







评估数据质量的指标总结1
1、RMSE(root mean square error)均方根误差
作用:RMSE是估计的度量值与“真实”值之间的距离的度量。
计算方法:
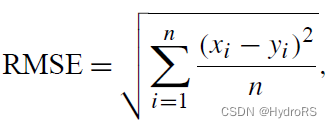
2、相关系数r(coefficient of correlation ®)
作用:皮尔逊相关系数(Pearson correlation coefficient)是连续类型数据关联的标准度量。
皮尔逊相关系数测量变量之间的线性关联。
+1-完全正相关
+0.8-强正相关
+0.6-中等正相关
0-无关联
-0.6-中度负相关
-0.8-强烈的负相关
-1-完全负相关
计算方法:
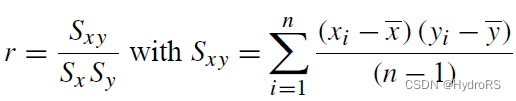
- Sx和Sy是每个样本的方差;
- n是观测数据的个数;
- r取值范围【-1,1】。
3、root mean square deviation (RMSD)均方根偏差
均方根偏差(Root Mean Square Deviation,简称 RMSD)是一种用于衡量两个数据之间的差异程度的常用方法。在化学、生物学领域中应用广泛,常用于蛋白质或其他大分子结构之间的比较。
计算方法:
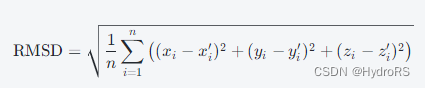
注意:RMSE和RMSD区别
RMSD 是指均方根偏差,是一种用于衡量两个数据集之间差异程度的方法,常用于分子结构比较中。RMSE 是指均方根误差,是一种用于衡量回归模型预测结果与实际结果之间差异程度的方法,常用于机器学习和数据挖掘中。
RMSD 的计算方式是将两个数据集中每个数据点之间的差值的平方和除以数据点数量后取平方根。它主要应用于比较两个分子结构之间的相似性,例如在蛋白质结构比对中。
RMSE 的计算方式也是将预测值与实际值之间的差值求平方和,但是除以的是数据点数量减1,并且最后还需要再取平方根。它主要用于评估回归模型的预测精度。
4、偏差、标准差、残差
(1)偏差(Bias)表示样本均值与总体均值之间的差异程度,是描述估计量的精度和准确性的指标。如果估计量的偏差小,说明估计量的准确性高;反之,偏差大则说明估计量不够准确。在实际应用中,我们通常希望估计量的偏差越小越好。
偏差(deviation)是指一组数据中,每个数据与这组数据的平均值之间的差值,它可以通过计算每个数据减去平均值所得到的结果的平均值来得到。偏差的绝对值越大,说明数据点距离平均值越远,数据的分布越不均匀。偏差可以用于描述数据的集中趋势。
(2)标准差(Standard Deviation)是对数据集合中的每个数与平均值之间的距离的一种度量,它反映了数据集的离散程度。标准差越小,说明数据点越接近平均值;标准差越大,说明数据点越分散。在实际应用中,我们通常希望数据集的标准差越小越好,因为这意味着样本更加稳定,更能够反映总体特征。
需要注意的是,偏差和标准差都是与总体均值有关的统计量,因此计算它们时需要有总体均值作为参考。但是,在实际情况下,我们通常无法得到总体均值,只能通过样本均值等估计量来代替总体均值进行计算。在这种情况下,我们通常使用样本均值和样本标准差来近似代替总体均值和总体标准差。
两者计算方法:

np.std() 函数是 NumPy 库中的一个用于计算标准差的函数,语法:numpy.std(a, axis=None, dtype=None, keepdims=<no value>)
该函数包含以下参数:
- a:要计算标准差的数组或者可以被转换成数组的序列。
- axis:可选参数,默认为 None。如果没有指定轴,则返回整个数组或序列的标准差;否则会计算指定轴上的标准差,取值范围为 [-N,
N-1][−N,N−1],其中 NN 是数组的维数,-1 表示最后一个轴,-2 表示倒数第二个轴,以此类推。 - dtype:可选参数,用于指定输出数组的数据类型。
- keepdims:可选参数,默认为 。如果被设为 True,那么结果数组的维数与输入数组的维数会保持一致。
(3)残差
残差(residual)是在进行回归分析时,观测值与预测值之间的差异。也就是说,残差是真实值和预测值之间的误差。
5、Nash–Sutcliffe efficiency (NSE)
Nash-Sutcliffe 效率(Nash–Sutcliffe efficiency,NSE)是一种衡量预测值与实际观测值之间拟合程度的评价指标。该指标广泛应用于水文学、环境科学、气象学等领域,常用于评估数值模型的性能。
在水文学中,NSE常用于评价降雨/径流模型的拟合效果。具体来说,Nash-Sutcliffe 效率是根据实际观测值和模型预测值之间的均方误差来计算的。如果模拟结果完全符合观测值,则 NSE 值为1。如果模拟结果比简单平均值更糟糕,则 NSE 值小于0。
公式:

REF:The accuracy of the Sentinel-3A altimetry over Polish rivers.

















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









