






文章目录
Vehicle Re-identification with Viewpoint-aware Metric Learning
摘要
- 已有的车辆重识别方法难以处理极端的视角变化问题。
- 受人类对车辆的认知过程的启发,我们提出一种视角感知的度量学习方法:它基于特征空间中的相似或者不同的两种视角分别学习两种不同的度量标准,提出了具备视角感知能力的网络VANet。
- 训练阶段,两种类型的约束被共同采用;测试阶段,先是对视角进行估计,然后采用估计的视角相应的度量标准。
- 实验结果表面VANet显著提升了车辆识别准确率,尤其是在匹配图像对是从不同视角观测而来的时候。
1.引言
- 视角变化问题是车辆重识别过程中的主要挑战。
如图1(a),不同车辆从相似视角里可能看起来很相似,如图1(b),相同车辆从不同视角中则可能看起来差异很大。为简单起见,定义S-view表示相似视角,D-view表示不同视角。
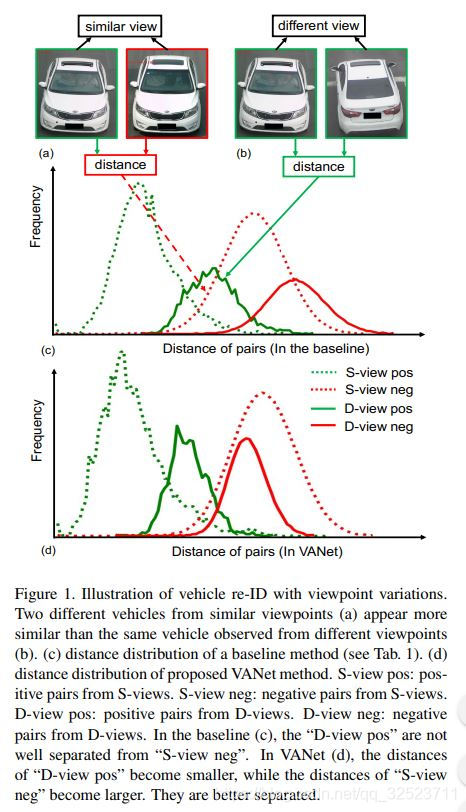
视角变化问题在目标识别领域早已被广泛研究过,比如在行人重识别或者面部识别领域。虽然深度度量学习在视角变化的特征获取研究中已经有一定的成功,但是对于车辆的极端视角变化(比如180°)来说,仍然非常具有挑战性。 - 测试了一个基于深度度量学习的baseline,D-view pos(不同视角的同类样本对)和S-view neg(相似视角的不同样本对)的距离分布如图1(c)所示,经过统计发现相比于S-view neg,D-view pos 的距离往往要更大,这严重降低了重识别的检索精度。
- 文章通过学习具备视角感知能力的度量学习方法来应对上述问题,灵感来源于人类识别车辆时的认知行为:当一个人对比两张车辆图像时,如果视角是相似的,那么只需观察细节的视觉性外观;如果视角不同,就会依赖于联想和记忆,而不是直接对比视觉外观。换句话说,当面对不同视角的车辆图像对时,人类会采取不同的策略。
将这种识别策略与深度度量学习相互结合,称为 Viewpoint-Aware Network (VANet),它有两个特定视角的学习分支,对应两种不同的特征空间,分别学习D-view和S-view下的度量。
具体来说:在训练阶段,采用了两种不同的度量约束,即:
空间内约束:使得每一个特征空间内正样本对之间的距离小于负样本对之间的距离(即 S-view pos vs S-view neg,D-view pos vs D-view neg)。
跨空间约束:使得当正、负样本对分别在不同特征空间时,正样本对之间得距离也总是小于负样本对之间的距离(即 D-view pos vs S-view neg,S-view pos vs D-view neg)。
S-view pos:相似视角下的正样本对:比如同一车辆在相似视角下的两张图像
S-view neg:相似视角下的负样本对:比如不同车辆在相似视角下的两张图像
D-view pos:不同视角下的正样本对:比如同一车辆在不同视角下的两张图像
D-view neg:不同视角下的负样本对:比如不同车辆在不同视角下的两张图像
以上约束可以理解为:无论什么视角下,正样本对的距离都小于负样本对的距离
==上述两种约束,对VANet网络的判别能力很重要。它们的共同作用大幅提升了重识别的准确率。如图1(d)所示,正样本对(绿色)的距离分布和负样本对(红色)的距离分布可以明显区分开来(注意横轴为距离轴)。 - 总结如下:
1、提出VANet,该网络分别对S-view和D-view学习两种视角感知的度量方法;
2、提出两种约束方式,空间内约束和跨空间约束。尤其是跨空间约束,它使得网络可以在S-view的干扰下检索到D-view的样本。空间内约束则进一步改善文章的方法
3、详尽地测试了该方法在两个大规模的重识别数据集上的表现:相比baseline改善了许多,也超出了目前的state of art
2.相关工作
2.1 关于重识别
。。。一堆工作。。。相比上面这些工作,我们提出的方法只依赖监控相机ID和辅助视角信息,相当节约资源。
我们还进一步对比了关于视角变化问题的其他工作。一些工作显示[27]或者隐式[31]地将方位信息注入到特征里,[27]将方位向量嵌入到特征图里以获得视角感知能力,[31]为车辆的每个方位学习一组特征并在匹配的时候充分考虑可见方位的特征。也有使用GAN网络生成所需视角的图像来实现视角对齐的工作[38,39,40],也即通过视角对齐来解决问题。与此相反,VANet并不对齐视角,它将重识别分为S-view比较,D-view比较和对这两种情况都学习一种深度度量。实验证明了这种策略的效率,尤其是在面对区分S-view neg样本和D-view pos样本的时候。
2.2 深度度量学习
深度度量学习是计算机视觉任务中常用的手段,比如图像检索,行人、车辆识别或者面部识别。通常,深度度量学习旨在学习一个同类样本距离更近、不同类样本距离更远的特征空间,它有两个基础的损失函数:对比损失和三元组损失。而面部识别和行人重识别的很多工作基本上验证了三元组损失相比对比损失会更加适宜,我们的工作也采用三元组损失。
VANet有两个卷积分支,分别对应S-view和D-view。实验中,我们证明了相比单个度量方法的baseline,该视角感知的度量学习方法提高了车辆重识别的精度,同样也证明了该提升大都来源于VANet对D-view pos和S-view neg的区分能力,这将会在4.3部分详细解析。
3.VANet
为了分别对S-view和D-view学习各自的深度度量,我们设计了一个双路网络,以将输入图像映射到两个特征空间中去。S-view pairs和D-view pairs的距离表示为相应空间中的欧氏距离,其中:
- 3.1简要介绍度量学习基准模型(baseline)
- 3.2介绍视角感知的度量学习目标和相应的损失函数
- 3.3利用深度神经网络实现视角感知的度量学习
3.1 度量学习baseline
采用常用的三元损失函数来构建度量学习baseline。
令
X
X
X表示数据集,
P
=
(
x
i
,
x
j
)
P=(x_i,x_j)
P=(xi,xj)表示样本对(图像对),
x
i
,
x
j
∈
X
x_i,x_j∈X
xi,xj∈X;
函数
f
f
f表示原始图像到特征的映射,D表示特征之间的欧氏距离;
给定图像对
P
=
(
x
i
,
x
j
)
P=(x_i,x_j)
P=(xi,xj),计算图像对的欧氏距离为
D
(
P
)
=
D
(
x
i
,
x
j
)
=
∣
∣
f
(
x
i
)
−
f
(
x
j
)
∣
∣
D(P)=D(x_i,x_j)=||f(x_i)-f(x_j)||
D(P)=D(xi,xj)=∣∣f(xi)−f(xj)∣∣
根据这些定义,给定三个样本
x
,
x
+
,
x
−
x,x^+,x^-
x,x+,x−,其中
x
x
x和
x
+
x^+
x+是同一类别的样本(同一车辆),
x
−
x^-
x−则来自其他类别(其他车辆)。那么构建正样本对
P
+
=
(
x
,
x
+
)
P^+=(x,x^+)
P+=(x,x+),和负样本对
P
−
=
(
x
,
x
−
)
P^-=(x,x^-)
P−=(x,x−),那么就可以定义一个三元损失如下:
L
T
r
i
.
(
x
,
x
+
,
x
−
)
=
max
{
D
(
P
+
)
−
D
(
P
−
)
+
α
,
0
}
(1)
L_{T r i .}\left(x, x^{+}, x^{-}\right)=\max \left\{D\left(P^{+}\right)-D\left(P^{-}\right)+\alpha, 0\right\} \tag{1}
LTri.(x,x+,x−)=max{D(P+)−D(P−)+α,0}(1)
其中
α
\alpha
α表示两个欧氏距离
D
(
P
+
)
D(P^+)
D(P+)和
D
(
P
−
)
D(P^-)
D(P−)之间的最小间隔。一般来说,(1)式会约束同一车辆目标的样本距离更近、不同车辆目标的距离更远。但是如图1
(
c
)
(c)
(c)所示,由于极端的视角变化,baseline并不能很好地区分大部分的D-view pos样本和S-view neg样本。
三元组损失 Triplet Loss及其梯度 的理解
3.2 视角感知的度量学习
根据图1(c),我们可以认为在存在S-view和D-view时的车辆重识别任务里,单独一种相似性度量可能是不够的。我们提出了一种特定视角下的框架,可以为S-view和D-view样本分别学习两种不同的深度度量,而不是为两种类型的样本仅仅使用一种度量方式。
具体说,定义两个函数
f
s
f_s
fs和
f
d
f_d
fd,它们将输入图像分别映射到两个不同的特征空间(S-view,D-view),然后,在对应特征空间里计算各自的样本距离:
D
s
(
P
)
=
∥
f
s
(
x
i
)
−
f
s
(
x
j
)
∥
2
D_{s}(P)=\left\|f_{s}\left(x_{i}\right)-f_{s}\left(x_{j}\right)\right\|_{2}
Ds(P)=∥fs(xi)−fs(xj)∥2
D
d
(
P
)
=
∥
f
d
(
x
i
)
−
f
d
(
x
j
)
∥
2
D_{d}(P)=\left\|f_{d}\left(x_{i}\right)-f_{d}\left(x_{j}\right)\right\|_{2}
Dd(P)=∥fd(xi)−fd(xj)∥2
同时定义
P
s
+
P_s^+
Ps+(S-view pos样本对),
P
d
+
P_d^+
Pd+(D-view pos样本对),
P
s
−
P_s^-
Ps−(S-view neg样本对),
P
d
−
P_d^-
Pd−(D-view neg样本对)。
对于视角感知的度量学习来说,需要两种类型的约束:
空间内约束:力图保证在两个特征空间内
D
(
P
+
)
D(P^+)
D(P+)总是小于
D
(
P
−
)
D(P^-)
D(P−);
跨空间约束:力图保证当两个样本对分别在不同空间中时,
D
(
P
+
)
D(P^+)
D(P+)也总是小于
D
(
P
−
)
D(P^-)
D(P−)。注意理解这儿
3.2.1 空间内约束
在每个特征空间内,正样本的距离应该小于负样本的距离。所以,我们采用两个(分别对应S-view和D-view)三元损失函数来进行空间内约束。在S-view特征空间:
L
s
=
max
{
D
s
(
P
s
+
)
−
D
s
(
P
s
−
)
+
α
,
0
}
(2)
L_{s}=\max \left\{D_{s}\left(P_{s}^{+}\right)-D_{s}\left(P_{s}^{-}\right)+\alpha, 0\right\} \tag{2}
Ls=max{Ds(Ps+)−Ds(Ps−)+α,0}(2)
在D-view特征空间:
L
d
=
max
{
D
d
(
P
d
+
)
−
D
d
(
P
d
−
)
+
α
,
0
}
(3)
L_{d}=\max \left\{D_{d}\left(P_{d}^{+}\right)-D_{d}\left(P_{d}^{-}\right)+\alpha, 0\right\} \tag{3}
Ld=max{Dd(Pd+)−Dd(Pd−)+α,0}(3)
在每个特定视角的特征空间里,对应的三元损失函数只对该特定视角的样本起作用。换句话说,
L
s
L_s
Ls只关注S-view pairs,
L
d
L_d
Ld只关注D-view pairs。通过这种方法,我们的模型可以学习提取有区别的细粒度(细节)视觉线索,从而在S-view特征空间中区分相似视角下的不同车辆。同时,我们的模型能够在D-view特征空间中学习到来自不同视角的同一车辆图像样本间的强力(鲁棒性强)的关联。
3.2.2 跨空间约束
空间内约束是不够的,因为现实中的车辆重识别系统面临两种混合的情形:S-view pairs and D-view pairs。所以,只关注空间内约束实际上是低估了视角变化带来的影响,从而导致重识别的准确率降低,这点在4.2中会再次论述。
我们再次提出在两个特定视角之间的跨空间约束,也用三元损失表示如下:
L
cross
=
max
{
D
d
(
P
d
+
)
−
D
s
(
P
s
−
)
+
α
,
0
}
(4)
L_{\text {cross}}=\max \left\{D_{d}\left(P_{d}^{+}\right)-D_{s}\left(P_{s}^{-}\right)+\alpha, 0\right\} \tag{4}
Lcross=max{Dd(Pd+)−Ds(Ps−)+α,0}(4)
注意,这儿的
L
l
o
s
s
L_{loss}
Lloss 只对
P
s
−
P_s^-
Ps−和
P
d
+
P_d^+
Pd+起约束作用,而不考虑
P
s
+
P_s^+
Ps+和
P
d
−
P_d^-
Pd−,原因是相比不同车辆(负样本)从D-view的两次观察图像的距离,同一车辆(正样本)从S-view的两次观察图像距离倾向于更接近(这是符合常理的)。理解为:
不同视角下正样本距离对也要小于相似视角下的负样本对距离:
D
d
(
P
d
+
)
D_d(P_d^+)
Dd(Pd+) <
D
s
(
P
s
−
)
D_s(P_s^-)
Ds(Ps−)
3.2.3 联合优化
联合三元损失函数:
L
=
L
s
+
L
d
+
L
c
r
o
s
s
(5)
L=L_{s}+L_{d}+L_{c r o s s} \tag{5}
L=Ls+Ld+Lcross(5)
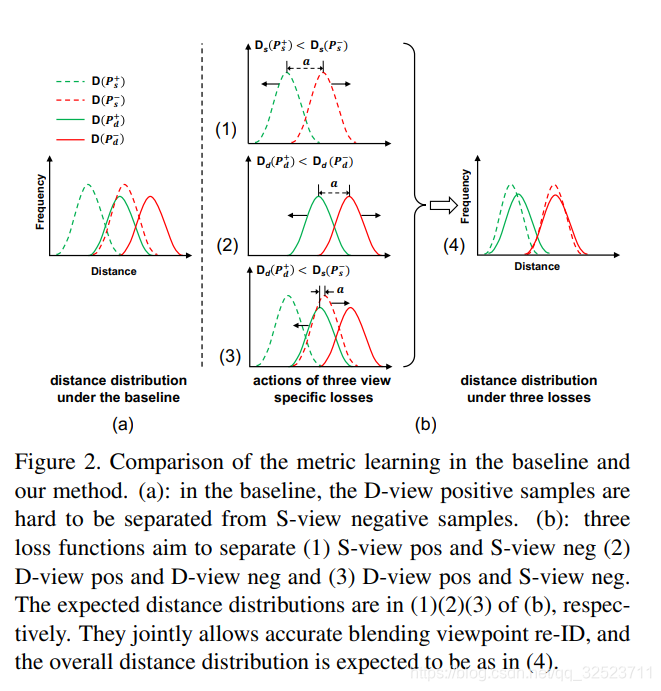
几个单独的损失函数和联合损失函数如图2所示,通过联合的三元损失函数,模型不仅会学习两个相对简单的场景(S-view positive vs S-view negative,D-view positive vs D-view negative),而且也会学习一个相对复杂的场景(D-view pos vs S-view neg)。
看下图:简单理解就是VANet可以将正样本(绿色)和负样本(红色)区分得更开。
3.3 网络结构
如图3,包含两个学习分支。
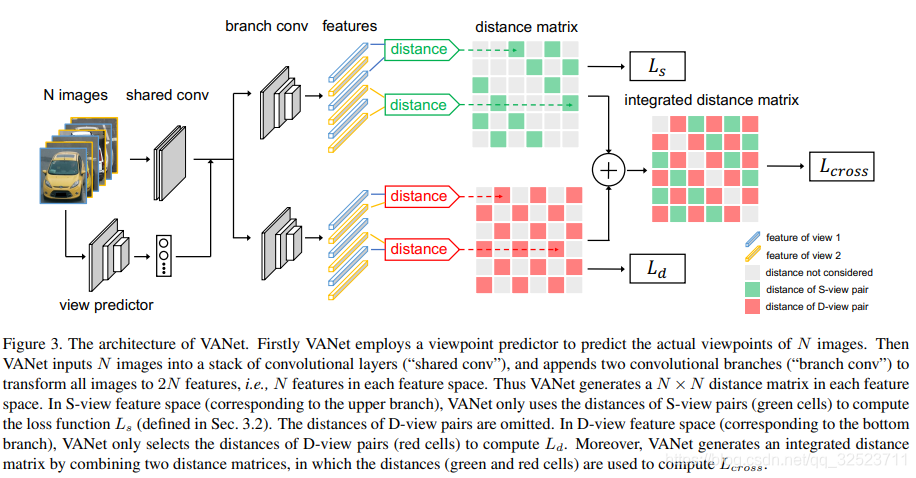
VANet要求识别输入图像对之间的视角关系(S-view或者D-view),首先用一个视角分类器预测每张图像的绝对视角,例如front或者rear。如果图像对来自相同/相似视角,则归类为S-view pair,否则就是D-view pair。特别地,视角分类器是以交叉熵为损失函数、GoogLeNet为基础网络训练的。我们手动标注了分别来自VehicleID和Veri-776数据集的5000张图像作为训练集,视角的标签可以在这儿获取视角标签。对了,视角分类器是单独训练的,在重识别特征学习或者测试过程中并不会进行更新。
然后VANet将图像输入一系列共享卷积层,输出特征会附接到两个卷积网络分支上(这两个分支结构相同但是不共享参数),每个分支都可以视为一个独立的特征提取函数,分别对应3.2中提到的 f s f_s fs和 f d f_d fd函数,将图像分别映射到两个特征空间。对于每张图像,VANet会在两个不同的特征空间输出两路特征: f s ( x ) f_s(x) fs(x) in S-view feature space 和 f d ( x ) f_d(x) fd(x) in D-view feature space。
-
在训练期间,给定一个N张图像的小批量数据,VANet会并行生成数据在S-view和D-view上的距离矩阵,每个矩阵都由N*N个距离值组成。对于一个D-view的样本对而言,VANet依然会在S-view特征空间计算其距离,即 D s ( P d ) D_s(P_d) Ds(Pd),对S-view也是同理,在图3中,用灰色的网格来标注这些距离值(不会被考虑)。回顾(2)式或(3)式,它们分别关注S-view或D-view样本,所以在训练期间, D s ( P s ) D_s(P_s) Ds(Ps)和 D d ( P d ) D_d(P_d) Dd(Pd)(图3中用绿色或红色网格在距离矩阵里标注)分别作用于loss L s L_s Ls和 L d L_d Ld,而 D s ( P d ) D_s(P_d) Ds(Pd)和 D d ( P s ) D_d(P_s) Dd(Ps)不会被考虑进去。
此外,VANet会从S-view 距离矩阵中选取所有的 D s ( P s ) D_s(P_s) Ds(Ps)值,D-view 距离矩阵中选取所有的 D d ( P d ) D_d(P_d) Dd(Pd)值,整合为另一个距离矩阵,如图3所示,在这个矩阵中,绿色(红色)分别对应 S-view(D-view)距离矩阵里的距离值。根据此矩阵,VANet 会根据所有红色和绿色距离值通过 triplet 损失函数 L c r o s s L_{cross} Lcross((4)式)施加跨空间约束。 -
在测试期间,给定一张查询图像,VANet会用图像库中的图像来对它进行特定视角关系的对比。具体来说,如果查询图像与库里面的图像被认为都来自S-view,那么就通过S-view分支(上面的之路)计算它们的距离 D s ( P s ) D_s(P_s) Ds(Ps),反之如果来自D-view,则通过下面的D-view分支计算 D d ( P d ) D_d(P_d) Dd(Pd)。
4.实验
4.1 数据集和设置
在两个公开的车辆重识别基准数据集VehicleID和VeRi-776进行实验。
实现细节:
- 采用GoogLeNet作为backbone,特别地,采用GoogLeNet的Inception(4a)之前的所有层作为“共享卷积层”(shared conv),然后Inception(4a)到全局平均池化层作为分支卷积层(branch conv)。
- 输入图像均resize到224 x 224,并且采用色彩抖动和水平翻转进行图像增广。
- 使用adam优化( ϵ = 1 0 − 3 ϵ= 10^{−3} ϵ=10−3, β 1 = 0.9 β_1 = 0.9 β1=0.9, β 2 = 0.999 β_2 = 0.999 β2=0.999);训练200epoch,学习率初始为0.001,学习率衰减因子factor=0.1(分别在 8 0 t h 80^{th} 80th和 16 0 t h 160^{th} 160thepoch的时候进行衰减);margin α = 0.5;
- 批量大小设置:
VehicleID:128(32IDs,4 images for each)
VeRi-776:256(32IDs,8 images for each) - 训练时采用 batch hard mining strategy[文献10]来推导三元损失。关于这个策略点这儿
除了三元损失之外,还采用了交叉熵损失,参考的是[1,35]的重识别方法。特别地,我们在特征嵌入层上面加入了一个ID分类器,这个分类器通过一个全连接层和一个连续的softmax层实现。softmax层的输出是利用训练图像的ID标签通过监督学习(采用交叉熵损失)得到的。这个额外的交叉熵损失的采用可以小幅度提升VANet和baseline重识别的准确率,文献[1,35]也是如此。
对于视角分类器:
- VehicleID:数据要么是从front方位采集,要么是rear方位,所有定义(front-front)和(rear-rear)代表S-view pairs,(front-rear)和(rear-front)代表D-view pairs。
- Veri-776:所有图像可以粗略地分为三个视角:front,side,rear。定义 (front-front),(rear-rear) 和 (side-side)代表S-view pairs, (front-side),(front-rear) 和 (rear-side)代表D-view pairs。
4.2 评估和模型简化测试
通过比较VANet和baseline(采用相同参数设置)来评估模型的效果,同时还进行了模型简化测试(分别移除
L
c
r
o
s
s
L_{cross}
Lcross和
L
w
i
t
h
i
n
L_{within}
Lwithin(包含
L
s
L_s
Ls和
L
s
L_s
Ls))以验证空间内约束和跨空间约束的重要性,结果如表1,可以看到:
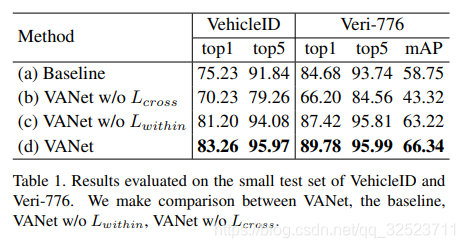
- 相比baseline,VANet大幅提升了多项指标
- 跨空间约束至关重要
- 空间内约束则带来逐渐小幅的改进
4.3 VANet是怎样提升重识别准确率的
通过隔离S-view和D-view的重识别场景,给出了一种关于VANet怎样提升重识别准确率的见解。为了简单起见,我们在VehicleID数据集上做实验,因为该数据集对每张查询图像来说仅有一个正确匹配。主要考虑下面两个问题:
- Q1 当正确的匹配分别是从S-view(即查询图像和正确匹配来自同一视角)和D-view (即查询图像和正确匹配来自不同视角)观察的时候,网络表现怎么样?
- Q2 如果给定正确匹配是从S-view(D-view)观察而来这样的先验条件,当图像库里的所有图像也都是从S-view(D-view)观察而来时,网络表现怎么样?
对于Q1,定义
t
o
p
1
s
top1_s
top1s为当查询图像和真实匹配都是来自S-view时的rank-1匹配正确率;
t
o
p
1
d
top1_d
top1d同理。
对于Q2,定义
t
o
p
1
s
∗
top1_s^*
top1s∗为,给定真实匹配来自S-view的先验条件,移除图像库里的所有D-view图像时的rank-1匹配正确率;
t
o
p
1
d
∗
top1_d^*
top1d∗同理。此处,
t
o
p
1
d
∗
top1_d^*
top1d∗可以视为相对宽松的条件下的
t
o
p
1
d
top1_d
top1d,因为来自S-view数据的干扰被消除了。
那么,类似之前的模型简化测试,这儿的测试结果见表2,可以看到:
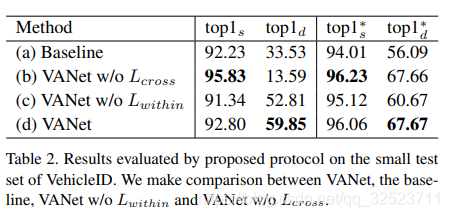
1、对于baseline,来自相同视角的负样本对(相似视角下的不同车辆图像)看起来也很相似,故而容易导致错误匹配:
- S-view下的正确率92.23%远高于D-view下的33.53%,意味着D-view的匹配更具难度;
- 移除图像库里的S-view数据后,D-view下的正确率由33.53%提高到56.09%,意味着S-view下的负样本对重识别产生了重要干扰。
2、VANet有效地抑制了来自S-view的干扰,尤其是在真实匹配为D-view的时候。
- 对比(d)和(a),可以看到相应指标的提升,尤其是 t o p 1 d top1_d top1d相比baseline提升了26.32%,意味着当真实匹配是D-view时(带有S-view干扰),VANet有更高的识别能力;即便消除S-view干扰, t o p 1 d ∗ top1_d^* top1d∗仍有11.58%的提升;
- 作为对比,可以看到对于 t o p 1 s top1_s top1s和 t o p 1 s ∗ top1_s^* top1s∗的提升则相对较小。
- 综上,我们可以认为VANet相比baseline的优势主要在于其强大的检索D-view匹配的能力。
3、跨空间约束是网络能够对抗S-view干扰的重要原因
- 对比(b)和(a),可以看到没有跨空间约束的时候,VANet并没有提高 t o p 1 d top1_d top1d,反而是大幅下降。因为 t o p 1 d top1_d top1d描述的是在S-view干扰下检索D-view真实匹配的能力。故而可以推断跨空间约束是网络能够对抗S-view干扰的重要原因。
通过以上分析可以看出,baseline的重要缺点就是缺少识别D-view真实匹配的能力,尤其是在存在S-view干扰的时候。而VANet可以在保持其他方面表现的同时大幅提升对D-view匹配的检索能力。
4.4 距离分布可视化
分别研究了VANet和baseline学习到的特征空间:计算特征空间中的样本距离并且绘制直方图,如图1( c c c)和(d)所示。可以看到,对于baseline来说,D-view pos和S-view neg的距离分布是高度重叠的,意味着baseline难以区分这两者。而对于VANet来说,D-view pos样本的距离分布在更窄的区域,分布更加紧凑,而且与S-view neg区分明显,意味着它具备了对抗极端的视角变化情况的能力。
4.5 视角预测研究
视角预测器是VANet的重要先决部分,而且它的预测准确率对于重识别精度有重要影响。为了验证这一点,我们通过添加错误样本来训练了一系列不同精度的视角预测器,实验结果如图4。
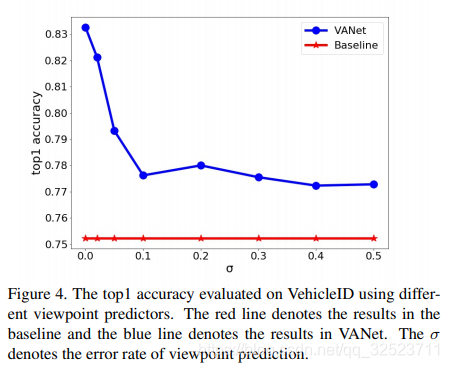
可以看到高精度的视角预测器会为VANet带来更高的重识别准确率,当错误样本比例σ增加到0.1的时候,重识别精度就会下降5.63%,所以,训练一个好的视角预测器是至关重要的。
我们的实现中,分别使用了以GoogLeNet和Xception[4]作为backbone的两种视角预测器:基于GoogLeNet的预测器在VehicleID数据集中随机选取的2000张图像里有99.4%准确率,对应的在Veri776数据集上面为98.9%;而基于Xception的预测器相比基于GoogLeNet的预测器只有10%的参数,却有相似的准确率。如果考虑到计算效率,我们更推荐使用后者。
4.6 视角关系的影响
上面的分析中,我们仅仅将视角关系分为两种类型:S-view和D-view。为了研究不同视角关系划分对重识别精度带来的影响,我们对视角关系采用了更加细粒的划分:
VehicleID:进一步构造了一个三分支和四分支的网络:三分支网络学习三种不同的深度度量,例如(front-front),(rear-rear)
和(front/rear);四分支网络学习四种不同的度量:(front-front),(rear-rear),(front-rear)和(rear-front)。实验结果如表3所示,
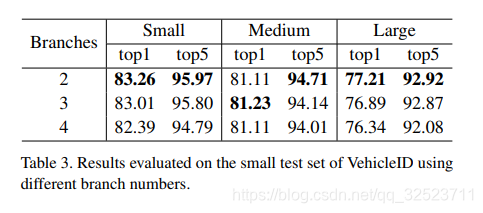
可以看到,更加细粒的划分实际上在精度上有所下降。
Veri-776:构造六分支网络:(front-front),(rear-rear),(side-side),(front-rear),(front-side)和(rear-side),但是它仅仅有64.35%的mAP,相比两个分支的网络下降了1.99%。
这种现象有两个原因:
- 数据集包含固定数量的图像,细粒的划分会减少每个分支的样本数,面临着更高的过拟合风险
- 如图4,低精度的视角预测器会降低VANet的精度,而细粒的视角划分则可能会一定程度上增加视角预测器的错误率,使用这样的划分更可能导致结果更糟。
与其他工作的比较
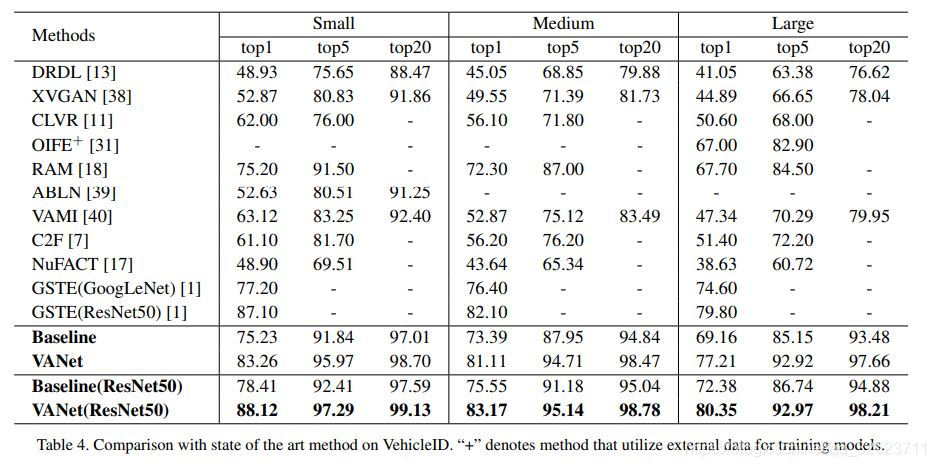
VehicleID数据集的比较见表4。
OIFE [31]训练过程中采用了额外的数据样本。除了GSTE[1]之外的其他方法都使用了额外的标签,作为对比,我们的方法只是用了ID标签。
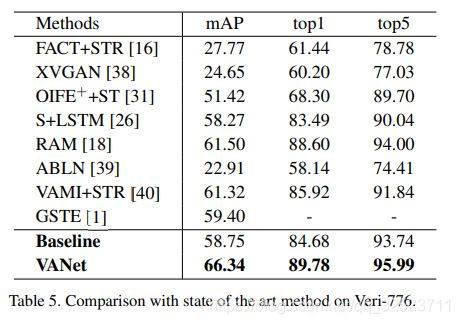
Veri-776数据集上的比较见表5。比较的描述见原论文 -_-
计算消耗:
使用GoogLeNet作为backbone, 添加一个branch到baseline会增加5.1M (+87%)的参数数量和675 MFlops (+44%) 计算消耗。 然鹅,VANet相比表4和表5中的其他方法依然是效率极高的,有第二小的参数量(10.9M)。GSTE [1]参数量最小 (almost 6M), 但是表现不如VANet (-6.06% top1 accuracy on VehicleIDand -6.94% mAP on Veri-776)。
5.结论















 448
448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









