






设备内存和 GPU 之间的峰值带宽(例如,在 NVIDIA Tesla C2050 上为 144 GB/s)远高于主机内存和设备内存之间的峰值带宽(在 PCIe x16 Gen2 上为 8 GB/s)。这种差异意味着您在主机和 GPU 设备之间实现数据传输可能破坏您的整体应用程序性能。主机设备数据传输的一些通用策略如下:
- 尽可能减少主机和设备之间传输的数据量;
- 使用页面锁定(“pinned”)内存时,主机和设备之间可能会有更高的带宽;
- 增大批传输的数量,可以消除大部分每次传输的开销;
- 主机和设备之间的数据传输有时会与内核执行和其他数据传输重叠。
在对以上策略展开介绍之前,首先给出如何在不修改源代码的情况下测量数据传输所花费的时间。
1. 使用 nvprof 测量数据传输时间
为了测量每次数据传输所花费的时间,我们可以在每次传输之前和之后记录一个 CUDA 事件,并调用 cudaEventElapsedTime()。 但是,我们可以通过使用 nvprof(CUDA 工具包中包含的命令行 CUDA 分析器(从 CUDA 5 开始))来获取传输花费的时间,而无需使用 CUDA 事件检测源代码。 示例如下,完整代码可见 Github 示例。
int main()
{
const unsigned int N = 1048576;
const unsigned int bytes = N * sizeof(int);
int *h_a = (int*)malloc(bytes);
int *d_a;
cudaMalloc((int**)&d_a, bytes);
memset(h_a, 0, bytes);
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(h_a, d_a, bytes, cudaMemcpyDeviceToHost);
return 0;
}使用nvcc 对其进行编译,然后使用程序文件名作为参数运行 nvprof。
$ nvcc profile.cu -o profile_test
$ nvprof ./profile_test在配备 GeForce GTX 680(GK104 GPU,类似于 Tesla K10)的机器上运行,结果如下:
$ nvprof ./a.out
======== NVPROF is profiling a.out...
======== Command: a.out
======== Profiling result:
Time(%) Time Calls Avg Min Max Name
50.08 718.11us 1 718.11us 718.11us 718.11us [CUDA memcpy DtoH]
49.92 715.94us 1 715.94us 715.94us 715.94us [CUDA memcpy HtoD]如您所见,nvprof 测量每个 CUDA memcpy 调用所花费的时间。 它统计每次调用的平均、最短和最长时间(因为每个副本我们只运行一次,所以所有时间都是相同的)。 nvprof 非常灵活,详见官方文档。
2. 最小化数据传输
我们不应该根据内核的 GPU 执行时间相对于其 CPU 实现的执行时间来决定是运行 GPU 还是 CPU 版本。 我们还需要考虑跨 PCI-e 总线传输数据的成本,尤其是当我们最初将代码移植到 CUDA 时。 由于 CUDA 的异构编程模型同时使用 CPU 和 GPU,代码可以一次移植一个内核。 在移植的初始阶段,数据传输可能会占据大部分的执行时间,因此有必要将数据传输和内核执行分开进行。随着我们移植更多代码,我们将移除中间传输并相应地减少整体执行时间。
3. 主机锁页内存
默认情况下,主机 (CPU) 数据分配是可分页的。 GPU 不能直接从可分页主机内存访问数据,因此当调用从可分页主机内存到设备内存的数据传输时,CUDA 驱动程序必须首先分配一个临时页锁定或“pinned”主机数组,复制主机数据到pinned数组,然后将数据从pinned数组传输到设备内存,如下图所示。
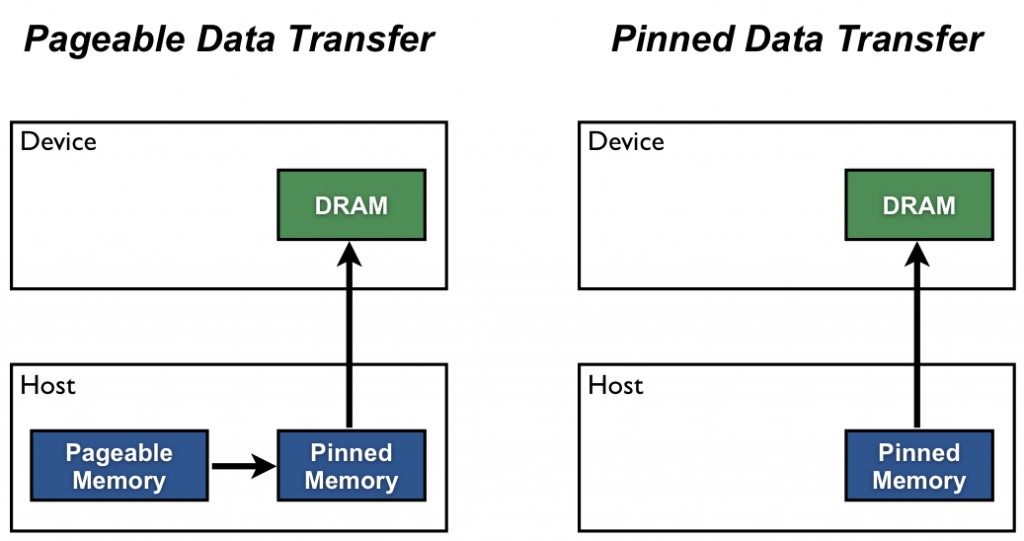
如图所示,固定内存用作从设备到主机传输的暂存区。 我们可以通过直接在固定内存中分配我们的主机数组来避免可分页和固定主机数组之间的传输成本。 在 CUDA C/C++ 中使用 cudaMallocHost() 或 cudaHostAlloc() 分配固定的主机内存,并使用 cudaFreeHost() 释放它。 固定内存分配可能会失败,因此您应该始终检查错误。 以下代码摘录演示了使用错误检查的分配固定内存。
cudaError_t status = cudaMallocHost((void**)&h_aPinned, bytes);
if (status != cudaSuccess)
printf("Error allocating pinned host memory\n");使用主机固定内存的数据传输与使用可分页内存的数据传输都是通过 cudaMemcpy() 实现的。 我们可以使用下面的“bandwidthtest”程序(也可以在 Github 上找到)来比较可分页内存和固定内存的传输速率。
#include <stdio.h>
#include <assert.h>
// Convenience function for checking CUDA runtime API results
// can be wrapped around any runtime API call. No-op in release builds.
inline
cudaError_t checkCuda(cudaError_t result)
{
#if defined(DEBUG) || defined(_DEBUG)
if (result != cudaSuccess) {
fprintf(stderr, "CUDA Runtime Error: %s\n",
cudaGetErrorString(result));
assert(result == cudaSuccess);
}
#endif
return result;
}
void profileCopies(float *h_a,
float *h_b,
float *d,
unsigned int n,
char *desc)
{
printf("\n%s transfers\n", desc);
unsigned int bytes = n * sizeof(float);
// events for timing
cudaEvent_t startEvent, stopEvent;
checkCuda( cudaEventCreate(&startEvent) );
checkCuda( cudaEventCreate(&stopEvent) );
checkCuda( cudaEventRecord(startEvent, 0) );
checkCuda( cudaMemcpy(d, h_a, bytes, cudaMemcpyHostToDevice) );
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
float time;
checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) );
printf(" Host to Device bandwidth (GB/s): %f\n", bytes * 1e-6 / time);
checkCuda( cudaEventRecord(startEvent, 0) );
checkCuda( cudaMemcpy(h_b, d, bytes, cudaMemcpyDeviceToHost) );
checkCuda( cudaEventRecord(stopEvent, 0) );
checkCuda( cudaEventSynchronize(stopEvent) );
checkCuda( cudaEventElapsedTime(&time, startEvent, stopEvent) );
printf(" Device to Host bandwidth (GB/s): %f\n", bytes * 1e-6 / time);
for (int i = 0; i < n; ++i) {
if (h_a[i] != h_b[i]) {
printf("*** %s transfers failed ***\n", desc);
break;
}
}
// clean up events
checkCuda( cudaEventDestroy(startEvent) );
checkCuda( cudaEventDestroy(stopEvent) );
}
int main()
{
unsigned int nElements = 4*1024*1024;
const unsigned int bytes = nElements * sizeof(float);
// host arrays
float *h_aPageable, *h_bPageable;
float *h_aPinned, *h_bPinned;
// device array
float *d_a;
// allocate and initialize
h_aPageable = (float*)malloc(bytes); // host pageable
h_bPageable = (float*)malloc(bytes); // host pageable
checkCuda( cudaMallocHost((void**)&h_aPinned, bytes) ); // host pinned
checkCuda( cudaMallocHost((void**)&h_bPinned, bytes) ); // host pinned
checkCuda( cudaMalloc((void**)&d_a, bytes) ); // device
for (int i = 0; i < nElements; ++i) h_aPageable[i] = i;
memcpy(h_aPinned, h_aPageable, bytes);
memset(h_bPageable, 0, bytes);
memset(h_bPinned, 0, bytes);
// output device info and transfer size
cudaDeviceProp prop;
checkCuda( cudaGetDeviceProperties(&prop, 0) );
printf("\nDevice: %s\n", prop.name);
printf("Transfer size (MB): %d\n", bytes / (1024 * 1024));
// perform copies and report bandwidth
profileCopies(h_aPageable, h_bPageable, d_a, nElements, "Pageable");
profileCopies(h_aPinned, h_bPinned, d_a, nElements, "Pinned");
printf("n");
// cleanup
cudaFree(d_a);
cudaFreeHost(h_aPinned);
cudaFreeHost(h_bPinned);
free(h_aPageable);
free(h_bPageable);
return 0;
}数据传输速率取决于主机系统(主板、CPU 和芯片组)以及 GPU 的类型。 在配备 Intel Core i7-2620M CPU(2.7GHz,2 个 Sandy Bridge 内核,4MB L3 缓存)和 NVIDIA NVS 4200M GPU(1 Fermi SM,Compute Capability 2.1,PCI-e Gen2 x16)的笔记本电脑上,运行 BandwidthTest 的结果如下。 如您所见,固定传输的速度是可分页传输的两倍多。
Device: NVS 4200M
Transfer size (MB): 16
Pageable transfers
Host to Device bandwidth (GB/s): 2.308439
Device to Host bandwidth (GB/s): 2.316220
Pinned transfers
Host to Device bandwidth (GB/s): 5.774224
Device to Host bandwidth (GB/s): 5.958834在我的台式电脑上,配备更快的 Intel Core i7-3930K CPU(3.2 GHz,6 个 Sandy Bridge 内核,12MB L3 缓存)和 NVIDIA GeForce GTX 680 GPU(8 个 Kepler SM,Compute Capability 3.0),我们可以看到更快的可分页传输, 输出如下所示。 这大概是因为更快的 CPU(和芯片组)降低了主机端内存复制成本。
Device: GeForce GTX 680
Transfer size (MB): 16
Pageable transfers
Host to Device bandwidth (GB/s): 5.368503
Device to Host bandwidth (GB/s): 5.627219
Pinned transfers
Host to Device bandwidth (GB/s): 6.186581
Device to Host bandwidth (GB/s): 6.670246固定内存的分配也不是越多越好,这样做会降低整体系统性能,因为它会减少操作系统和其他程序可用的物理内存量。 很难提前知道多少是太多,因此与所有优化一样,可以测试您的应用程序和它们运行的系统以获得最佳性能参数。
4. 批量数据传输
由于每次传输都会带来一些额外的开销,因此最好将多次的传输聚合成一次大的传输。 这可以通过使用临时数组(最好是pinned)并将其与要传输的数据一起打包来实现。
对于二维数组传输,可以使用 cudaMemcpy2D()。
cudaMemcpy2D(dest, dest_pitch, src, src_pitch, w, h, cudaMemcpyHostToDevice)这里的参数是指向第一个目标元素的指针和目标数组的间距、指向第一个源元素的指针和源数组的间距、要传输的子矩阵的宽度和高度以及 memcpy 类型。 还有一个 cudaMemcpy3D() 函数用于传输三级数组部分。
5. 数据传输重叠
数据传输重叠的对象包括主机端的计算、设备端的计算和其他主机设备间的数据传输。为了实现重叠,需要使用CUDA streams,下面将对stream进行介绍。
5.1 CUDA Streams
CUDA 中的stream是按照主机代码发出的顺序在设备上执行的一系列操作。 虽然流中的操作保证按规定的顺序执行,但不同流中的操作可以交错,并且在可能的情况下,它们甚至可以同时运行。
5.1.1 default stream
CUDA 中的所有设备操作(内核和数据传输)都在流中运行。 如果未指定流,则使用默认流(也称为“空流”)。 默认流与其他流不同,因为它是关于设备上的操作的同步流:默认流中的任何操作将在设备上任何流中的所有先前发出的操作都完成之前开始,并且默认流中的操作必须在任何其他操作(在设备上的任何流中)开始之前完成。
请注意,2015 年发布的 CUDA 7 引入了一个新选项,可以为每个主机线程使用单独的默认流,并将每个线程的默认流视为常规流(即它们不与其他流中的操作同步)。
让我们看一些使用默认流的简单代码示例,并从主机和设备的角度讨论操作如何进行。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);在上面的代码中,从设备的角度来看,三个操作都发送到同一个(默认)流,并将按照它们发出的顺序执行。
从主机的角度来看,隐式数据传输是阻塞或同步传输,而内核启动是异步的。 由于第一行的主机到设备的数据传输是同步的,所以在主机到设备的传输完成之前,CPU 线程不会到达第二行的内核调用。 一旦内核发布,CPU 线程移动到第三行,但由于设备端执行顺序,该行上的传输无法开始。
从主机的角度来看,内核启动的异步行为使得设备和主机计算重叠非常简单。 我们可以修改代码以添加一些独立的 CPU 计算,如下所示。
cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice);
increment<<<1,N>>>(d_a)
myCpuFunction(b)
cudaMemcpy(a, d_a, numBytes, cudaMemcpyDeviceToHost);在上面的代码中,只要在设备上启动 increment() 内核,CPU 线程就会执行 myCpuFunction(),将其在 CPU 上的执行与 GPU 上的内核执行重叠;后续的设备到主机传输,只会在内核完成后开始。 从设备的角度来看,与前面的示例没有任何变化; 设备完全不知道 myCpuFunction()。
5.1.2 Non-default streams
CUDA C/C++ 中的非默认流在主机代码中声明、创建和销毁,如下所示。
cudaStream_t stream1;
cudaError_t result;
result = cudaStreamCreate(&stream1)
result = cudaStreamDestroy(stream1)为了向非默认流发出数据传输,我们使用 cudaMemcpyAsync() 函数,它类似于上一篇文章中讨论的 cudaMemcpy() 函数,但将流标识符作为第五个参数。
result = cudaMemcpyAsync(d_a, a, N, cudaMemcpyHostToDevice, stream1)cudaMemcpyAsync() 在主机上是非阻塞的,因此在传输发出后控制立即返回到主机线程。 该方法有 cudaMemcpy2DAsync() 和 cudaMemcpy3DAsync() 变体,它们可以在指定的流中异步传输 2D 和 3D 数组部分。
要将内核发布到非默认流,我们将流标识符指定为第四个执行配置参数(第三个执行配置参数分配共享设备内存,我们稍后会讨论;现在使用 0)。
increment<<<1,N,0,stream1>>>(d_a)5.1.3 streams同步
由于非默认流中的所有操作相对于主机代码都是非阻塞的,因此您将遇到需要将主机代码与流中的操作同步的情况。有几种方法可以做到这一点。 “重锤”方式是使用 cudaDeviceSynchronize(),它会阻塞主机代码,直到设备上所有先前发出的操作都完成。在大多数情况下,这太过分了,并且由于整个设备和主机线程的停顿,确实会损害性能。
CUDA 流 API 有多种不太严格的方法将主机与流同步。函数 cudaStreamSynchronize(stream) 可用于阻塞主机线程,直到指定流中所有先前发出的操作都完成。函数 cudaStreamQuery(stream) 测试是否所有向指定流发出的操作都已完成,而不会阻塞主机执行。函数 cudaEventSynchronize(event) 和 cudaEventQuery(event) 的行为与其对应的流类似,只是它们的结果基于是否记录了指定的事件,而不是指定的流是否空闲。您还可以使用 cudaStreamWaitEvent(event) 在单个流中同步特定事件的操作(即使事件记录在不同的流中,或在不同的设备上!)。
5.2 重叠内核执行和数据传输
之前我们演示了如何将默认流中的内核执行与主机上的代码执行重叠。但我们在这篇文章中的主要目标是向您展示如何将内核执行与数据传输重叠。要做到这一点,有几个要求。
- 设备必须能够“并发复制和执行”。这可以从 cudaDeviceProp 结构的 deviceOverlap 字段中查询,或者从 CUDA SDK/Toolkit中包含的 deviceQuery 示例的输出中查询。几乎所有具有 1.1 及更高计算能力的设备都具有此功能。
- 内核执行和要重叠的数据传输都必须发生在不同的非默认流中。
- 参与数据传输的主机内存必须是固定内存。
因此修改我们的简单主机代码以使用多个流,看看是否可以实现任何重叠。此示例的完整代码可在 Github 上找到。在修改后的代码中,我们将大小为 N 的数组分解为 streamSize 元素的块。由于内核在所有元素上独立运行,因此每个块都可以独立处理。使用的(非默认)流的数量是 nStreams=N/streamSize。有多种方法可以实现数据的域分解和处理:
- 一种是循环遍历数组每个块的所有操作,如本示例代码中所示。
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]);
}- 另一种方法是将类似的操作一起批处理,首先发出所有主机到设备的传输,然后是所有内核启动,最后是所有设备到主机的传输,如以下代码所示。
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset],
streamBytes, cudaMemcpyHostToDevice, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&a[offset], &d_a[offset],
streamBytes, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToHost, stream[i]);
}上面显示的两种异步方法都会产生正确的结果,并且在这两种情况下,相关操作都会按照它们需要执行的顺序发送到同一个流上。 但是这两种方法的执行方式非常不同,具体取决于所使用的特定 GPU 。 在 Tesla C1060(计算能力 1.3)上运行测试代码(来自 Github)给出以下结果。
Device : Tesla C1060
Time for sequential transfer and execute (ms ): 12.92381
max error : 2.3841858E -07
Time for asynchronous V1 transfer and execute (ms ): 13.63690
max error : 2.3841858E -07
Time for asynchronous V2 transfer and execute (ms ): 8.84588
max error : 2.3841858E -07在 Tesla C2050(计算能力 2.0)上,我们得到以下结果。
Device : Tesla C2050
Time for sequential transfer and execute (ms ): 9.984512
max error : 1.1920929e -07
Time for asynchronous V1 transfer and execute (ms ): 5.735584
max error : 1.1920929e -07
Time for asynchronous V2 transfer and execute (ms ): 7.597984
max error : 1.1920929e -07为什么这两种异步策略在不同的架构上表现不同? 为了解读这些结果,我们需要更多地了解 CUDA 设备如何调度和执行任务。 CUDA 设备包含用于各种任务的引擎, 不同引擎中的任务之间存在的依赖关系,但在任何引擎中,所有外部依赖关系都丢失了; 每个引擎队列中的任务按照它们发出的顺序执行。 C1060 有一个拷贝引擎和一个内核引擎。 下图显示了在 C1060 上执行示例代码的时间线。

在示意图中,我们假设主机到设备传输、内核执行和设备到主机传输所需的时间大致相同(选择内核代码是为了实现这一点)。正如对顺序内核所预期的那样,任何操作都没有重叠。对于我们代码的第一个异步版本,复制引擎中的执行顺序是:H2D 流(1)、D2H 流(1)、H2D 流(2)、D2H 流(2),依此类推。这就是为什么我们在 C1060 上使用第一个异步版本时看不到任何加速的原因:任务以排除内核执行和数据传输的任何重叠的顺序发送到复制引擎。然而,对于版本 2,所有主机到设备的传输都在任何设备到主机的传输之前发出,重叠是可能的。从我们的原理图中,我们预计异步版本 2 的执行时间是顺序版本的 8/12,即 8.7 ms,这在前面给出的时序结果中得到了证实。
在 C2050 上与 C1060 的行为不同。 C2050 有两个复制引擎,一个用于主机到设备的传输,另一个用于设备到主机的传输,还有一个内核引擎。下图说明了在 C2050 上执行我们的示例。

拥有两个复制引擎解释了为什么异步版本 1 在 C2050 上实现了良好的加速:stream[i] 中的数据从设备到主机传输不会阻止 stream[i+1] 中数据从主机到设备传输,就像在 C1060 上所做的那样,因为 C2050 上的每个复制方向都有一个单独的引擎。原理图预测执行时间相对于顺序版本将减少一半,这大致是我们的时序结果显示的。
但是,在 C2050 上的异步版本 2 中观察到的性能为什么会下降呢?这与 C2050 并发运行多个内核的能力有关。当多个内核在不同(非默认)流中发出时,调度程序会尝试启用这些内核的并发执行,结果会延迟在每次内核完成后出现的信号(负责启动设备到主机的传输),直到所有内核完成。因此,虽然在我们的异步代码的第二个版本中主机到设备的传输和内核执行之间存在重叠,但内核执行和设备到主机的传输之间没有重叠。示意图预测异步版本 2 的总时间是顺序版本时间的 9/12,即 7.5 ms,我们的时序结果证实了这一点。
CUDA Fortran 异步数据传输中提供了对本文中使用示例的更详细描述。好消息是,对于具有 3.5 计算能力的设备(K20 系列),Hyper-Q 功能消除了定制启动顺序的需要,因此上述任何一种方法都可以工作。我们将在以后的文章中讨论使用 Kepler 功能,但现在,这里是在 Tesla K20c GPU 上运行示例代码的结果。如您所见,两种异步方法都比同步代码实现了相同的加速。
Device : Tesla K20c
Time for sequential transfer and execute (ms): 7.101760
max error : 1.1920929e -07
Time for asynchronous V1 transfer and execute (ms): 3.974144
max error : 1.1920929e -07
Time for asynchronous V2 transfer and execute (ms): 3.967616
max error : 1.1920929e -07翻译自:How to Overlap Data Transfers in CUDA C/C++ | NVIDIA Technical Blog















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









