







内容转载自我自己的博客
文章目录
数据库介绍
数据库(Database)指的是以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。这种数据集合具有如下特点:尽可能不重复,以最优方式为某个特定组织的多种应用服务,其数据结构独立于使用它的应用程序,对数据的增、删、改、查由统一软件进行管理和控制。随着计算机在数据管理领域的普遍应用,人们对数据管理技术提出了更高的要求:希望面向企业或部门,以数据为中心组织数据,减少数据的冗余,提供更高的数据共享能力,同时要求程序和数据具有较高的独立性,当数据的逻辑结构改变时,不涉及数据的物理结构,也不影响应用程序,以降低应用程序研制与维护的费用
数据库管理
数据库管理系统(Database Management System)是为管理数据库而设计的电脑软件系统,一般具有存储、截取、安全保障、备份等基础功能
物理结构
数据库的基本结构分三个层次,反映了观察数据库的三种不同角度,不同层次之间的联系是通过映射进行转换的
物理数据层
数据库的最内层,是物理存贮设备上实际存储的数据的集合。这些数据是原始数据,是用户加工的对象,由内部模式描述的指令操作处理的位串、字符和字组成
概念数据层
数据库的中间一层,是数据库的整体逻辑表示。指出了每个数据的逻辑定义及数据间的逻辑联系,是存贮记录的集合。它所涉及的是数据库所有对象的逻辑关系,而不是它们的物理情况,是数据库管理员概念下的数据库
用户数据层
用户所看到和使用的数据库,表示了一个或一些特定用户使用的数据集合,即逻辑记录的集合
逻辑分类
数据库的逻辑结构通常分为层次数据库、网络数据库和关系数据库三种,不同的数据库是按不同的数据结构来联系和组织的
关系数据库
关系数据库(Relational database)是创建在关系模型基础上的数据库。它借助于集合代数等数学概念和方法来处理数据库中的数据。它的模型是把复杂的数据结构归结为简单的二元关系(即二维表格形式)。在关系数据库中,对数据的操作几乎全部建立在一个或多个关系表格上,通过对这些关联的表格分类、合并、连接或选取等运算来实现数据库的管理
数据库表
在关系数据库中,表[关系](Relation)是以列[属性](Attribute)和行[值组](Tuple)的形式组织起来的数据的集合。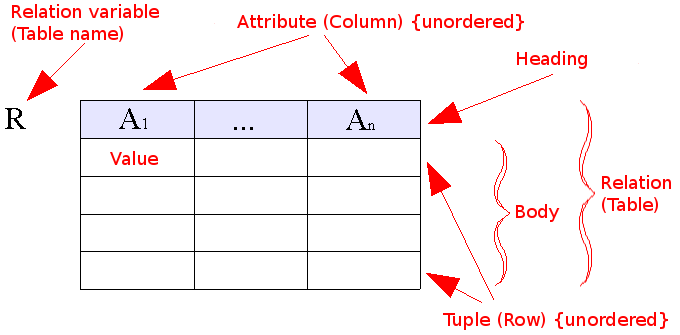
一个数据库包括一个或多个表,数据库表是一系列二维数组的集合。例如,下面是一个包含id、年龄、性别、国家的学生信息表:
| ID | 姓名 | 性别 | 年龄 | 国家 |
|---|---|---|---|---|
| 0 | KangKang | 18 | 男 | 中国 |
| 1 | Maria | 17 | 女 | 古巴 |
| 2 | Michael | 19 | 男 | 美国 |
| 3 | Jane | 16 | 女 | 英国 |
Oracle
Oracle[ˈɒrəkl]数据库(Oracle Database),又名Oracle ![]()
Oracle由至少一个表空间和数据库模式对象组成。模式是对象的集合,而模式对象是直接引用数据库数据的逻辑结构。模式对象包括这样一些结构:表、视图、序列、存储过程、同义词、索引、簇和数据库链等。逻辑存储结构包括表空间、段和范围,用于描述怎样使用数据库的物理空间。
段(Segment)是表空间中一个指定类型的逻辑存储结构,它由一个或多个范围组成,段将占用并增长存储空间
- 数据段:用来存放表数据
- 索引段:用来存放表索引
- 临时段:用来存放中间结果
- 回滚段:用于出现异常时,恢复事务
范围(Extent)是数据库存储空间分配的逻辑单位,一个范围由许多连续的数据块组成,范围是由段依次分配的,分配的第一个范围称为初始范围,以后分配的范围称为增量范围
MySQL
MySQL[maɪˌɛskjuːˈɛl](My Structure Quest Language)原本是一个开放源代码的关系数据库管理系统,使用C和C++编写,后被甲骨文公司(Oracle)收购,成为Oracle旗下产品。MySQL在过去由于性能高、成本低、可靠性好,已经成为最流行的开源数据库,因此被广泛地应用在Internet上的中小型网站中。
随着MySQL的不断成熟,它也逐渐用于更大规模的网站和应用,比如维基百科(维基百科已于2013年正式宣布将从MySQL迁移到MariaDB数据库)、Google和Facebook等网站,非常流行的开源软件组合LAMP(Linux-Apache-MySQL-PHP)中的“M”指的就是MySQL
索引是一种特殊的文件,它们包含着对数据表里所有记录的引用指针。索引不是万能的,它可以加快数据检索操作,但会使数据修改操作变慢。每修改数据记录,索引就必须刷新一次。为了在某种程度上弥补这一缺陷,许多SQL命令都有一个DELAY_KEY_WRITE项。这个选项的作用是暂时制止 MySQL在该命令每插入一条新记录和每修改一条现有之后立刻对索引进行刷新,对索引的刷新将等到全部记录插入/修改完毕之后再进行。在需要把许多新记录插入某个数据表的场合DELAY_KEY_WRITE选项的作用将非常明显。另外,索引还会在硬盘上占用相当大的空间。因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果。从理论上讲,完全可以为数据表里的每个字段分别建一个索引,但MySQL把同一个数据表里的索引总数限制为16个
MariaDB
MariaDB(名称来自Michael Widenius的女儿Maria的名字)数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可。![]()
开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险
MariaDB基于事务的Maria存储引擎,替换了MySQL的MyISAM存储引擎,它使用了Percona的 XtraDB,InnoDB的变体
SQL Server
Microsoft SQL Server是由美国微软公司所推出的关系数据库解决方案,数据库的内置语言原本是采用美国标准局(ANSI)和国际标准组织(ISO)所定义的SQL语言。![]()
SQL Server一开始并不是微软自己研发的产品,而是当时为了要和IBM竞争时,与Sybase合作所产生的,其最早的发展者是Sybase,与Sybase终止合作关系后,SQL Server版本均由微软自行研发
Access
Microsoft Office Access[[ˈækses]是是微软把数据库引擎的图形用户界面和软件开发工具结合在一起的一个关系数据库管理系统。Access能够访问Access/Jet、Microsoft SQL Server、Oracle数据库,或者任何ODBC(Open Database Connectivity)兼容数据库内的数据。虽然它支持部分面向对象技术,但是未能成为一种完整的面向对象开发工具。
它拥有的报表创建功能能够处理任何它能够访问的数据源。Access提供功能参数化的查询,这些查询和Access表格可以被诸如VB6和.NET的其它程序通过DAO或ADO访问;它的数据文件不能突破2G的限制,它的结构化查询语言(JET SQL)能力有限,不适合大型数据库处理应用
键值存储数据库
Key-Value存储,简称KV存储。它是NoSQL存储的一种方式。它的数据按照键值对的形式进行组织,索引和存储。KV存储非常适合不涉及过多数据关系业务关系的业务数据,同时能有效减少读写磁盘的次数,比SQL数据库存储拥有更好的读写性能
Redis
Redis是一个使用ANSI C编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。Redis的外围由一个键、值映射的字典构成。与其他非关系数据库主要不同在于:Redis中值的类型不仅限于字符串,还支持抽象数据类型:字符串列表、无序不重复的字符串集合、有序不重复的字符串集合、键、值都为字符串的哈希表。值的类型决定了值本身支持的操作。Redis支持不同无序、有序的列表,无序、有序的集合间的交集、并集等高级服务器端原子操作。Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助
Memcached
Memcached是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。是Danga Interactive为了LiveJournal所发展的,但被许多软件(如MediaWiki)所使用。这是一套开放源代码软件,以BSD license授权协议发布。Memcached的API使用三十二比特的循环冗余校验(CRC-32)计算键值后,将数据分散在不同的机器上。当表格满了以后,接下来新增的数据会以LRU机制替换掉。由于Memcached通常只是当作缓存系统使用,所以使用Memcached的应用程序在写回较慢的系统时(像是后端的数据库)需要额外的代码更新M
emcached内的数据
文档存储数据库
面向文档的数据库(Document-oriented DataBase)是一种被设计用于储存、检索和管理文档导向信息(也称为“半结构化数据”)的计算机程序。文档导向的数据库是NoSQL数据库的一个主要类别,文档导向的数据库的普及程度已经随着NoSQL本身被不断使用而有所增长。XML数据库是针对XML文件做了优化的文档导向的数据库的子类。文档存储支持对结构化数据的访问,不同于关系模型的是,文档存储没有强制的架构。事实上,文档存储以封包键值对的方式进行存储。在这种情况下,应用对要检索的封包采取一些约定,或者利用存储引擎的能力将不同的文档划分成不同的集合,以管理数据。与关系模型不同的是,文档存储模型支持嵌套结构;与键值存储不同的是,文档存储关心文档的内部结构
MongoDB
MongoDB是一个基于分布式文件存储的数据库,由C++语言编写,旨在为WEB应用提供可扩展的高性能数据存储解决方案。它是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似JSON(JavaScript Object Notation)的BSON(Binary Serialized Document Format)格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它使用内存映射文件, 32位系统上限制大小为2GB的数据(64位支持更大的数据)
CouchDB
Apache CouchDB(Cluster Of Unreliable Commodity Hardware DataBase)是一个开源的面向文档的数据库管理系统,它是一个使用JSON作为存储格式,JavaScript作为查询语言,MapReduce和HTTP作为API的NoSQL数据库。不同于关系型数据库,CouchDB没有将数据和关系存储在表格里。替代的,一个应用程序可能会访问多个数据库,每个数据库是一个独立的文档集合,每一个文档维护其自己独立的数据和自包涵的schema。CouchDB实现了一个多版本并发控制(MVCC)形式,用来避免在数据库写操作的时候对文件进行加锁,冲突留给应用程序去解决。解决一个冲突的通用操作的是首先合并数据到其中一个文档,然后删除旧的数据
列存储数据库
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询;与之对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理
数据库以行、列的二维表的形式存储数据,但是却以一维字符串的方式存储。列式数据库把一列中的数据值串在一起存储起来,然后再存储下一列的数据;行式数据库把一行中的数据值串在一起存储起来,然后再存储下一行的数据
HBase
Apache HBase最初是Powerset公司为了处理自然语言搜索产生的海量数据而开展的项目。不过现在它已经是Apache基金会的顶级项目,它是一个开源的非关系型分布式数据库(NoSQL),参考了谷歌的BigTable建模,实现的编程语言为 Java,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。它在列上实现了BigTable论文提到的压缩算法、内存操作和布隆过滤器。HBase的表能够作为MapReduce任务的输入和输出,可以通过Java API来访问数据,也可以通过REST、Avro或者Thrift的API来访问
Cassandra
Apache Cassandra(社区内一般简称为C*)是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据,是一种流行的分布式结构化数据存储方案。它的数据并不存储在分布式文件系统如GFS或HDFS中,而是直接存于本地
使用了Google 设计的 BigTable的数据模型,与面向行(row)的传统的关系型数据库或键值存储的key-value数据库不同,Cassandra使用的是宽列存储模型(Wide Column Stores),每行数据由row key唯一标识之后,可以有最多20亿个列,每个列由一个column key标识,每个column key下对应若干value。这种模型可以理解为是一个二维的key-value存储,即被定义成一个类似map<key1, map<key2,value>>的类型。它的row key决定了该行数据存储在哪些节点中,因此row key需要按哈希来存储,不能顺序的扫描或读取,而一个row内的column key是顺序存储的,可以进行有序的扫描或范围查找
图数据库
图数据库(Graph database)也可称为面向/基于图的数据库。它的基本含义是以“图”这种数据结构存储和查询数据,不是存储图片的数据库。图数据库的基本存储单元为:节点、关系、属性。实体会被作为顶点,而实体之间的关系则会被作为边
FlockDB
FlockDB是Twitter为进行关系数据分析而构建的。FlockDB迄今为止还没有稳定的版本,对于它是否是一个真正的图形数据库,尚有争议。FlockDB和其它图形数据库(如Neo4j、OrientDB)的区别在于图的遍历,Twitter的数据模型不需要遍历社交图谱
Neo4j
Neo4j是一个流行的图形数据库,它是开源的。最近,Neo4j的社区版已经由遵循AGPL许可协议转向了遵循GPL许可协议。尽管如此,Neo4j的企业版依然使用AGPL许可。Neo4j基于Java实现,兼容ACID特性,也支持其他编程语言,如Ruby和Python
特点
实现数据共享:包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接口使用数据库,并提供数据共享
减少数据的冗余度:由于数据库实现了数据共享,从而避免了用户各自建立应用文件,减少了大量重复数据,减少了数据冗余
数据的独立性:包括逻辑独立性(数据库中数据库的逻辑结构和应用程序相互独立)和物理独立性(数据物理结构的变化不影响数据的逻辑结构)
数据实现集中控制:对数据进行集中控制和管理,并通过数据模型表示各种数据的组织以及数据间的联系
数据一致性和可维护性:防止数据丢失、错误更新和越权使用;保证数据的正确性、有效性和相容性;在同一时间周期内,允许对数据实现多路存取
故障恢复:能尽快恢复数据库系统运行时出现的故障,可能是物理上或是逻辑上的错误















 160
160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









