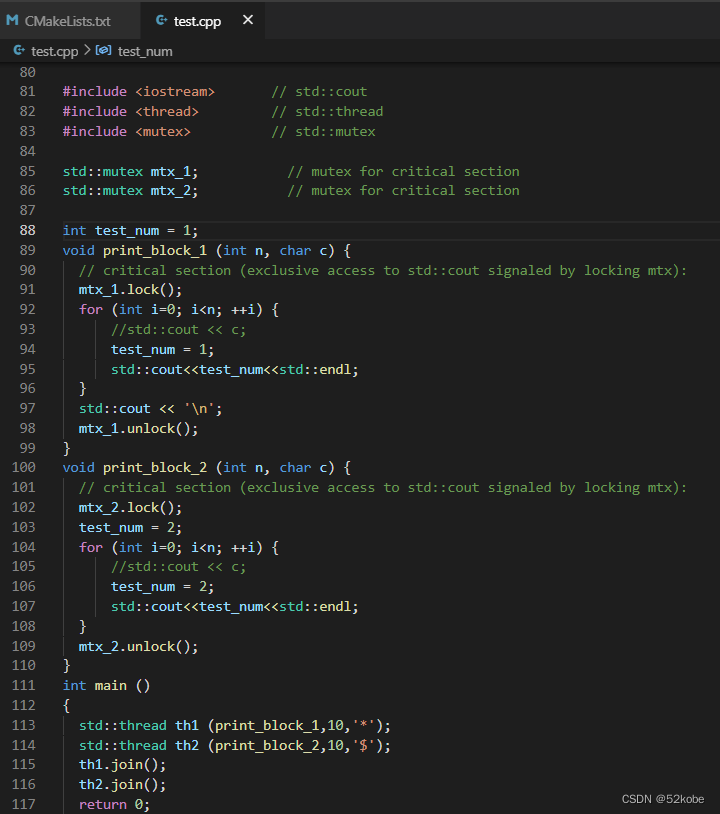
输出结果:
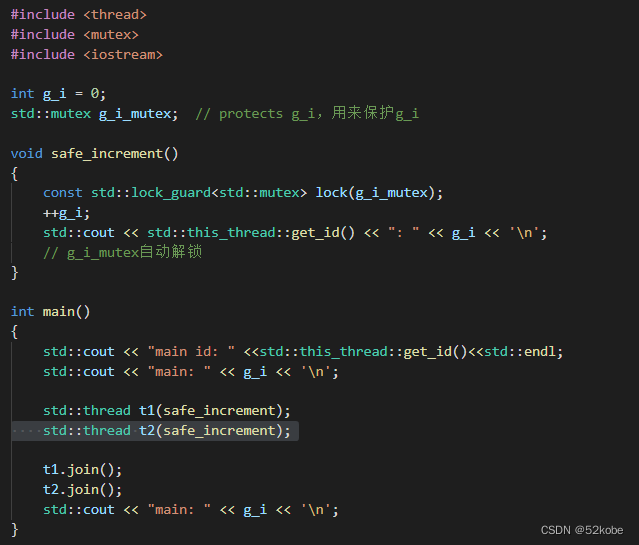
3.5 lock_guard
创建lock_guard对象时,它将尝试获取提供给它的互斥锁的所有权。当控制流离开lock_guard对象的作用域时,lock_guard析构并释放互斥量。
lock_guard的特点:
1. 创建即加锁,作用域结束自动析构并解锁,无需手工解锁。
2. 不能中途解锁,必须等作用域结束才解锁。
3. 不能复制。
运行结果如下:
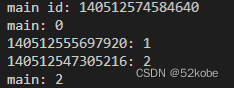
根据结果分析:
- 该程序的功能为,每经过一个线程,g_i 加1。
- 因为涉及到共同资源g_i ,所以需要一个共同mutex:g_i_mutex。
- main线程的id为0,所以下次的线程id依次加1。
3.6 unique_lock
unique_lock 是 lock_guard 的升级加强版,它具有 lock_guard 的所有功能,同时又具有其他很多方法,使用起来更强灵活方便,能够应对更复杂的锁定需要。
unique_lock的特点:
1. 创建时可以不锁定(通过指定第二个参数为std::defer_lock),而在需要时再锁定
2. 可以随时加锁解锁
3. 作用域规则同 lock_grard,析构时自动释放锁
4. 不可复制,可移动
5. 条件变量需要该类型的锁作为参数
所有 lock_guard 能够做到的事情,都可以使用 unique_lock 做到,反之则不然。那么何时使lock_guard呢?很简单,需要使用锁的时候,首先考虑使用 lock_guard,因为lock_guard是最简单的锁。

运行结果如下所示:















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









