




题目:Hierarchical Reinforcement Learning for Multi-agent MOBA Game
翻译&重点提炼
Abstact(概述)
实时策略(RTS)游戏需要宏观策略和微观策略才能获得令人满意的效果,因为它具有较大的状态空间,动作空间和隐藏的信息。本文提出了一种新颖的分层强化学习模型,用于掌握多人在线战斗竞技场(MOBA)游戏。所做的贡献是:(1)提出一个层次结构的框架,其中智能体通过模仿学习执行宏观策略,并通过强化学习进行微观操作;(2)开发一种简单的自学习方法来获得更好的训练样本效率; (3)在没有游戏引擎或应用程序编程接口(API)的情况下,为多主体合作设计密集 (dense)奖励函数。最后,已经进行了各种实验以验证所提出的方法相对于其他最新的强化学习算法的优越性能。智能体成功学习了以100%的获胜率战斗和击败铜级内置AI的方法,实验表明,我们的方法可以为5v5模式的移动MOBA游戏《王者荣耀》创建具有竞争力的多智能体。
关键词
- 分层强化学习模型
- 模仿学习
- 自学习方法
- 为多主体合作设计密集 (dense)奖励函数
1.Introduction(介绍)
自从成功玩Atari,AlphaGo,Dota 2等游戏以来,深度强化学习(DRL)已成为游戏AI的有前途的工具。 研究人员通过在游戏中进行实验来快速验证算法,并将此功能转移到现实世界的应用程序中,例如机器人控制,推荐服务。 不幸的是,实践中仍然存在许多挑战。 最近,越来越多的研究人员开始征服更复杂的实时策略(RTS)游戏,例如《星际争霸》和《Data》。Dota是一种多人在线战斗竞技场(MOBA)游戏,其中包括5v5和1v1模式。 为了在MOBA游戏中取得胜利,玩家需要控制自己的唯一一名智能体来摧毁敌人的水晶。
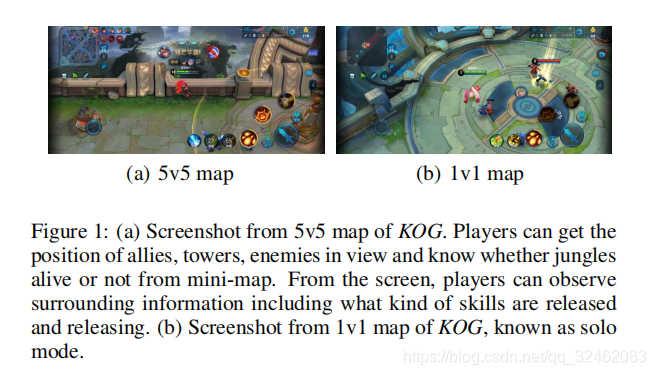
MOBA游戏占据了全世界在线游戏的30%以上,包括英雄联盟,Dota,荣耀之王(KOG)等。 图1a显示了KOG的5v5地图,其中玩家通过控制左下转向按钮来控制英雄的动作,同时通过控制右下按钮组来使用技能。 左上角显示小地图,蓝色标记代表自己的塔,红色标记代表敌人的塔。 每个玩家都可以通过杀死敌人,玩杂耍和摧毁塔来获得金钱和经验。 该游戏的最终目标是消灭敌人的水晶。 如图1b所示,在1v1地图中有两个玩家。
与A
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3174
3174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









