






 本文介绍了如何优化GPU计算性能,着重于减少主机和GPU间的数据传输时间。通过使用nvprof工具测量传输时间,遵循减少传输量、使用固定内存、批处理小传输等策略,可以显著提升效率。此外,文章还强调了在评估GPU代码性能时,必须考虑数据传输成本,而不仅仅是内核执行时间。
本文介绍了如何优化GPU计算性能,着重于减少主机和GPU间的数据传输时间。通过使用nvprof工具测量传输时间,遵循减少传输量、使用固定内存、批处理小传输等策略,可以显著提升效率。此外,文章还强调了在评估GPU代码性能时,必须考虑数据传输成本,而不仅仅是内核执行时间。
设备内存和GPU之间的峰值带宽(例如,在NVIDIA Tesla C2050上为144 GB / s)比主机内存和设备内存之间的峰值带宽(在PCIe x16 Gen2上为8 GB / s)高得多。这种差异意味着在主机和GPU设备之间进行数据传输可能会影响或破坏整体的应用程序性能。
首先,让我们了解主机-设备之间数据传输的一些基本准则。
(1)尽可能减少在主机和设备之间传输的数据量,即使这意味着与在主机CPU上运行相比,在GPU上运行内核的速度几乎没有提高。
(2)使用页面锁定(或“固定”)内存时,主机与设备之间可能会有更高的带宽。
(3)将许多小型传输分批成一个较大的传输的性能要好得多,因为它消除了大多数每次传输的开销。
(4)有时,主机和设备之间的数据传输可能会与内核执行和其他数据传输重叠。
1、使用nvprof测量数据传输时间
为了测量每次数据传输所花费的时间,我们可以在每次传输之前和之后记录一个CUDA事件,并使用cudaEventElapsedTime()函数获取所花费的时间。
但是,通过使用nvprof(CUDA工具包附带的命令行CUDA探查器)(从CUDA 5开始),我们可以获得经过的传输时间,而无需使用CUDA事件来对源代码进行检测。
具体示例如下:

要分析此代码,我们使用nvcc对其进行编译,然后使用程序文件名作为参数运行nvprof。
定位到cuda原文件目录下,使用 nvcc -o test.exe test.cu 来变异cuda程序。
使用 nvprof test.exe 执行cuda程序
当我在装有GeForce GTX 1060的笔记本上运行时,得到以下输出。我所使用的平台是Windows
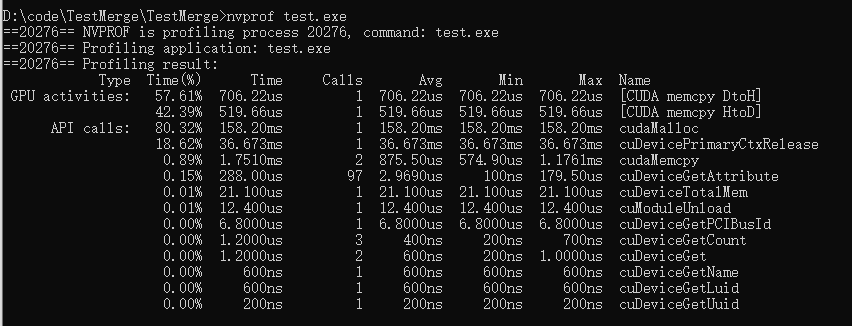
如你所见,nvprof 测量每个CUDA memcpy调用所花费的时间。 它报告每个调用的平均,最小和最大时间。
2、最小化数据传输
我们不应该仅使用内核的GPU执行时间(相对于其CPU实现的执行时间)来决定运行GPU还是CPU版本。
我们还需要考虑在PCI-e总线上移动数据的成本,特别是在我们最初将代码移植到CUDA时。
由于CUDA的异构编程模型同时使用CPU和GPU,因此可以一次将代码移植到CUDA一个内核。
在移植的初始阶段,数据传输可能会主导整个执行时间。将数据传输所花费的时间与内核执行所花费的时间分开进行记录是值得的。
正如我们已经演示的,使用命令行事件探查器很容易。 随着我们移植更多代码,我们将删除中间传输并相应地减少总体执行时间。
3、固定主机内存
默认情况下,主机(CPU)数据分配是可分页的。 GPU无法直接从可分页的主机内存访问数据,因此,当调用从可分页的主机内存到设备内存的数据传输时,CUDA程序必须先分配一个临时的页面锁定或“固定”的主机阵列,才能复制主机数据到固定阵列,然后将数据从固定阵列传输到设备内存,如下所示。

如图所示,固定内存用作从设备到主机的传输的暂存区域。
通过直接在固定内存中分配主机阵列,我们可以避免在可分页和固定主机阵列之间进行传输的开销。
使用cudaMallocHost() 或 cudaHostAlloc() 在CUDA C / C ++中分配固定的主机内存,并使用cudaFreeHost() 释放分配的资源。
固定的内存分配可能会失败,因此需要检查错误。
使用错误检查分配固定内存的方法示例
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes);
if (status != cudaSuccess)
printf("Error allocating pinned host memory\n");使用主机固定内存的数据传输与使用可分页内存的数据传输语法相同,都是使用 cudaMemcpy() 函数。
我们用以下的示例来比较可分页和固定的传输速率。

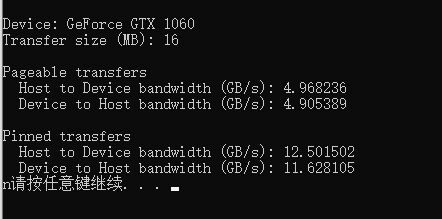
数据传输速率取决于主机系统的类型(主板,CPU和芯片组)以及GPU。
在我的笔记本上执行,数据传输的带宽基本上提升了2.5倍以上。
虽然这种方法可以提升速度,但是也不能过度的分配固定内存。 这样做会降低整体系统性能,因为它会减少可用于操作系统和其他程序的物理内存量。
4、批处理小型数据传输
由于每次传输都会产生开销,因此最好将许多小传输分批处理成单个传输。 这可以通过使用临时数组(最好是固定的)并将其与要传输的数据打包在一起来轻松实现。
对于二维数组传输,可以使用cudaMemcpy2D()。
cudaMemcpy2D(dest, dest_pitch, src, src_pitch, w, h, cudaMemcpyHostToDevice)第一个参数:指目标数据的指针
第二个参数:目标数组的间距
第三个参数:指向源数据的指针
第四个参数:源数组的间距
第五个参数:要传递的子矩阵的宽度
第六个参数:要传递的子矩阵的高度
第七个参数:拷贝的方向(从主机到设备或者从设备到主机)
还有一个 cudaMemcpy3D() 函数用于传输3维数组。
5、总结
主机和设备之间的传输是GPU计算中涉及的数据移动的最慢环节,因此应注意尽量减少数据传输。遵循这篇文章中的准则可以帮助您确保必要的传输是有效的。建议不要使用带有CUDA事件或其他计时器的工具代码来测量每次传输所花费的时间,建议使用nvprof,命令行CUDA分析器或一种视觉分析工具,例如NVIDIA Visual Profiler(也包括在内) 使用CUDA工具包。

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









