






Attention是一个可以提升神经机器翻译性能的概念。在这篇文章中会探讨The Transformer——一个利用注意力机制来提升模型训练速度的模型。在特定任务重,这个Transformer模型已超过Google神经机器翻译模型。最大的益处来自于Transformer如何进行并行化。事实上,谷歌云推荐使用The Transformer作为参考模型来使用他们的云TPU产品。因此,让我们试着把这个模型拆开,看看它的功能如何。
1. 简介
将这个模型看成一个简单的黑盒子。在机器翻译应用中,一种语言的句子作为输入,输出是翻译成的另外一个句子。

打开内部的机制,我们会看到encoding模块,decoding模块以及他们之间的连接。
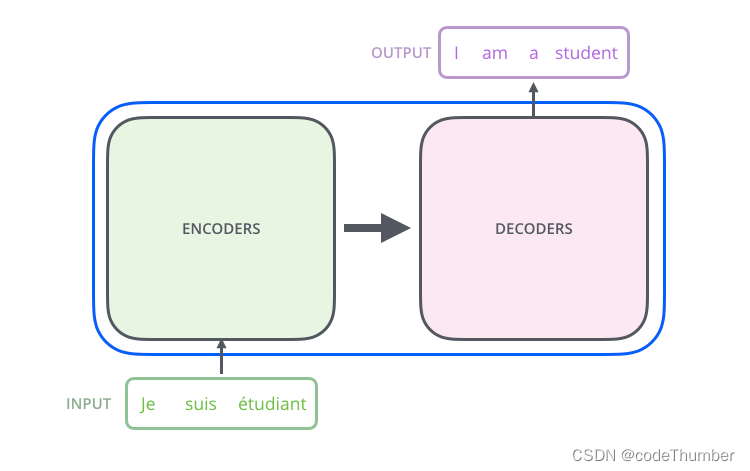
encoding模块是一系列堆叠的encoder(论文中堆叠了6个), decoding模块同样也是堆叠了相同数字的decoder.

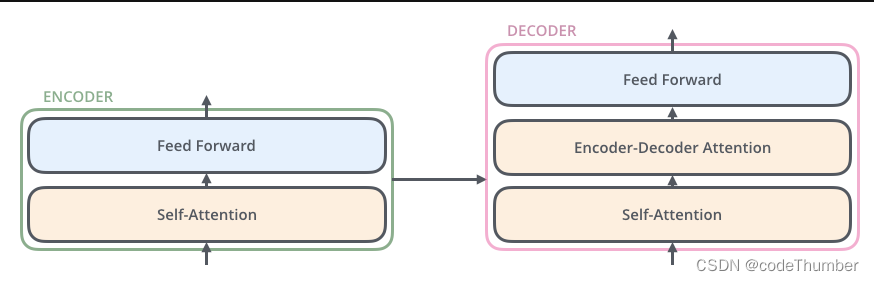
结构中的encoder都不一样(或者说它们并没共享权重).每一个都可以分解为两个层。

encoder的输入首先会经过self-attention层——它可以帮助encoder在编码特定单词时关注句子中的其他单词。
self-attention层的输出会进入前馈神经网络。完全相同的前馈网络独立的应用在每个地方。
deocder也有这些层,但在它们之间有一个attention层帮助decoder关注输入句子的相关部分。
2. tensor可视化
现在知道了模型的主要组成部分,下面开始关注一些向量/张量以及在这些组件之间如何将训练模型的输入转变为一个输出的。
正如一般的nlp应用情况一样,现在开始使用词嵌入算法将输入单词变成向量。

词嵌入只会出现在encoder的最底层,所有encoder都有一个共同的抽象概念即它们接收大小为512维度的向量列表——在底部encoder中输入是词嵌入,在其他encoder中的输入是其他正下方encoder的输出。向量列表的大小是一个可以设置的超参数——一般上它是我们训练数据中最长句子的长度。
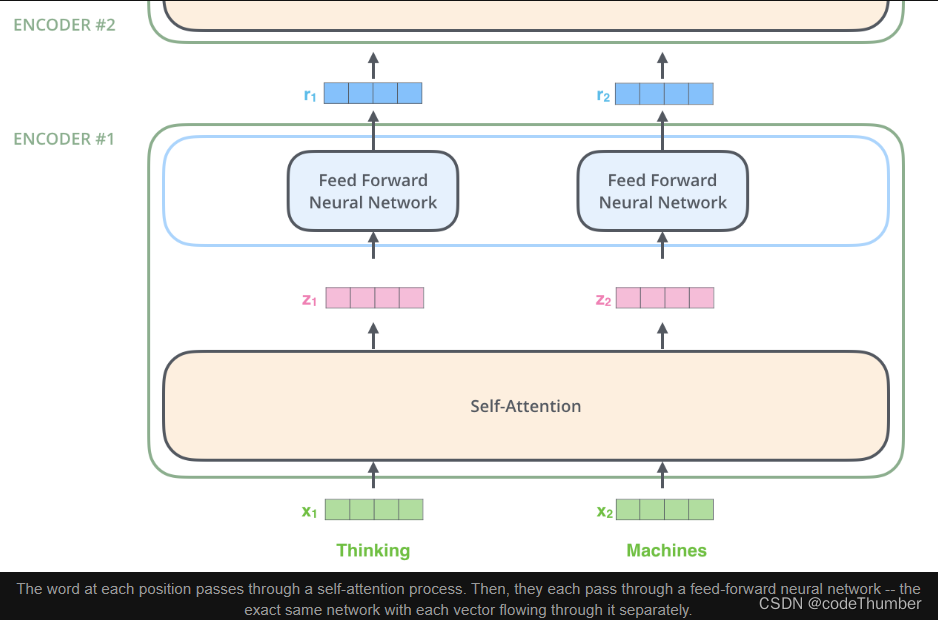
在输入序列中嵌入单词后,每个单词都会流经encoder中的两层。

这里会介绍Transformer中的一个关键特性,即每个位置的单词在encoder中流经它自己的路径。在self-attention层存在着依赖关系。在前馈网络层并没有这种依赖性,因此,各种路径在流经前馈层前可以并行执行。
3. encoding层
上文已提到,encoder会接收很多向量作为输入。这些向量会经过两个处理:首先经过self-attention层和前馈神经网络层,然后会将输出发送到下一个encoder。
4. self-attention
假设我们想翻译下面的句子:
“The animal didn’t cross the street beause it was too tired”
句子中的"it"代表什么呢?是代表street还是代表animal?对人类来说非常简单,但对算法来说往往没有这么容易。
当模型处理单词"it"时, self-attention会将“it"与“animal”联系起来。
当模型处理每个单词时(输入序列中的每个位置), self-attention使它能够在输入序列中的其他位置寻找线索来帮助这个模型更好的完成单词的编码。
如果你熟悉RNNs, 想想维持一个隐藏状态是如何让RNN把它以前处理过的词/向量的表示与它现在处理的词/向量结合起来的。self-attention是Transformer用来将其他相关单词的理解烘托到我们当前正在处理的单词的方法。

当我们在5号编码器(堆栈中最顶端的编码器)中对"it"进行编码时,部分注意力机制集中在”The animal"上,并将其他部分标准烘托到"it"的编码中。
5. self-attention细节
我们先来看看如何使用向量来计算自我注意力,然后再继续看它使用矩阵的实现方式。
计算self-attention的第一步是从每个encoder的输入向量(也就是词嵌入)创建三个向量。因此对每个单词,我们会创建一个Query向量,一个Key向量,一个Value向量。这些向量是通过将词嵌入与我们在训练过程中训练的三个矩阵相乘而产生的。
可以发现这些新的向量比词嵌入向量更小。它们有64维,而词嵌入和encoder的输入和输出都是512维。他们不一定要更小,这是一个架构选择,以使multi-head attention的计算(大部分)恒定。
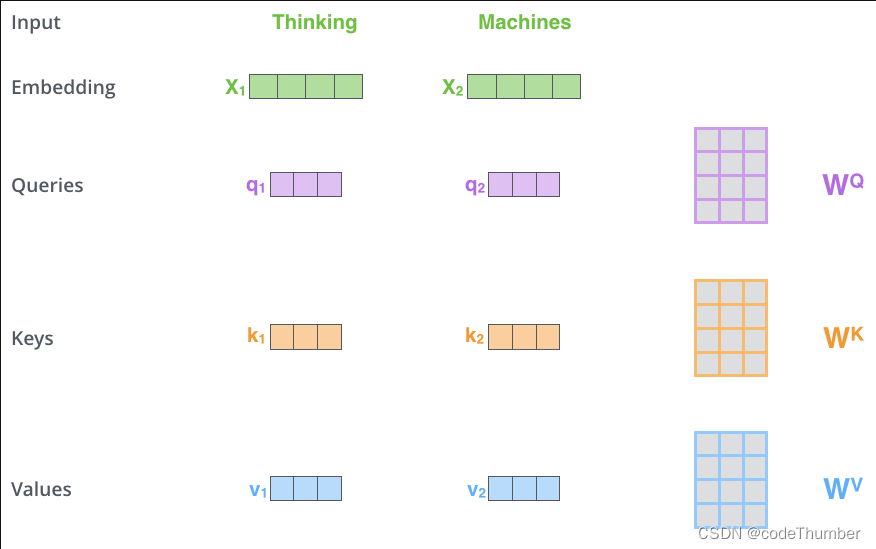
“query” ,key"和"value"向量是什么?
他们是对计算和理解attention有好处的一种抽象。
计算self-attention的第二步是打分:假设我们正在计算例子中第一个单词"Thinking"的self-attention. 我们需要对输入句子中的每个词与这个词进行打分。这个分数决定了当我们要对输入句子中的某一位置的单词进行编码时,要对输入句子中的其他部分给予多大的关注。
这个分数通过将query向量与每个打分单词的key向量进行点乘。所以如果我们正在处理位置1的单词self-attention, 第一个分数是q1与k1的点乘,第二个分数是q1与k2的点乘。

第三步和第四步:是将分数除以8(key向量维度开根号, 论文中是64, 所以这里是除以8,这可以得到更加稳定的梯度。这里可能有其他可能的值,但这是默认的). 然后将结果发送给softmax处理,Softmax将分数归一,所以它们都是正数,加起来是1。
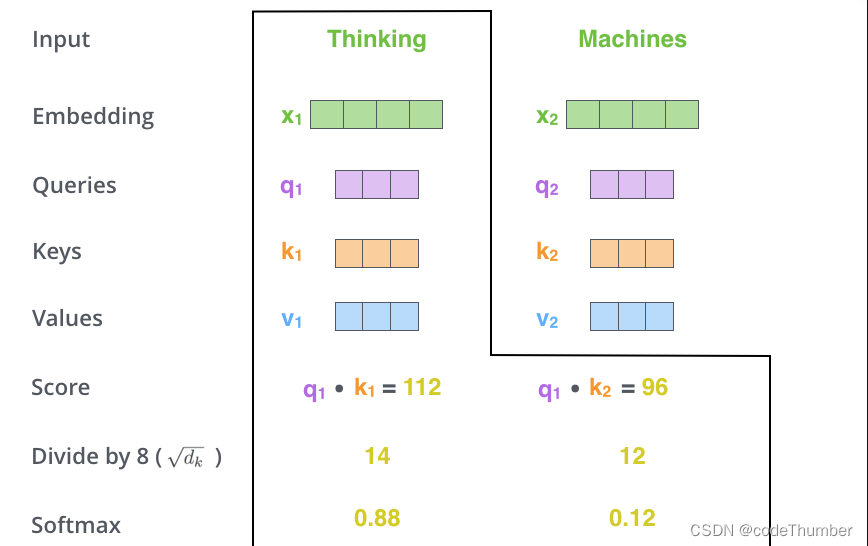
softmax分数决定了每个词在这个位置上的表达量。显然,这个位置上的词会有最高的softmax得分,但有时关注另一个与当前词相关的词是很有用的。
第5步: 将value向量与softmax得分相乘(为了将它们相加), 这一步的直觉是保持关注单词的完整价值和过滤掉不相关单词(例如,将0.0001与它们相乘)。
第6步:将所有加权的value向量向乘,这就产生了self-attention层在这个位置的输出。
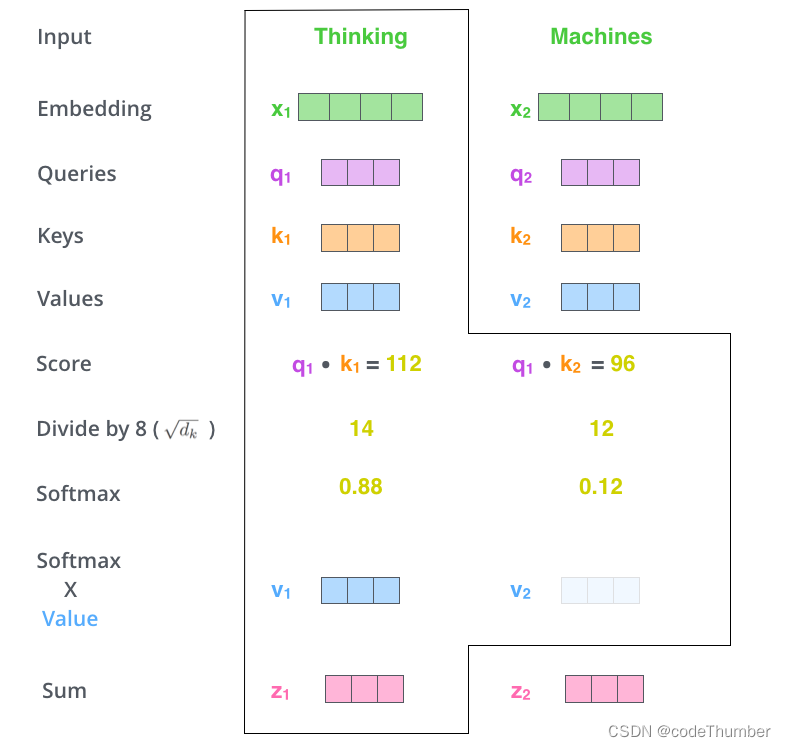
上面总结了self-attention的计算过程。self-attention的输出向量会发送到前馈神经网络层。然而,实际实现过程中,这种计算是以矩阵形式进行的,以便更快处理。
6. self-attention的矩阵计算
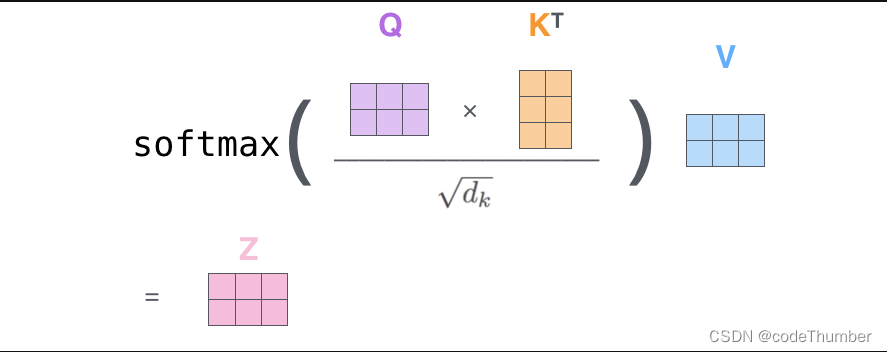
第一步:第一步是计算Query/Key和value矩阵。将词嵌入包装成矩阵X,然后与我们训练的权重矩阵(WQ, WK, WV)相乘。

图中,X矩阵中的每一行与输入句子相对应,我们可以看到词嵌入向量(大小为512, 图中的4个小方格)与q/k/v向量(64维, 图中的3个小方格)的不同。
最后: 我们再处理矩阵,所以我们可以把第二到第六步浓缩在一个公式中,以计算自我注意层的输出。
7. 多头注意力机制 multi head
通过增加一个“多头”注意力机制来完善self-attention层,可在如下两个方面提升attention层的性能。
● 1. 扩展了模型的能力,可以使模型关不不同的位置。在上面的例子汇总,z1包含其他每一种encoding中的一点点,但它可能被实际的单词本身所限制。
● 2. 它赋予attention层多个"表征子空间"。下面我们会看到,在multi-heah attention中有多组Query、Key、Value权重矩阵而不是只有一个(transformer使用8个attention head, 所以我们为每个encoders/decoers提供了8组权重矩阵), 每一组权重矩阵都是随机初始化的。训练之后,每一组权重矩阵都被用于将输入embedding(或来自下级的encoder、decoder向量)投射到不同的表征子空间。
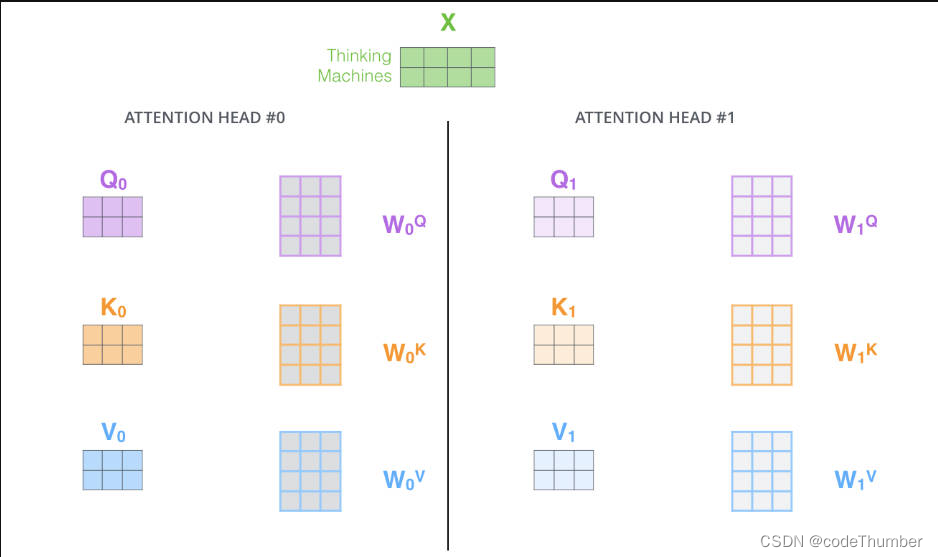
对于multi-head attention,我们为每个头保持单独的K/Q/V, 从而产生不同的K/Q/V矩阵。与之前的做法类似,我们用X乘以WQ/WK/WV矩阵来产生Q/K/V矩阵。
如果我们像上面总结的那样去计算self-attention,对不同的权重矩阵仅仅需要计算8次最终得到8个不同的z矩阵。

这会给我们带来一些挑战,前馈神经网络层并不希望得到8个矩阵——它只希望得到一个句子(一个单词一个句子)。所以我们需要用某种方法将8个矩阵拼接成一个单独的矩阵。
如何做呢? 我们首先将这些矩阵拼接然后再乘以一个额外的权重矩阵WO。
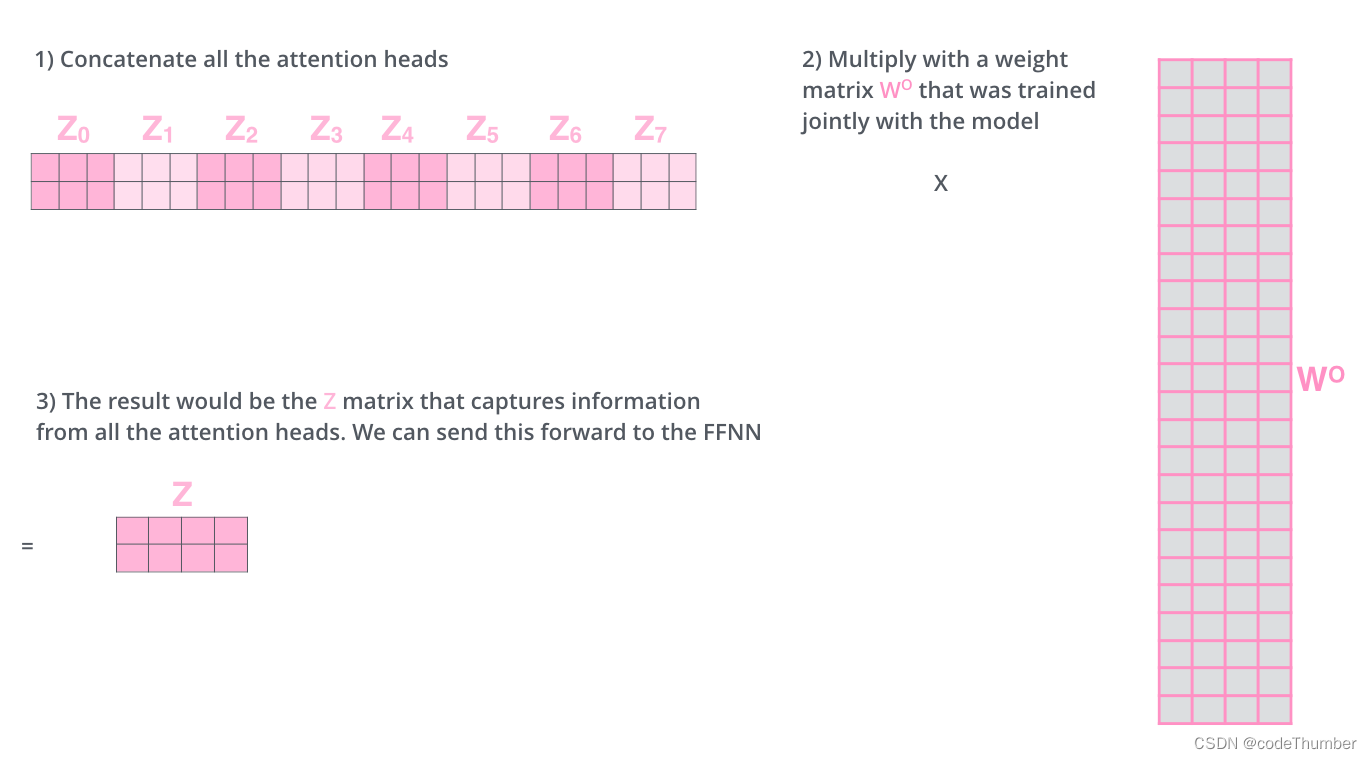
这几乎是multi-head attention的全部内容。我意识到它有太多的矩阵了,我尝试将这些矩阵放在一个可视化的地方。

既然我们已经了解了attention heads,现在我们来看一下, 在我们提供的例句中,当我们对单词"it"进行编码时不同的attention head会关注哪些地方。
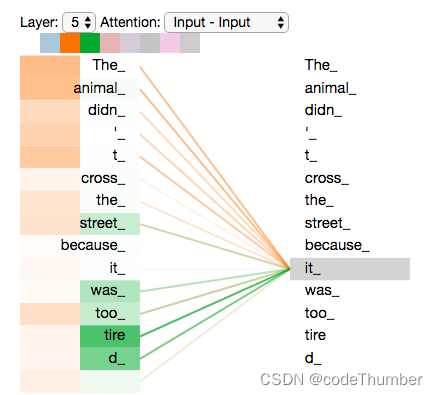
当我们在对单词"it"编码时,一个注意力头大部分关注在"the animal", 而其他的关注在"tired"——某种意义上,模型对单词"it"的表征在“animal”和"tired"上都有一些。
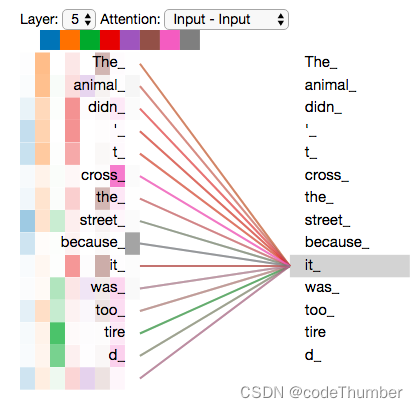
如果我们将所有的注意力头都放在一个照片中,将会变得很难去解释。
8. 使用位置编码表征序列的顺序
到目前为止, 我们所描述的模型中还缺少一样东西,那就是对输入序列单词顺序的说明。
为了解决这个问题,transformer在每个输入embedding中加入了一个向量。这些向量遵循一个模型学习的特特定模式,这个模式可以帮助决定每个单词的位置,或者在序列中不但单词之间的距离。这里的直觉是,一旦嵌入向量被投射到Q/K/V向量中,在点乘attention中,将这些值添加到embedding中,就能提供嵌入向量之间有意义的距离。

假设词嵌入有4维, 实际的位置编码可能是这样的。
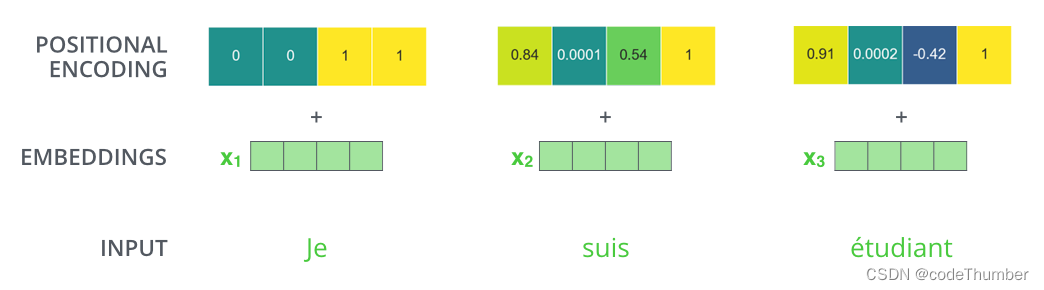
这个模式是怎么的呢?
在下面的图中,每一行都与位置编码向量有关。所以第一行就是我们在输入序列中添加到embedding中的向量。每行包含512个值——每个值都在-1和1之间。我们将其进行颜色编码,所以这个模式是可见的。

一个位置编码的真实案例,20个字(行)的词嵌入大小为512(列)。可以看到它们从中间开始分成两半。这是因为左半部分的值是由一个函数产生的(使用的是sine函数),而右半部分使用的是另外一个方程(使用的是cosine)。然后将它们串联起来,形成每个位置编码向量。
它不仅仅是位置编码函数,它能够扩展到未见过的长度的序列(例如,如果我们的训练模型柏要求翻译一个比我们训练集中的任何句子都长的句子)。
2020年7月更新:上面显示的位置编码是来自Tranformer2Transformer的实现。论文中显示的方法略有不同,它不是直接串联,而是将两个信号交织在一起。下图显示了它的样子。

9. 残差结构
encoder结构中有一个细节是每个encoder中的子层(self attention)中都有一个残差连接,下面展示的是layr-normalization步骤。

如果把向量和与self-attention相关的layer-norm可视化,它可能长这样。

decoder中的子层也一样。考虑transformer中2层叠加的encoder和decoder,它可能长这样:
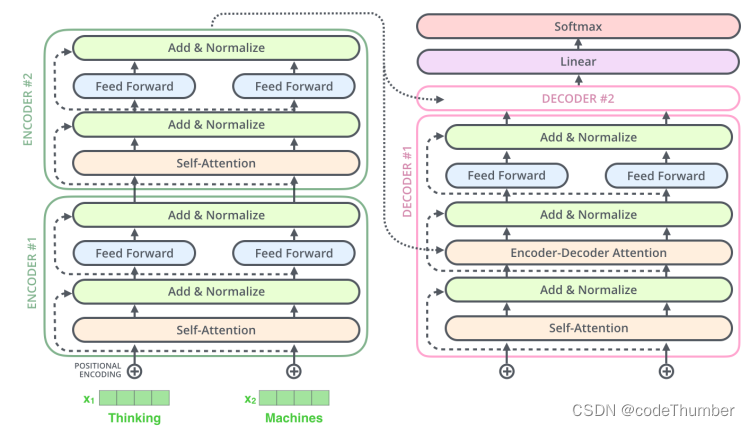
10. decoder层
既然已经基本上理解了encoder层,我们也基本上了解了decoder的的组成部分,现在将二者结合起来看。
encoder以处理输入序列开始。encoder顶层输出的是一组attention向量K和V。这些向量被每个decoder用在encoder-decoder attention层,帮助decoder关注输入序列中的正确位置。

完成encoding阶段后,开始decoding解决。解码阶段的每一步都从输出序列中输出一个单词。
下面的步骤重复这个过程, 直到达到一个特殊标志符,这个标志符表示transformer decoder已经完成它的输出。下一个时间步每一步的输出都喂到底层decoder,与encoder类似,decoders收集他们的decoding结果。就像我们处理encoder的输出一样,我们在decoder的输入中嵌入并加上位置编码以表示每一个单词的位置。

decoder操作中的self-attention与encoder中的self-attention不同。
在decoder中,self-attention只允许关注输出序列中较早的位置。这是通过在self-attention计算的softmax步骤之前设置位置掩码(将他们设置为-inf)来实现的。
除了 encoder-decoder attention从下面的层创建Querie矩阵和从encoder栈的输出中计算Keys和values矩阵之外, encoder-decoder attention与multihead self-attention工作原理一致,
11. final Linear层和Softmax层
decoders栈输出浮点型向量,如何将其转化为一个单词呢,这就是softmax层之后的final Layer层做的事。
Linear层是一个简单的全连接网路,这个网络将encoders栈产生的向量投射到一个非常大、非常大的向量中,这个向量叫logits向量。
假设我们的模型知道10000个不同的英文单词(模型的输出字典), 这些单词都是从训练数据集中学习到的。
这会使得logits向量的宽度达到10000个单元, 每一个单元对应一个单词的分数。这就是我们如何解释线性层之后的输出了。
softmax layer将这个分数转为概率(都是正数, 加起来的和为1)。概率最高的单元被选中,与该单元相关联的单词就作为当前时间步的输出单词。

图片中最下面是decoder栈产生的输出向量。然后将其变成输出单词。
12.训练过程
我们已经了解了训练好的Transformer的整个前向过程。下面直观上看一下模型的训练过程。
在训练过程中,一个没有经过训练的模型会经历完全相同的前向传播过程。因为我们在带有标签的数据集上训练,我们能够将模型的输出与真实的标签进行比较。
为将其可视化,我们假设我们的输出字典只包含6个单词(“a”, “I”, “thanks”, “student”,and “”
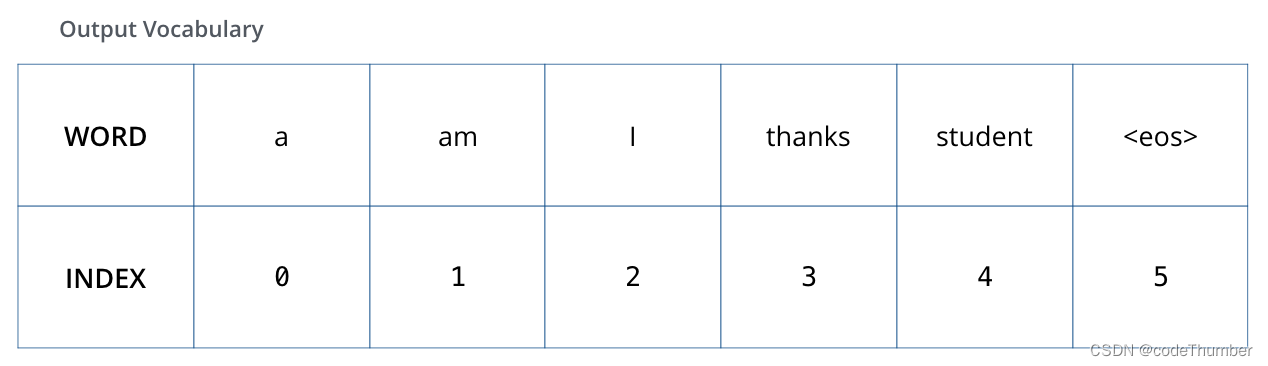
模型的输出字典在训练阶段之前的预处理阶段创造的。
一旦我们定义了输出字典,我们可以用同样大小的向量表示字典中的字。这就是大家熟知的one-hot编码,例如,我们可以用下面的向量表示单词表示"am”

举例:输出字典的one-hot编码
继续讨论模型的损失函数——在训练过程中优化的矩阵以形成一个经过训练、效果惊人的模型。
13. 损失函数
假设我们正在训练我们的模型,假设是我们训练的第一步,而且我们在训练一个非常简单的例子——将“merci"翻译成"thanks".
它的意思就是我们想要输出的概率分布指向单词"thanks", 但是模型并未经过训练,现在还不可能发生。
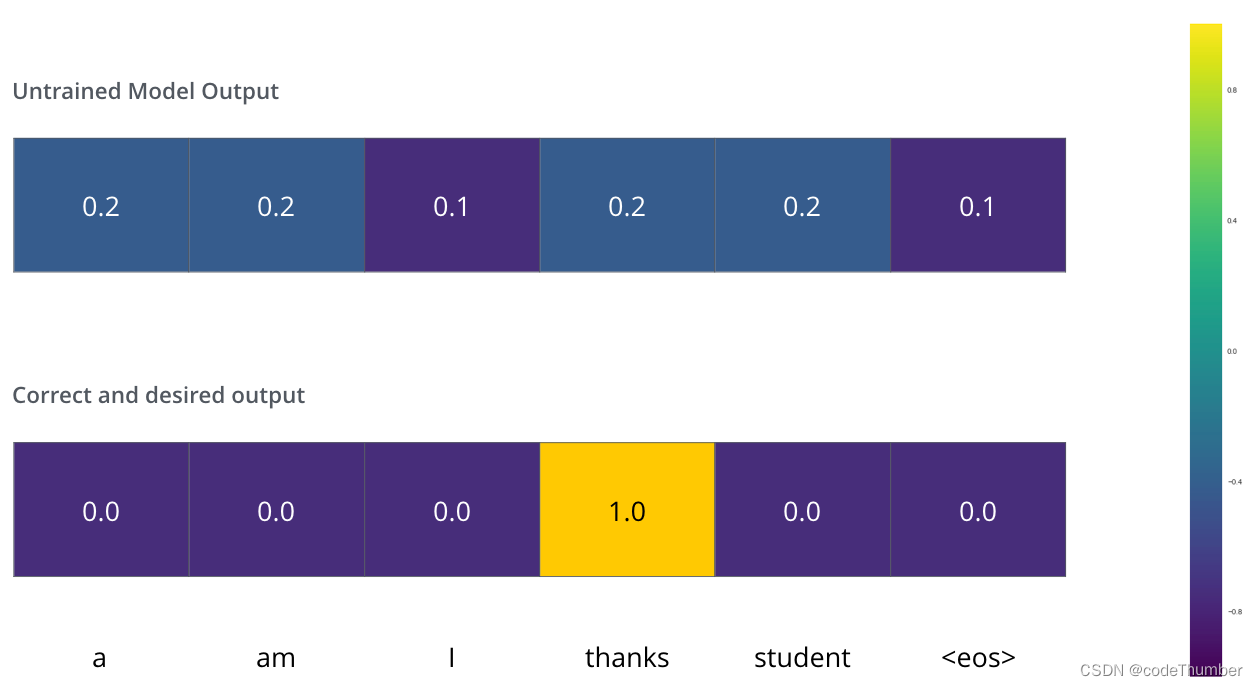
因为模型的权重是随机初始化的,未训练的模型产生了概率分布,每一个单元格都是随机值。我们能将它与真实的输出进行对比,然后使用反向传播调整模型的权重让输出更加逼近理想的输出。
如何比较两个概率分布?只需从另外一个中减去一个。更多的细节,可以查看交叉熵损失。
但需要注意的是,这是一个过于简单的案例,实际上,我们使用的是更长的句子而不是一个单词。例如——输出:“je suis étudiant”,期望的输出是“I am a student”. 真实的含义是:我们需要我们的模型成功输出这样的概率分布:
● 每一个概率分布都由一个字典大小的向量表示。(我们的例子中是6, 但实际中可能是30000或50000)
● 第一个概率分布在与单词"I”相关的单元格上有最高的概率分布
● 第二个概率分布在与单词"am”相关的单元格上有最高的概率分布
● 以此类推,直到第5个输出分布指向""标志,它也有一个与之相关的10,000元素词汇的单元。
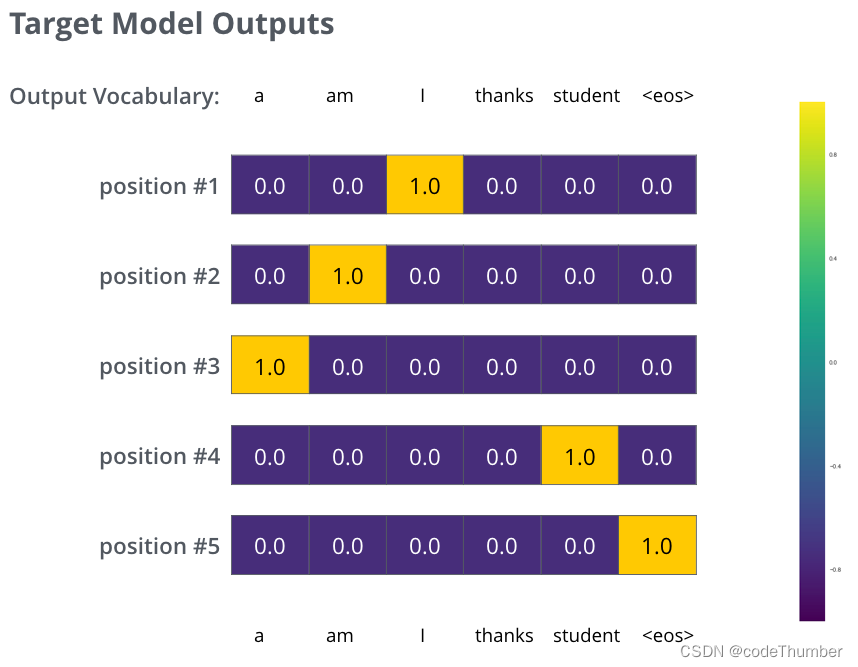
我们将在训练实例中针对一个样本句子的目标概率分布来训练我们的模型。
训练一段时间后,我们期望的输出是这样的:

训希望在训练时,模型能输出我们期望的正确翻译。当然,这句话是否是训练数据集的一部分并没有真正的迹象(见:交叉验证)。请注意,每个位置都有一点概率,即使它不可能成为该时间步骤的输出 – 这是softmax的一个非常有用的属性,有助于训练过程。
现在,由于该模型一次产生一个输出,我们可以假设该模型是从该概率分布中选择概率最高的词,而丢弃其他的。这是一种方法(称为贪婪解码)。另一种方法是保留,比如说,前两个词(比如说,‘I’和’a’),然后在下一步,运行模型两次:一次假设第一个输出位置是’I’,另一次假设第一个输出位置是’a’,考虑到1号和2号位置,哪个版本产生的误差小就保留。我们对2号和3号位置重复这一步骤…等等。这种方法被称为 “波束搜索”,在我们的例子中,beam_size是两个(意味着在任何时候,两个部分假设(未完成的翻译)都被保留在内存中),top_beams也是两个(意味着我们会返回两个翻译)。这两个都是超参数,你可以进行实验。















 838
838











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









