









在进行爬虫系统开发的过程中遇到需要间隔一段时间就重复执行的任务的需求,就想实现一个线程服务在后台监控数据的抓取状态,要想实现定时循环任务的脚本可以使用linux下的crontab命令来执行,但是在一个常驻进程里不太适用于使用这种办法,所以想启动一个线程来处理这类的小需求。
在查找资料后发现可以使用 threading.Timer来实现这个
代码如下:
def func1():
print('Do something.')
global timer
timer = threading.Timer(3, func1)
timer.start()有资料说一定要使用 global 这个关键字,不使用的话会造成线程堆积最终程序退出。
为了证实一下这个说法是否正确,我进行了以下实验:
import threading
def func1(a):
#Do something
print('Do something')
a+=1
print(a)
print('当前线程数为{}'.format(threading.activeCount()))
if a>5:
return
t=threading.Timer(5,func1,(a,))
t.start()a用来记录func1的执行次数
threading.activeCount() #用来显示当前活跃的进程数结果显示为:
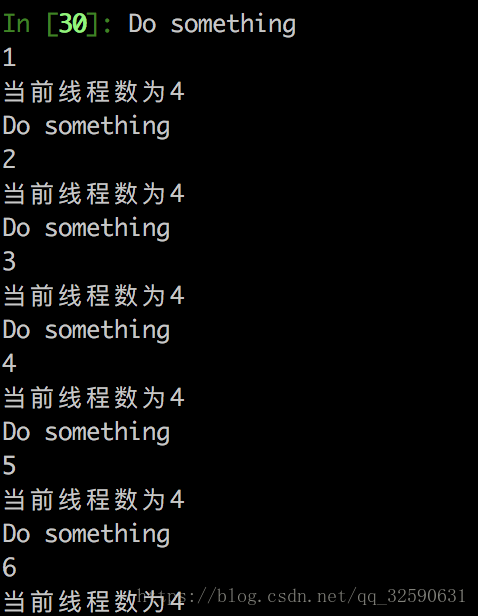
活跃线程数一直保持不变,说明并不会造成线程的堆积。所以使用global关键词是没有必要的。

















 411
411

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









