







引言
在上篇文章cs231n 2023春季课程理解——lecture_10中,我们介绍了对视频理解(深度学习与视频相关的内容,如视频分类、3D卷积神经网络双流网络以及多模态视频理解)。在这篇文章中,将讲解深度学习在目标检测以及图像分割中的应用。
语义分割
之前我们学习了图像分类,现在我们来了解计算机视觉的另一个领域,图像分割。图像分割主要分为语义分割以及实例分割,在这一小节中,我们将讲述语义分割。语义分割是指从像素级别来对图像进行分类,即标注出每个像素所属类别。一般来说,语义分割只分离不同类别的物体(相对地,实例分割分离还会分类同一类别的物体),因此,如果一张图像中某一个类别的对象有多个,语义分割也只是将它们统一归为某一类,而不会分为单独的对象。

语义分割方法
现在我们了解到语义分割是对像素进行分类,那么该如何对一张完整的图像进行分类呢?
一个可以进行语义分割的想法是进行滑动窗口(也就是以固定的小视角,对整张图片按照一定的顺序去滑动,将一个大任务分成若干小任务)。例如下图,滑动窗口选取了奶牛的头部大约三个不同部位的窗口,然后将这个窗口的图像看做是一个物体,并将其进行分类。现在来对着三个窗口中的东西进行以图像中心为主要部分进行分类,那么我们可以使用之前的相关知识(比如说卷积神经网络)来对这些窗口进行分类。这种方法也许在某些程度上能起作用,但是它可能不是一个很好的办法,会导致消耗大量的计算资源。这是因为我们需要对每个像素进行分类,这需要产生大量的小图像,且这些图像不会被重新利用。

既然在滑动窗口进行滑动之后,也是将小图像放入到卷积神经网络中进行分类,且卷积神经网络本身就具有局部连接性,那么一个更好的方法是直接对整个图像应用卷积神经网络,这样就能对每个像素进行分类,最后再将所有的分类结果在原图上做语义分割(如下图)。但是这样也有一个问题,那就是分类模型经常需要降低图像的空间尺寸大小来获取更多的特征信息(毕竟分类最终只需要一个向量就好了,确定每个类别的分数,再根据分数来确定类别),而语义分割却需要输出大小与输入大小相同。

不过对于上面的问题,为了能让输出与输入大小相同,我们可以构建一个全部都是卷积层的网络结构来解决(通过padding操作可以让卷积之后输入输出大小不变)。但是这样它的计算资源也非常昂贵(卷积一般都是对原始图像进行操作的时候参数量最大,全连接则是最后参数量最大)。为了解决这个问题,我们可以在设计网络时,在网络中间加入下采样和上采样操作。这样,对于原始图像,我可以在经过初始的卷积层之后进行下采样,以降低图像的分辨率,从而减少计算消耗,而在之后,通过上采样来恢复图像,最后得到语义分割结果。
上采样
在之前,我们知道在卷积神经网络中,通过池化操作或者是步长(stride)不为1的卷积操作可以将图像的大小降低,这就是下采样的方法。那么,对于上采样,该怎么做呢(也就是怎么将图像恢复到原来大小)?其实上采样操作和下采样操作一样,可以看做是反向操作。对于池化操作,可以将单一的值分配到更高的分辨率中。比如说一个2×2的输入,上采样到4×4的分辨率中时,输入中的每个像素在4×4的输出中都占有一个2×2的位置,具体见下图。
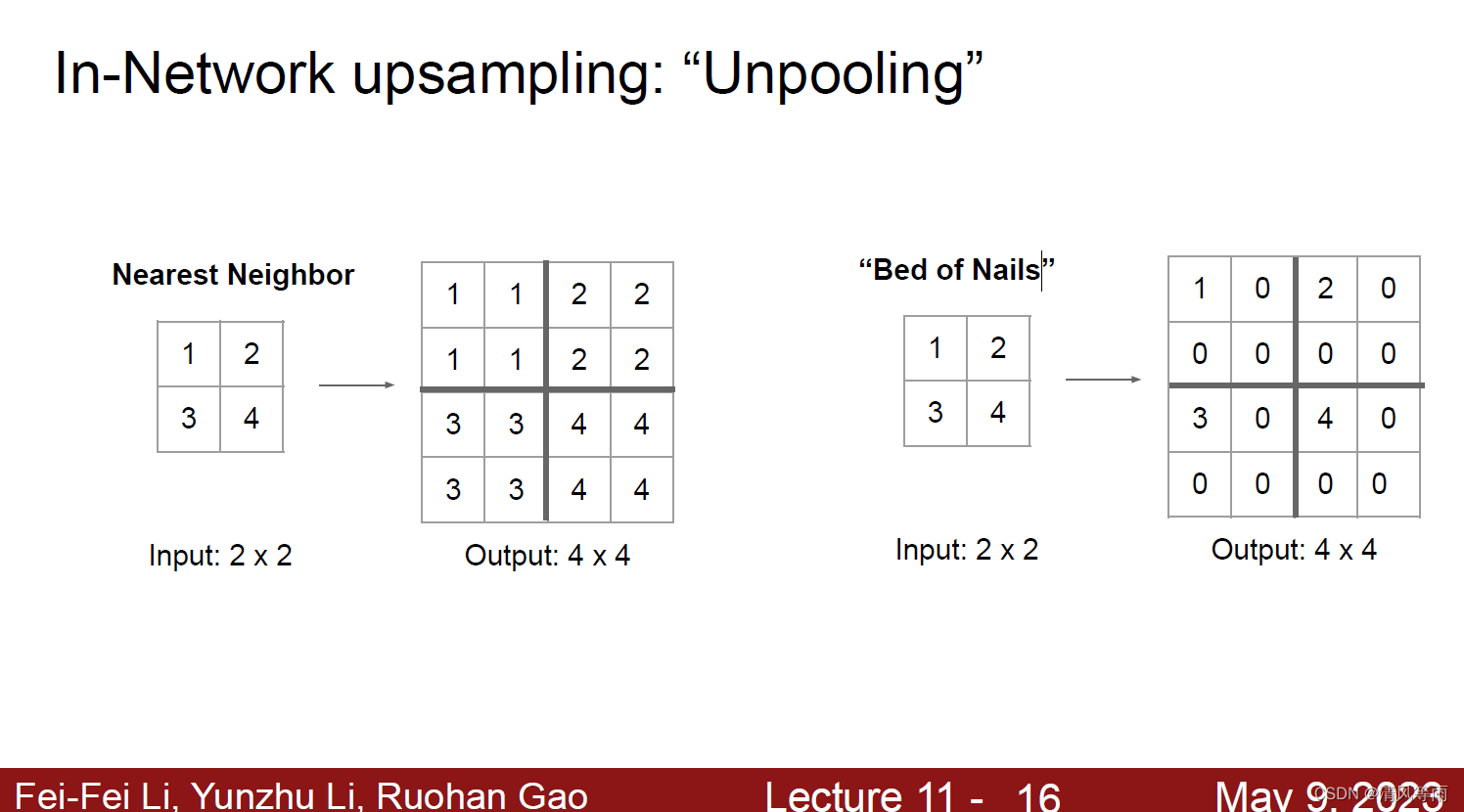
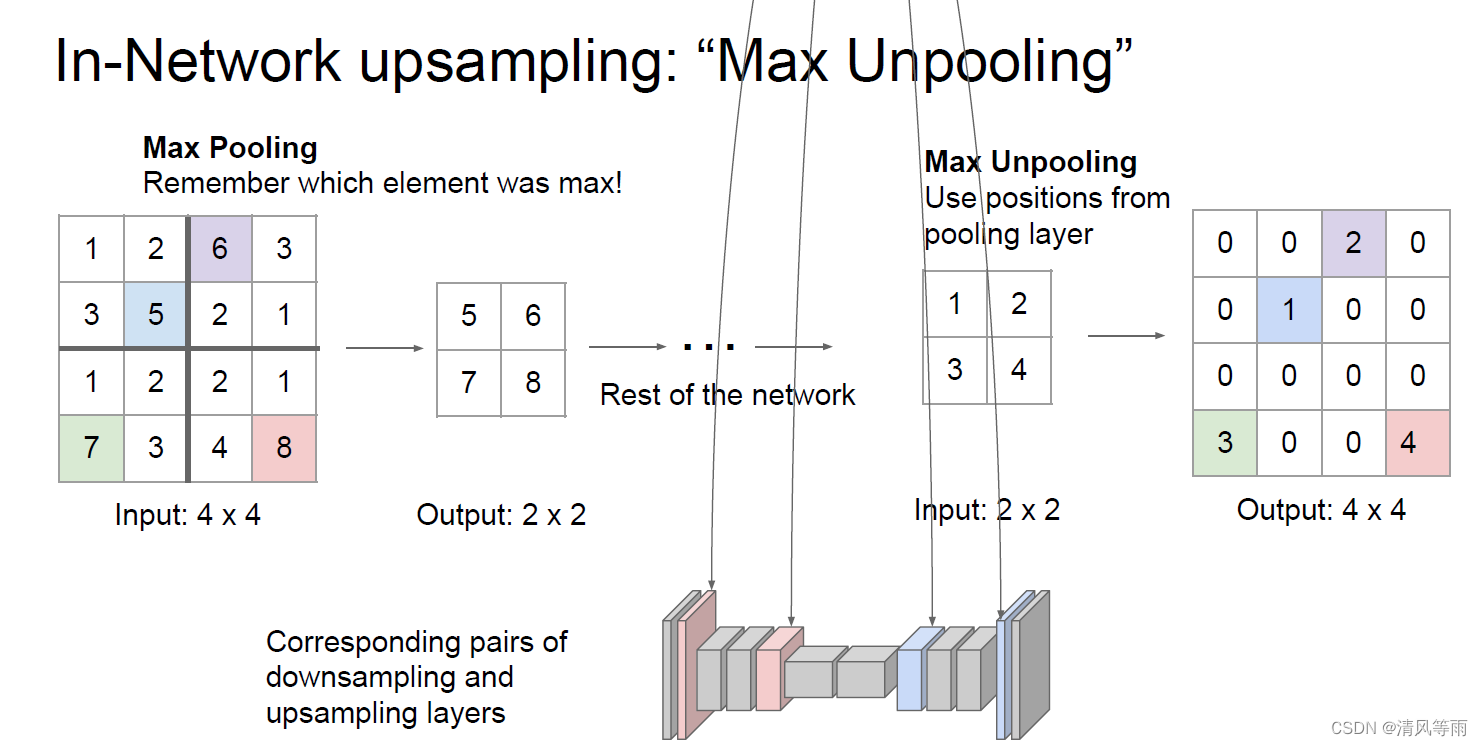
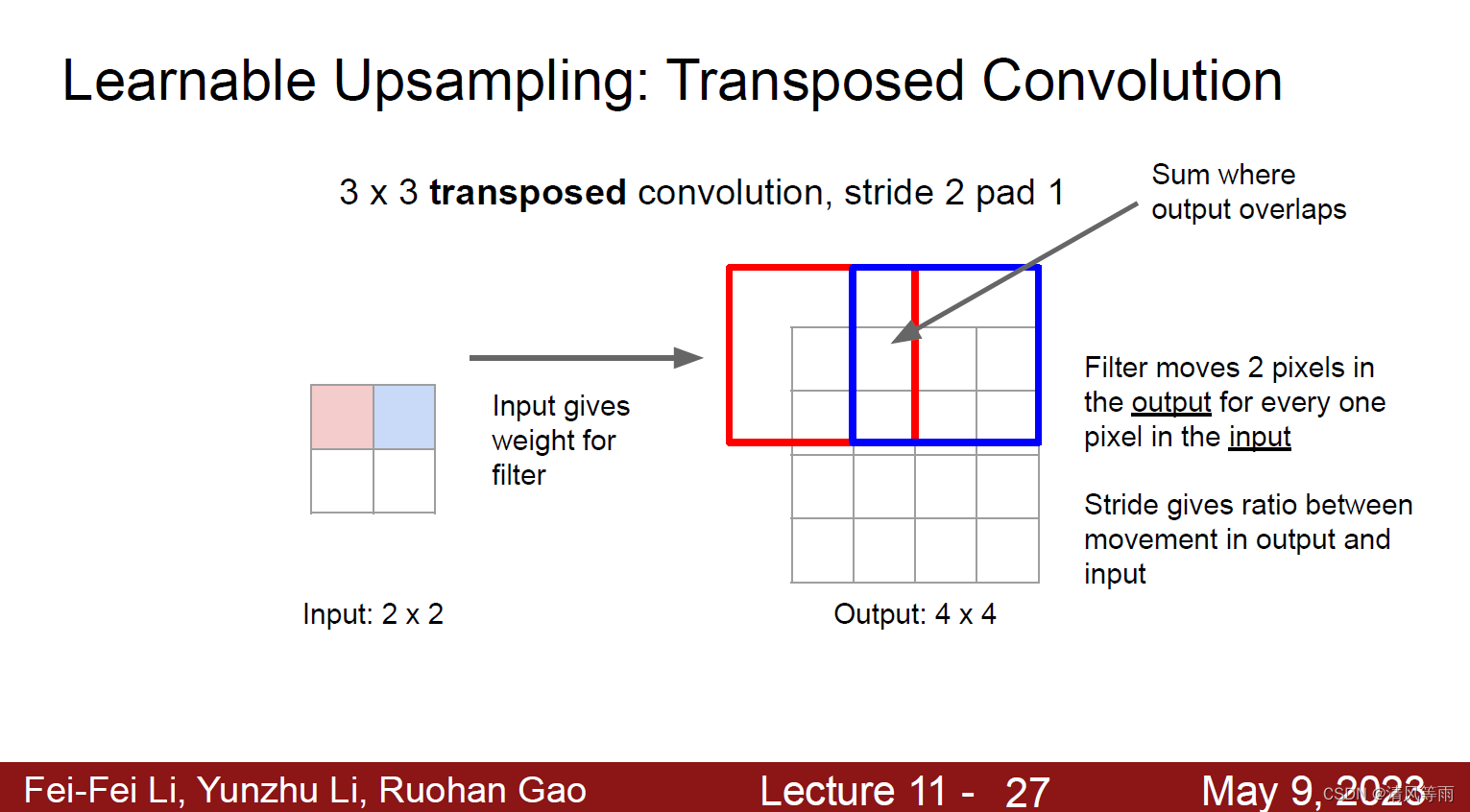
而对于卷积操作,在上采样中则称之为转置卷积(Transposed Convolution)。转置卷积的步骤如下:
- 在输入特征图元素间填充s-1行和列的0(其中s表示转置卷积的步距stride)
- 在输入特征图四周填充k-p-1行和列的0(其中k表示转置卷积的kernel_size大小,p为转置卷积的padding,注意这里的padding和卷积操作中有些不同)
- 将卷积核参数上下、左右翻转(我也不是很清楚为什么,查找相关文章都是这么写的)
- 做正常卷积运算
目标检测
目标检测其实就是对图像进行分类并定位物体所在位置(如下图)。其检测方法主要有两类:单阶段检测以及双阶段检测。单阶段检测即直接在网络中提取特征来预测物体分类和位置,例如YOLO、SSD等。而双阶段检测则先生成一系列的候选区域,再对候选区域进行分类,例如 R-CNN、Fast R-CNN、Faster R-CNN等。

双阶段检测
对于图像分割,我们可以使用滑动窗口来对每个窗口进行分类,最终再做分割。那么对于目标检测,也可以使用类似的方法,然后用卷积神经网络来对这些图片进行分类,以区分它是目标还是背景(如下面第一张图),但这种方法需要将CNN用在大量的裁剪图片中,并分类这些图片(如下面第二张图),这导致计算量非常的大。


R-CNN
为了减少计算量,有人提出了一个很好的想法,那就是感兴趣区域候选,即在一张图片中对象可能出现的位置。由此,衍生出了R-CNN算法。即先在图片中选取一些目标对象可能出现的位置的区域,然后再对这些区域进行回归和分类。其主要流程为:
- 通过一个方法(比如说选择性搜索,Selective Search)来选取大概2000个感兴趣区域(Regions of Interest, ROI)。
- 将每个感兴趣区域统一缩放成224×224的大小。
- 将每个感兴趣区域输入到卷积神经网络中(使用经过ImageNet预训练的权重)。
- 通过SVM对这些区域进行分类。
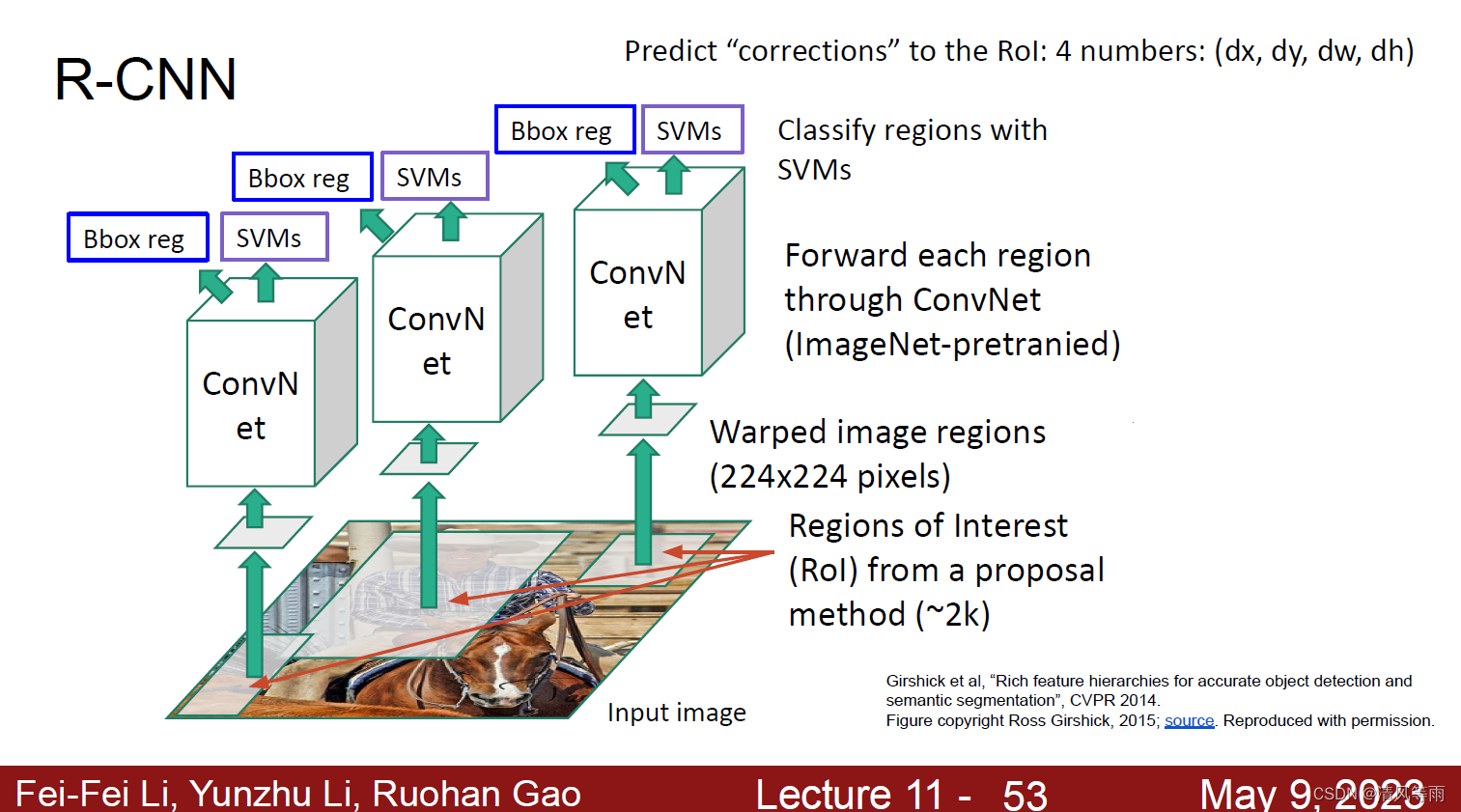
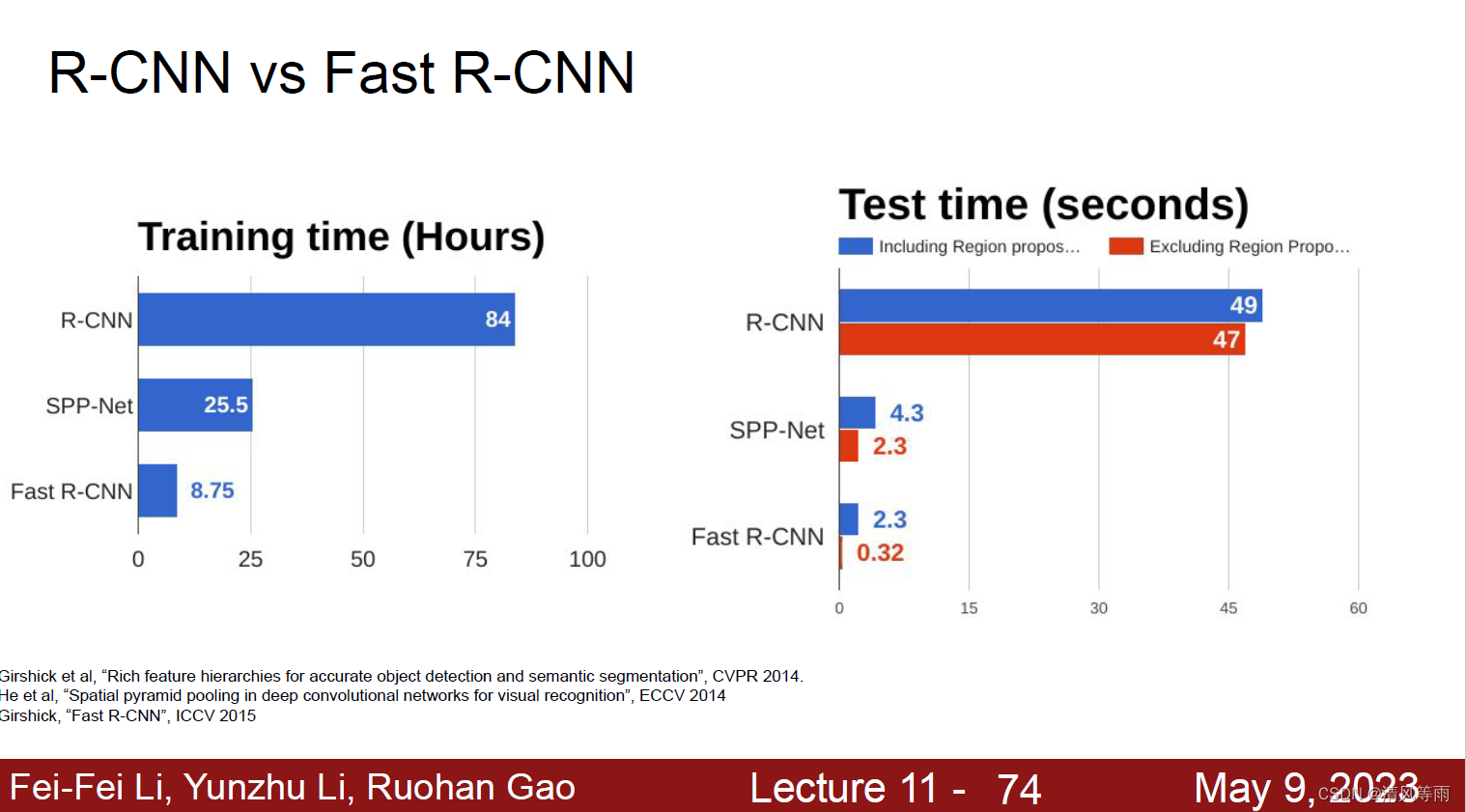
这个方法虽然改善了通过滑窗进行目标检测方法中,窗口数量过多的问题,但其仍然需要独立处理将近2000个感兴趣区域,这导致检测速度非常慢。
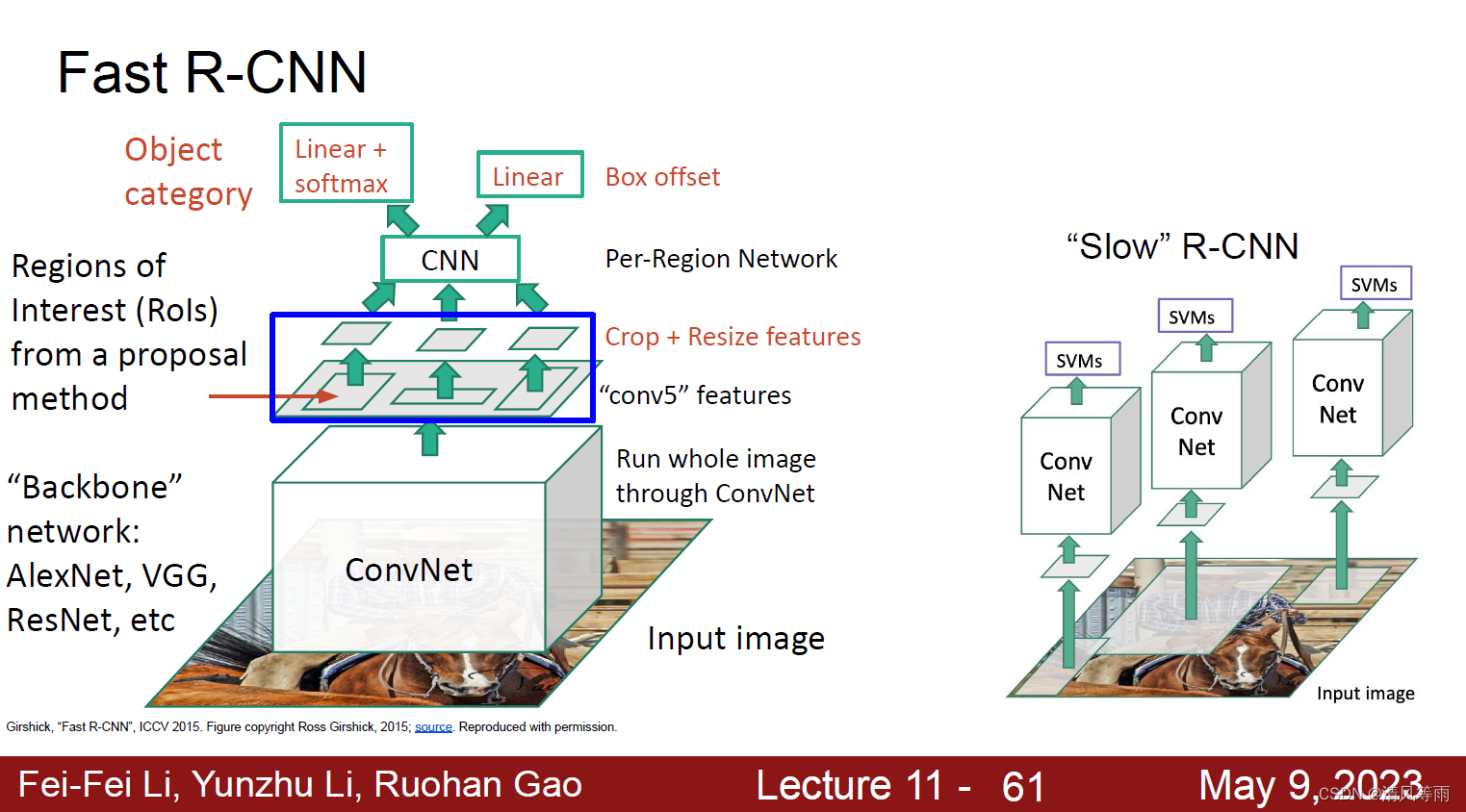
Fast R-CNN
对于R-CNN的不足,一个好的办法就是将原图放进CNN中,然后再在之后的卷积操作中裁剪特征图。这就是Fast R-CNN的核心思想之一。此外,它将 classification 和 detection 的部分融合到 CNN 中,不再使用额外的 SVM 和 Regressor,极大地减少了计算量和训练速度;并且使用 ROI pooling 将在特征图上不同尺度大小的ROI 归一化成相同大小,这样就可以通过全连接层。其过程如下图所示,首先先将原图放到一个网络模型中进行特征提取,再从提取到的特征图中选取ROI(ROI通过Region Proposal Network,也就是RPN提取),并送到CNN中进行分类和定位。
ROI Pool
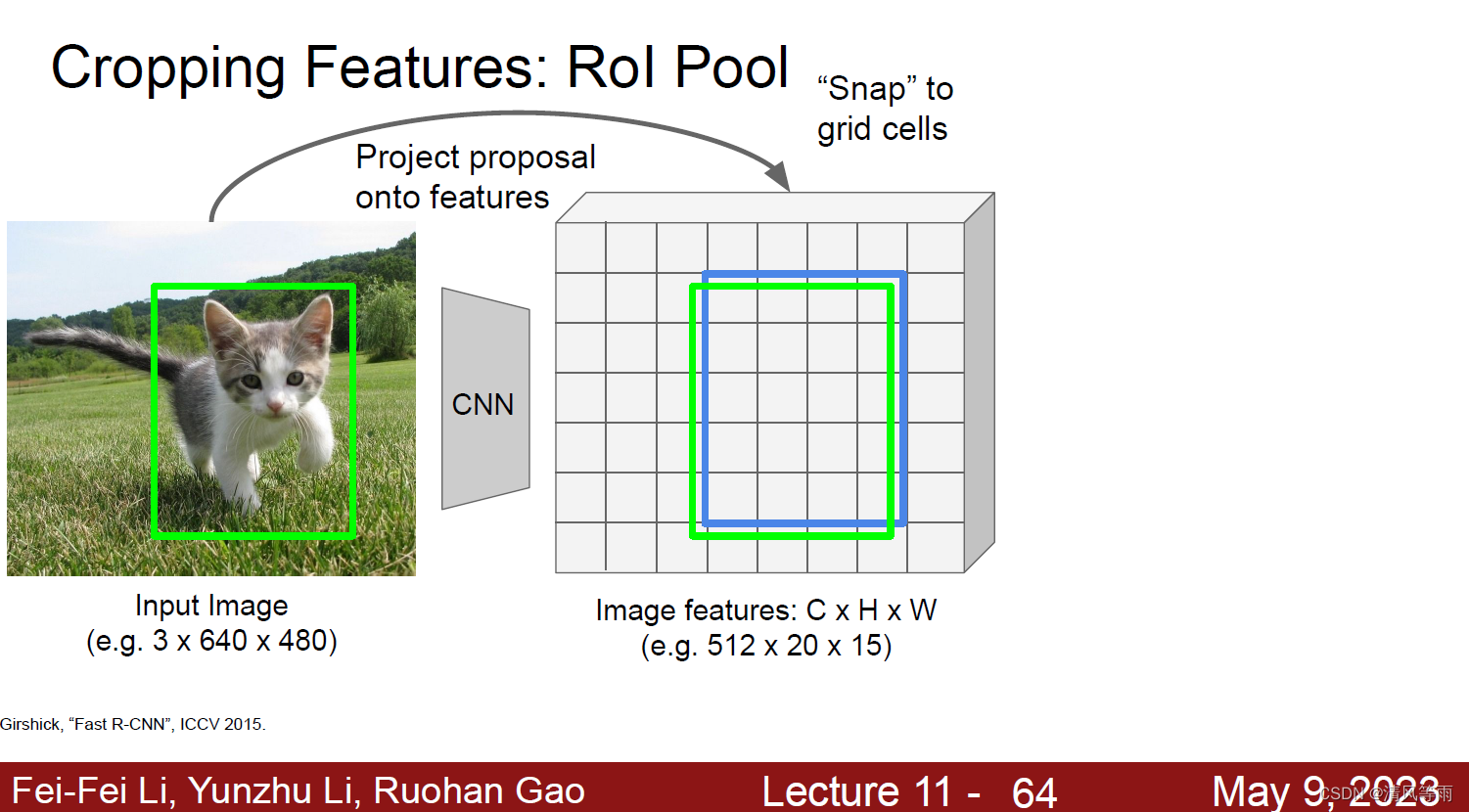
RoI Pool直接从特征图中截取各个RoI的特征,并且输出时各个RoI的特征变成大小一样的了。其流程为:
-
先得到ROI
-
将ROI对其到网格,即根据输入图像,将ROI映射到特征图的对应位置(由于经过特征尺度变换,导致RoI的特征坐标可能会落在特征图的单元之间)
-
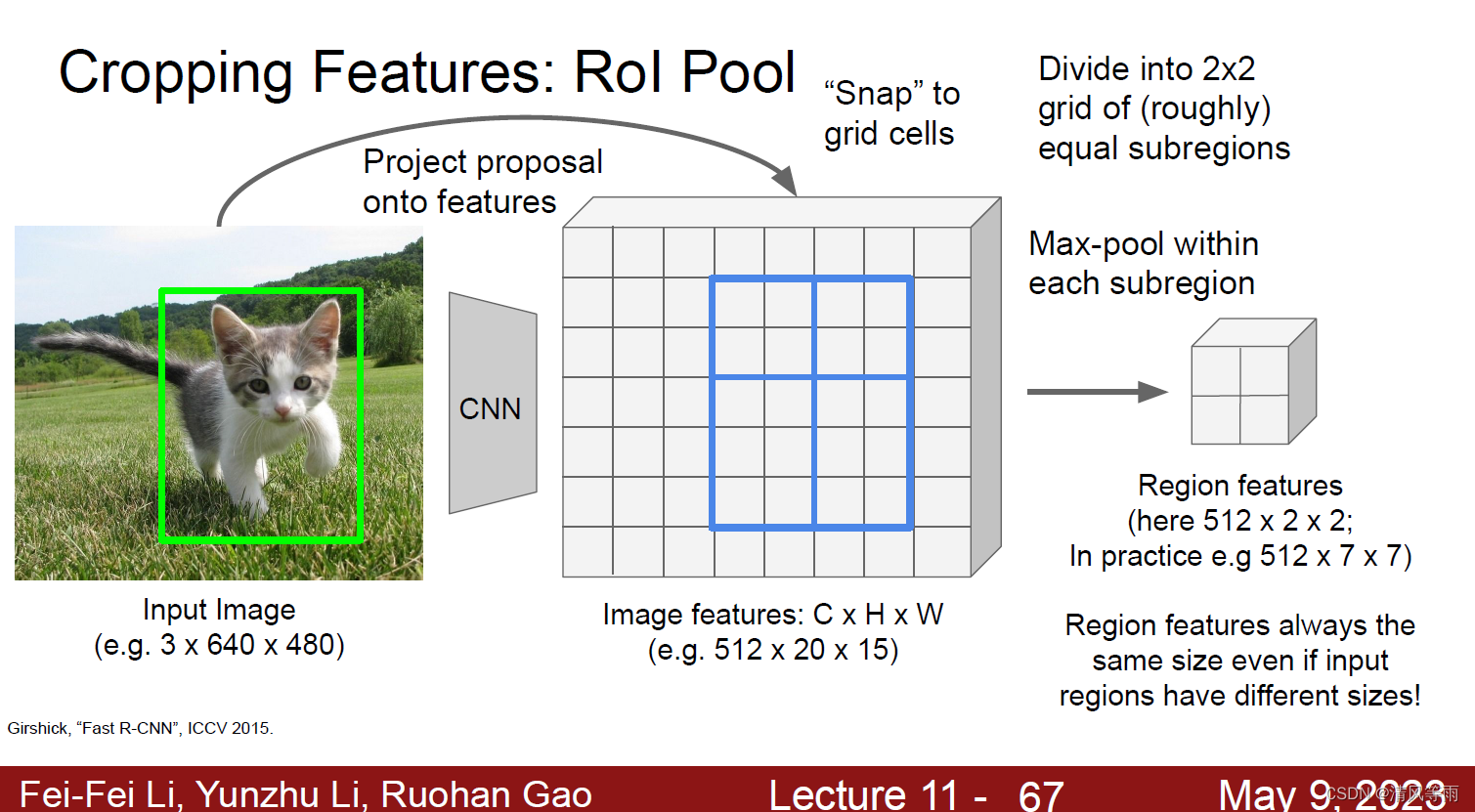
将映射后的区域划分为相同大小的区域(区域数量与输出的维度相同)。这里将网格粗略地分为H×W个子网格区域,然后将上一步得到的RoI特征进一步细分为量化的空间单元。以下图为例,为了得到一个512×2×2的输出特征图,首先将上一步的RoI特征划分为2×2个特征单元。如果不能通过直接均分得到子区域,那么可以分别采取向上取整和向下取整得到对应的单元尺寸大小。即对于4×5的特征图,对于宽度方向,划分的位置为4/2=2,而高度方向,则是5/2=2.5,由于2.5不是整数,因此可以通过向上取整和向下取整来得到子区域的高度为2和3。
-
对划分的每个区域进行最大池化操作。
ROI Align
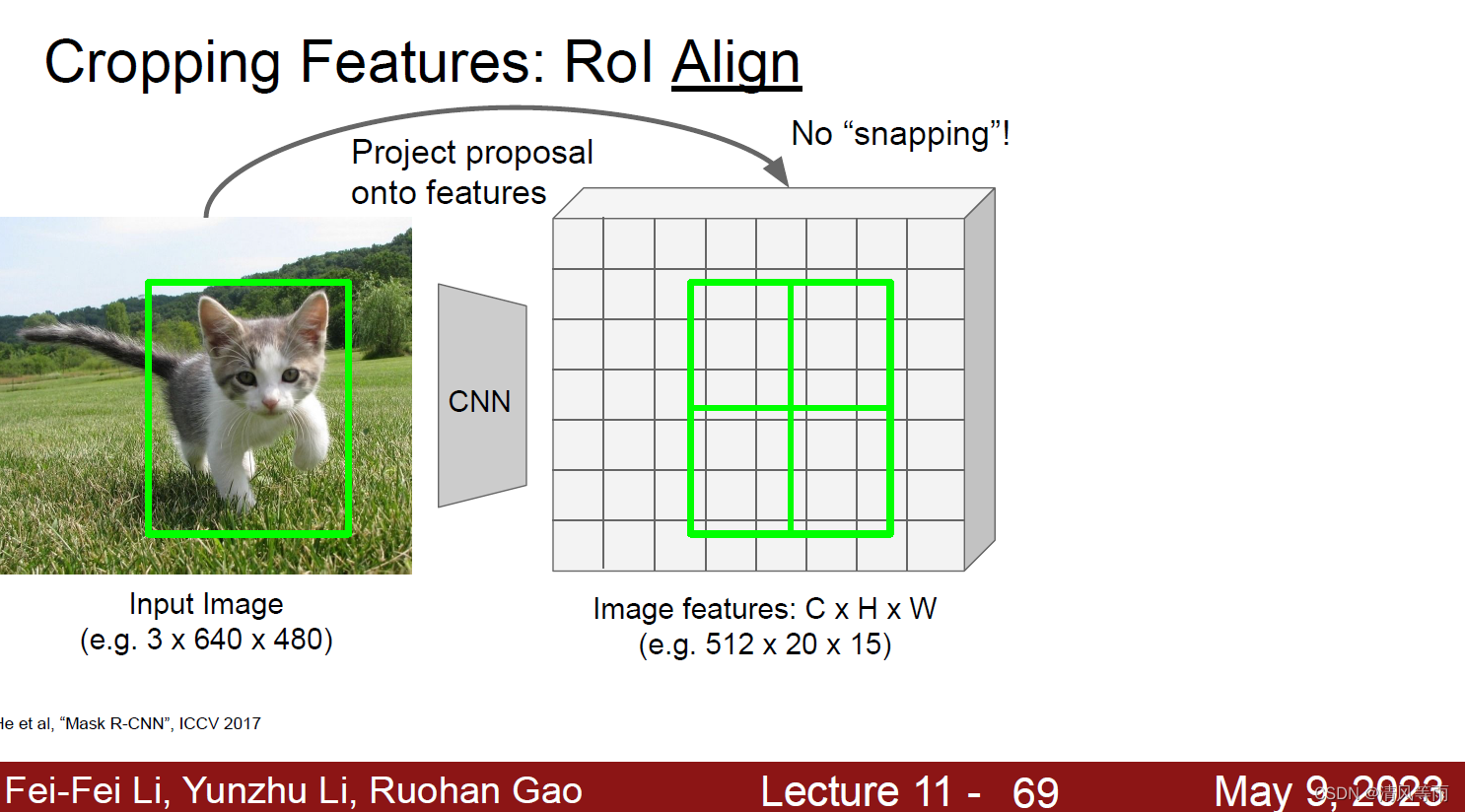
通过ROI Pool的流程我们知道,在进行步骤2和步骤3的时候,可能会导致区域特征有些轻微错位(misaligned),这些操作在RoI和提取到的特征之间引入了偏差。为此,提出了ROI Align(这个其实是在Mask R-CNN中提出的,因为这些偏差可能不会影响对分类任务,但它对预测像素精度mask有很大的负面影响。但是这里也稍微提及一下)。它的流程为:
-
对每个ROI保持浮点数边界不做对齐(即不对齐网格单元),同时,将网格平均分为H×W个子网格区域,每个单元的边界也不做量化。
-
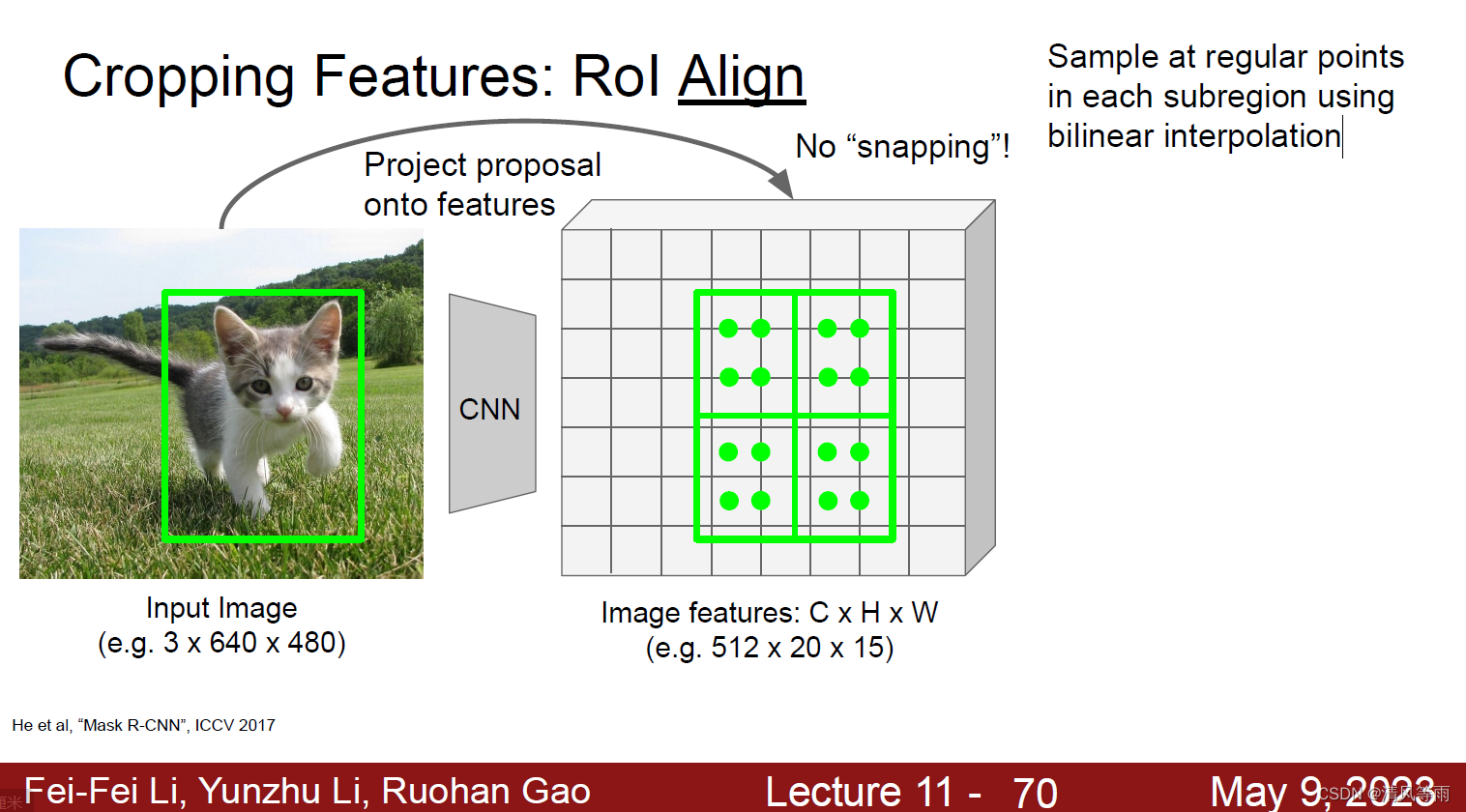
对于每个区域选择4个规则采样点(分别对应将区域进一步平均分为四个区域,取每个子区域的中点)。
-
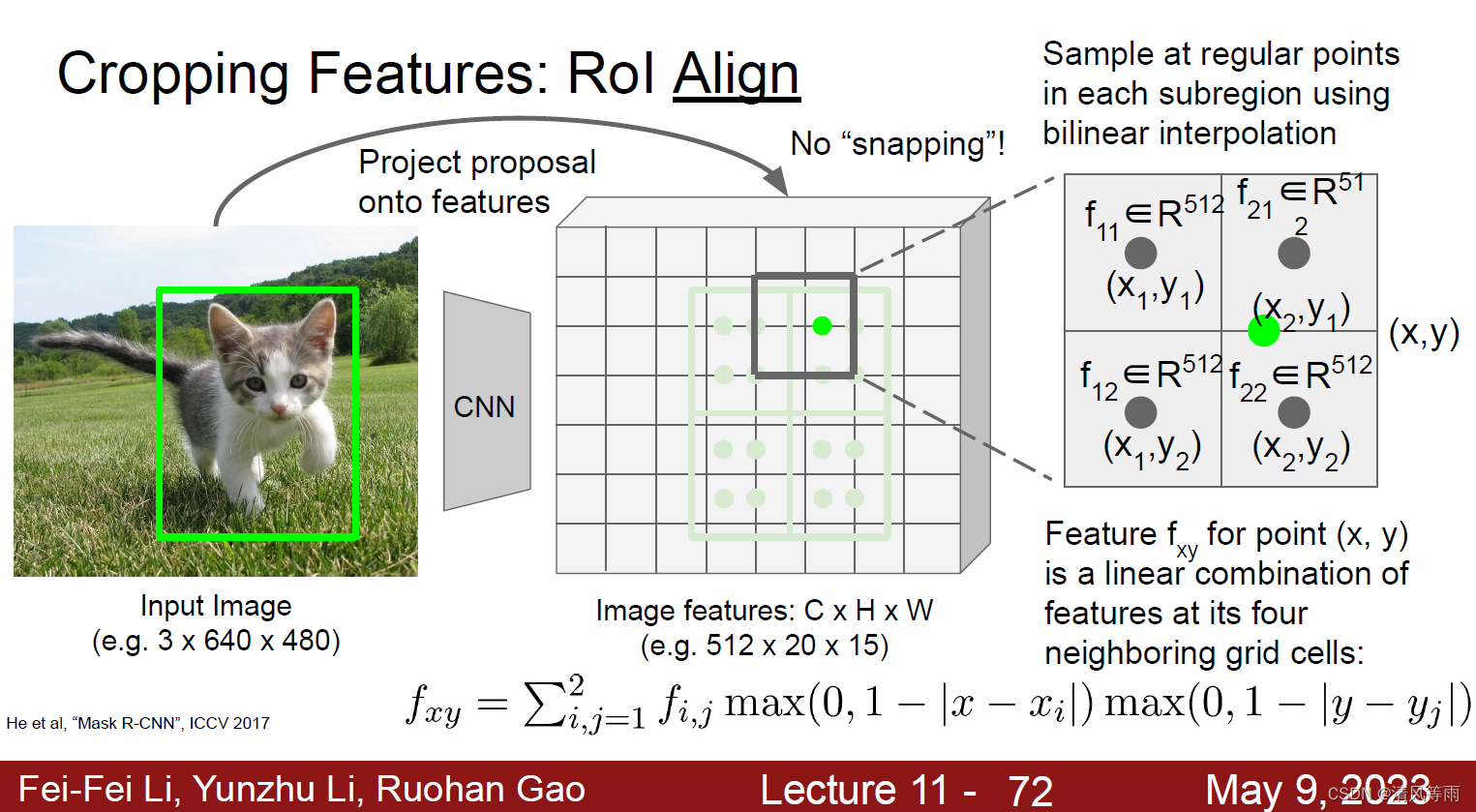
利用双线性插值(双线性插值本质上是目标像素所相邻的四个像素, 分别以像素对应的对角像素与目标像素的构成的矩形区域为权重,像素大小为值的加权和)计算得到四个采用点的像素值大小。
-
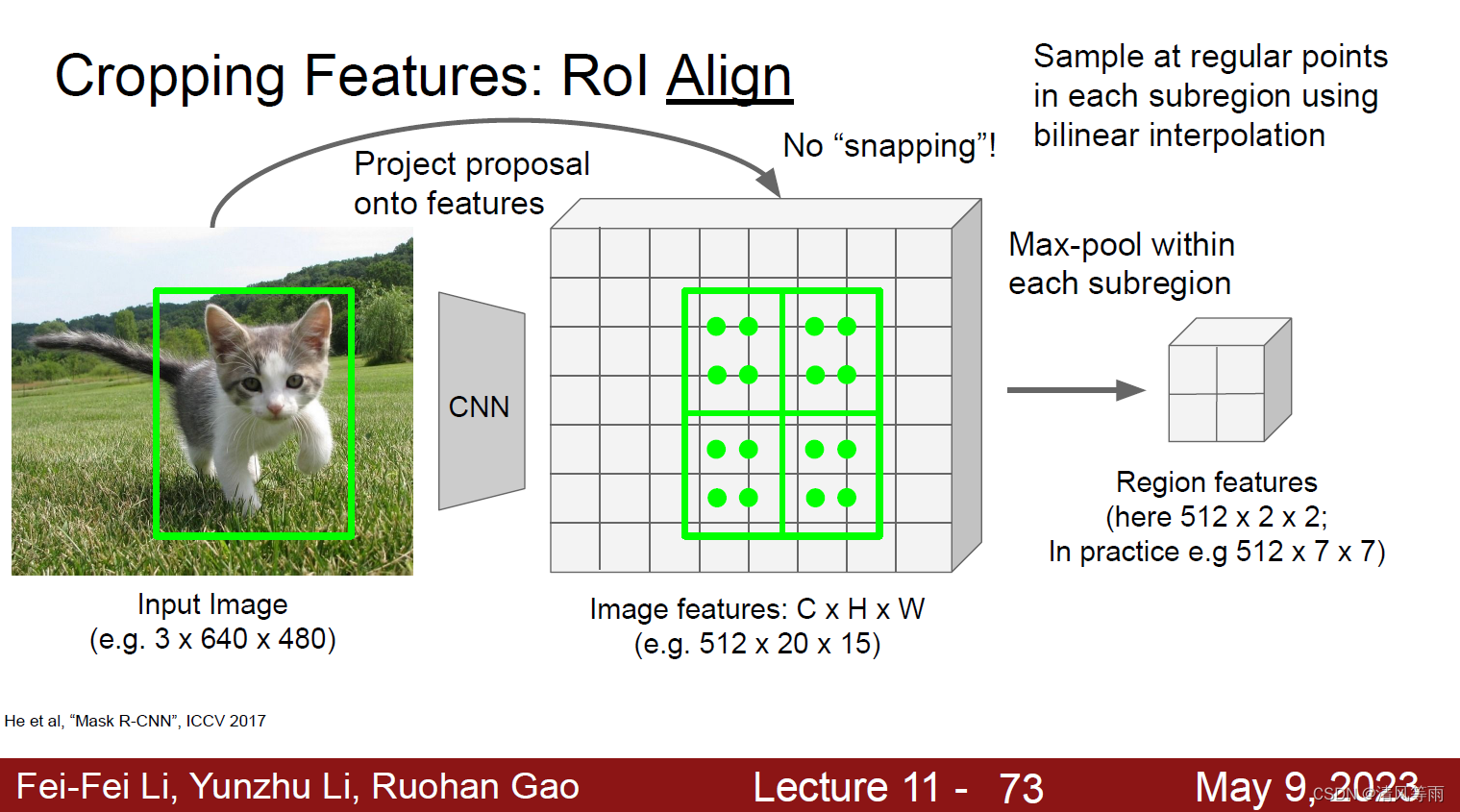
利用最大池化或者平均池化操作分别对每个子区域执行聚合操作,得到最终的特征图。
Fast R-CNN和R-CNN对比
单阶段检测
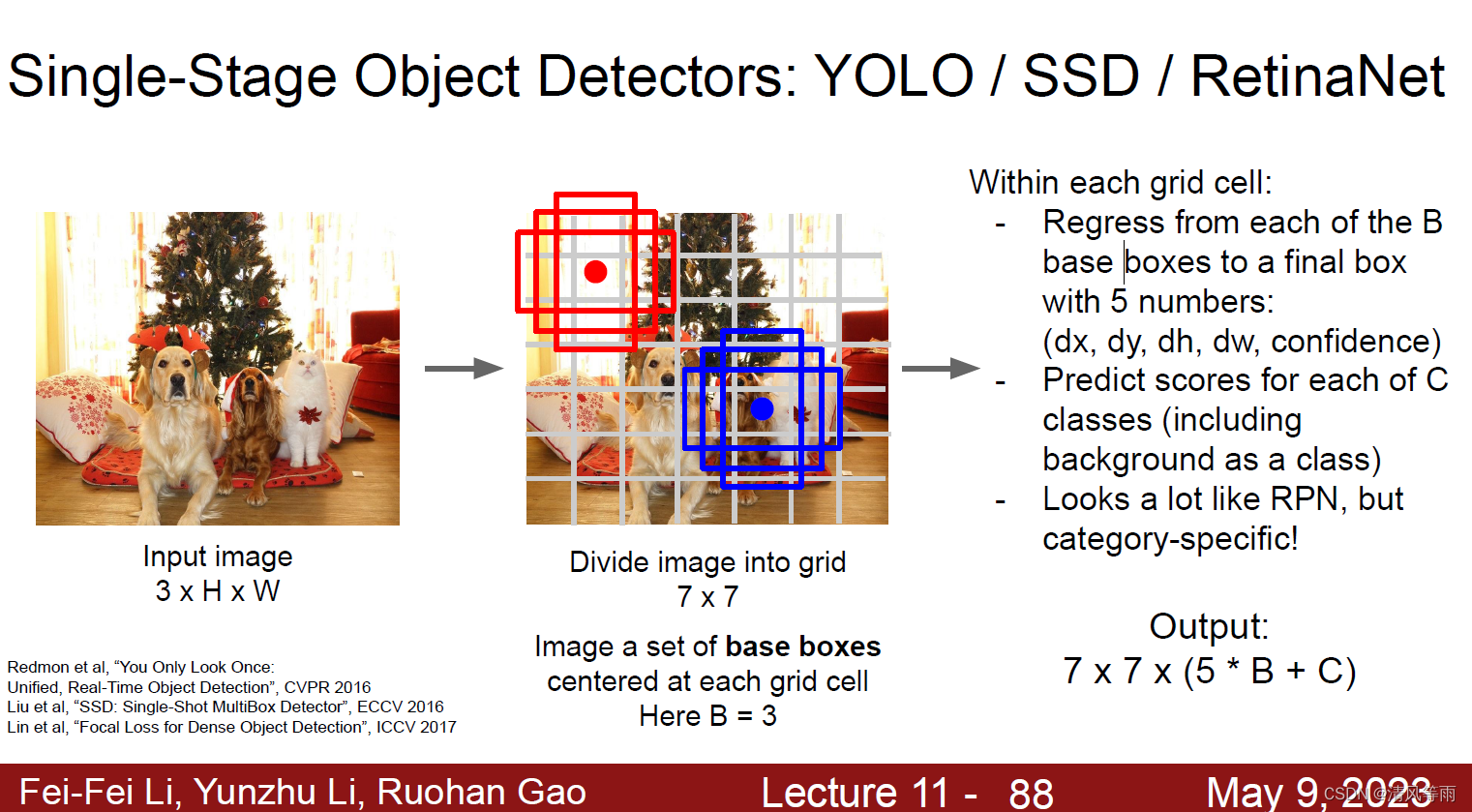
单阶段目标检测与双阶段目标检测最大的不同在于它直接对目标进行定位和分类。其大体流程如下:
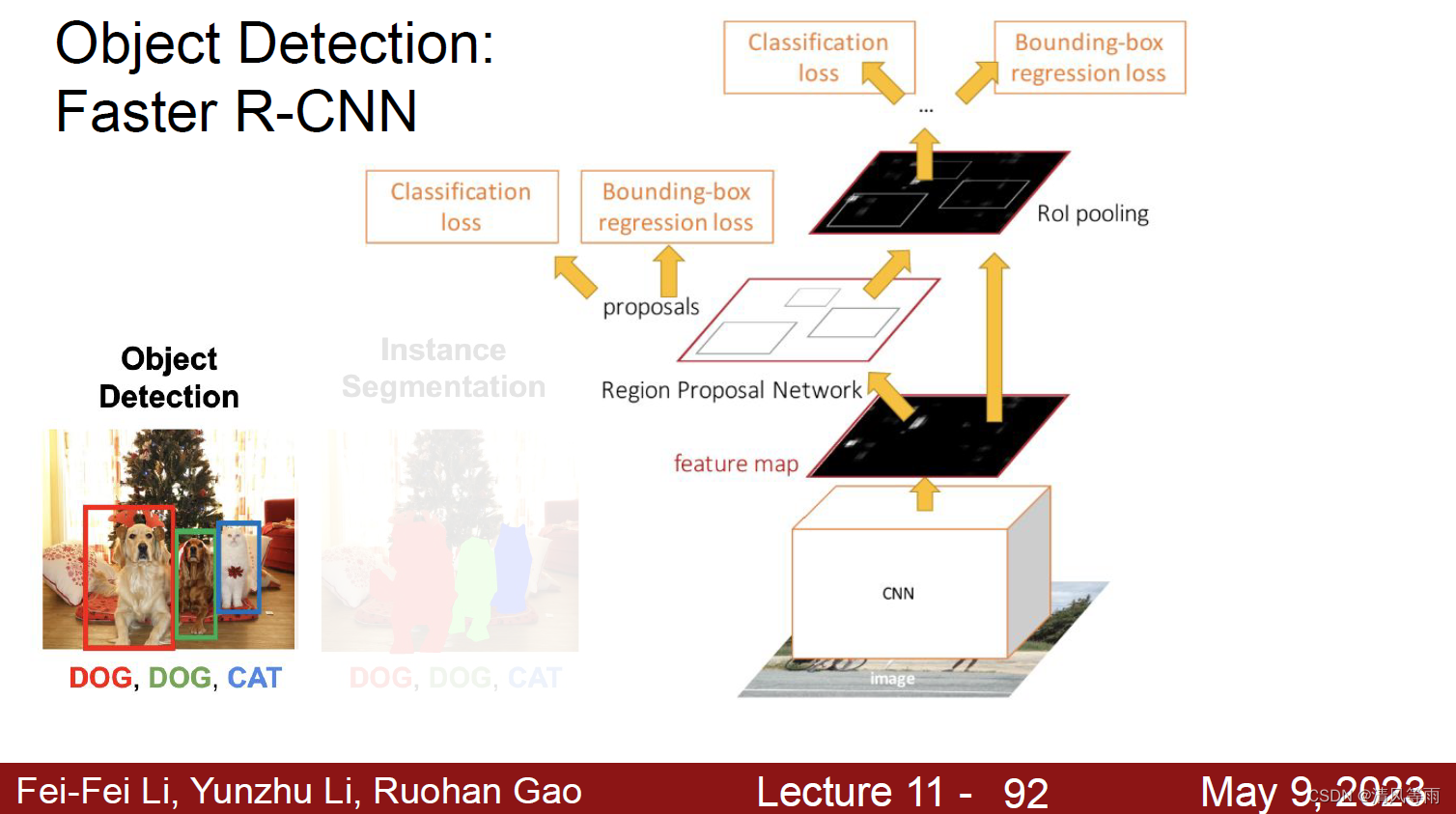
实例分割
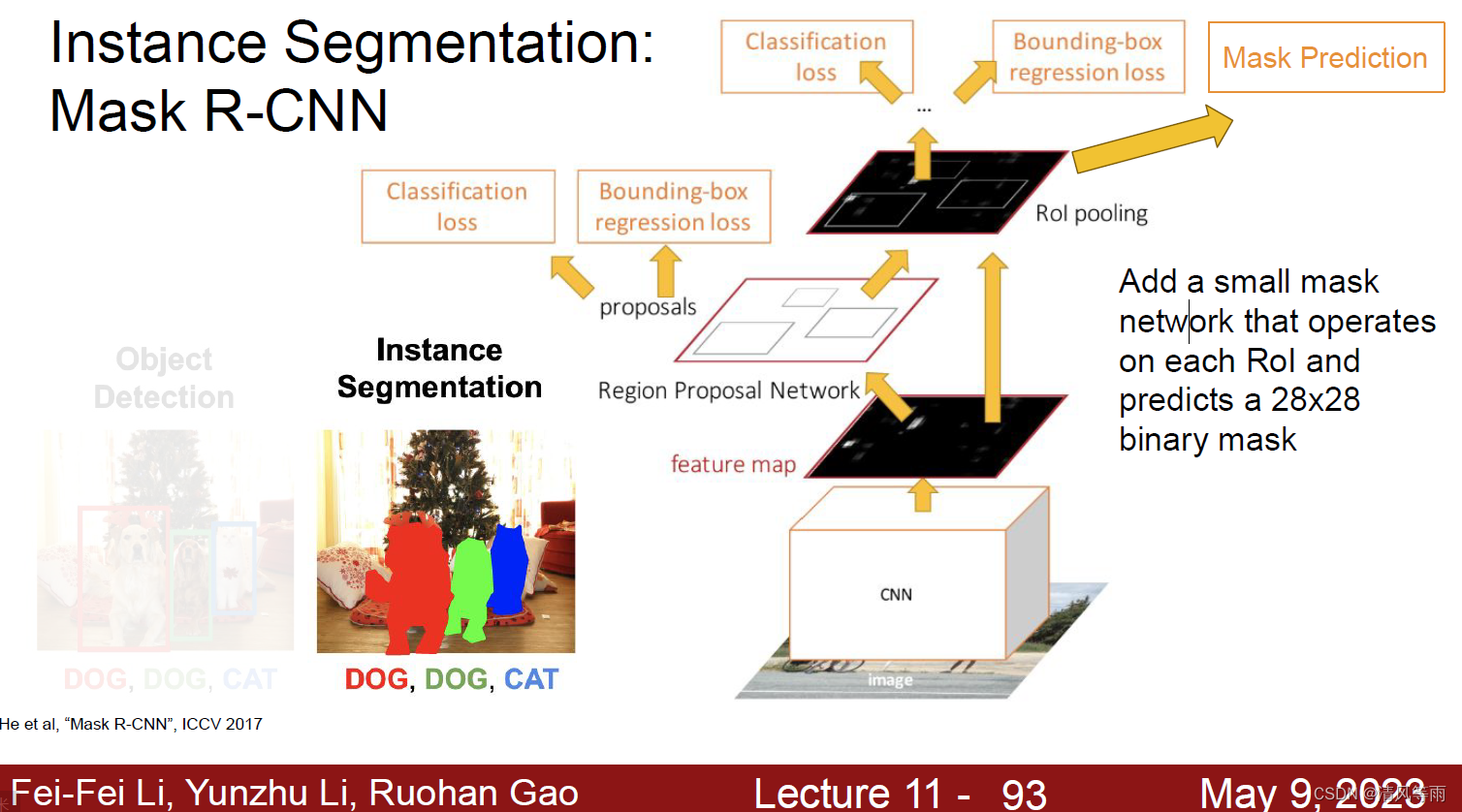
在了解实例分割前,我们先回顾一下目标检测中Fast R-CNN的一个流程(如上图)。其实,对于实例分割,一个简单易懂的说法就是,在目标检测的基础上再添加一个小的mask预测网络,用以预测每个ROI的二进制掩码(binary mask)(如下图,mask R-CNN)。
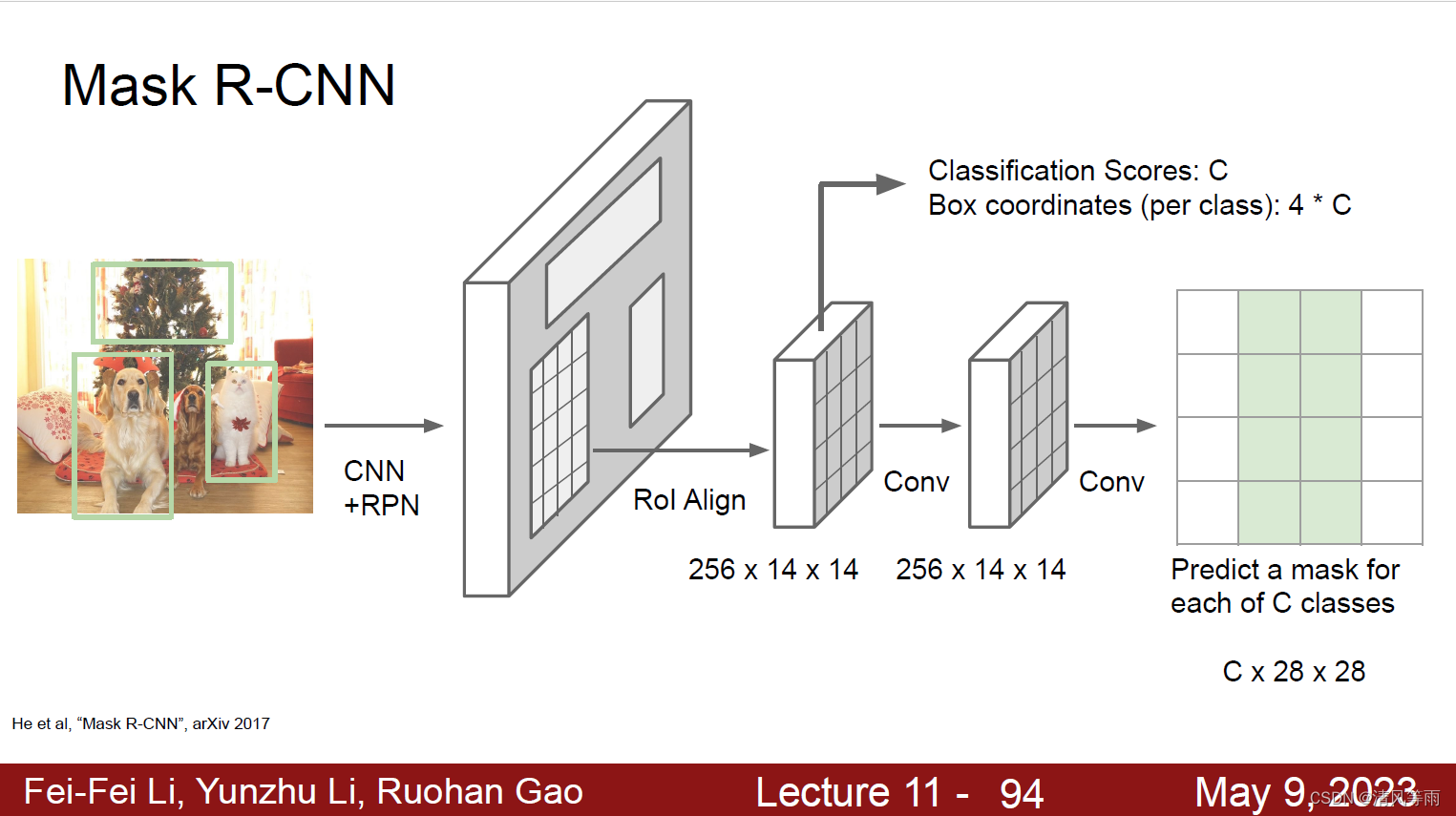
其他
对于实例分割,我们可以看做是目标检测+语义分割,那么,这里还有其他的一些方法与目标检测相结合,如:
-
编写字幕(目标检测+字幕提示)。如此,可以应用于视频中


-
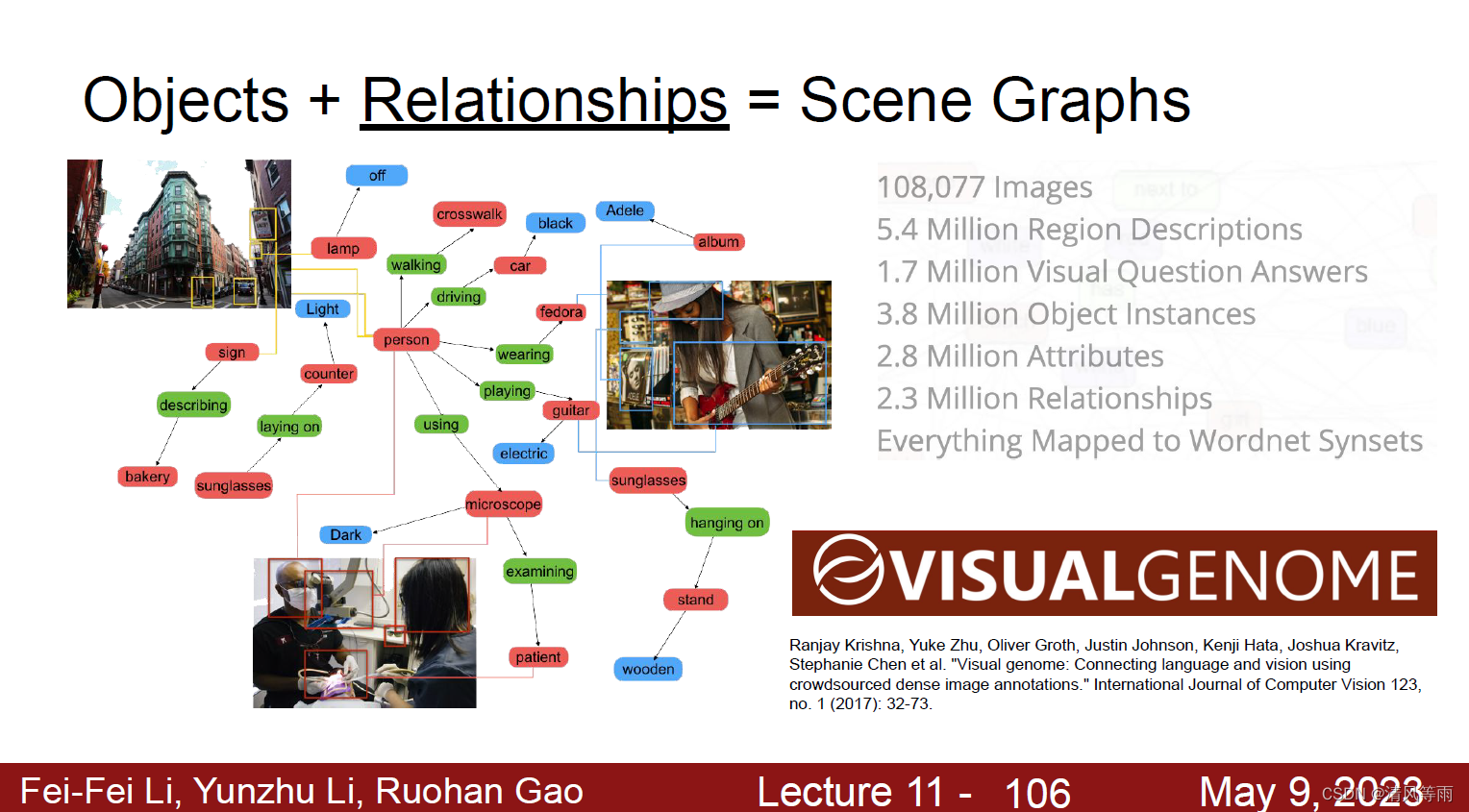
场景图(目标检测+关系组成)

-
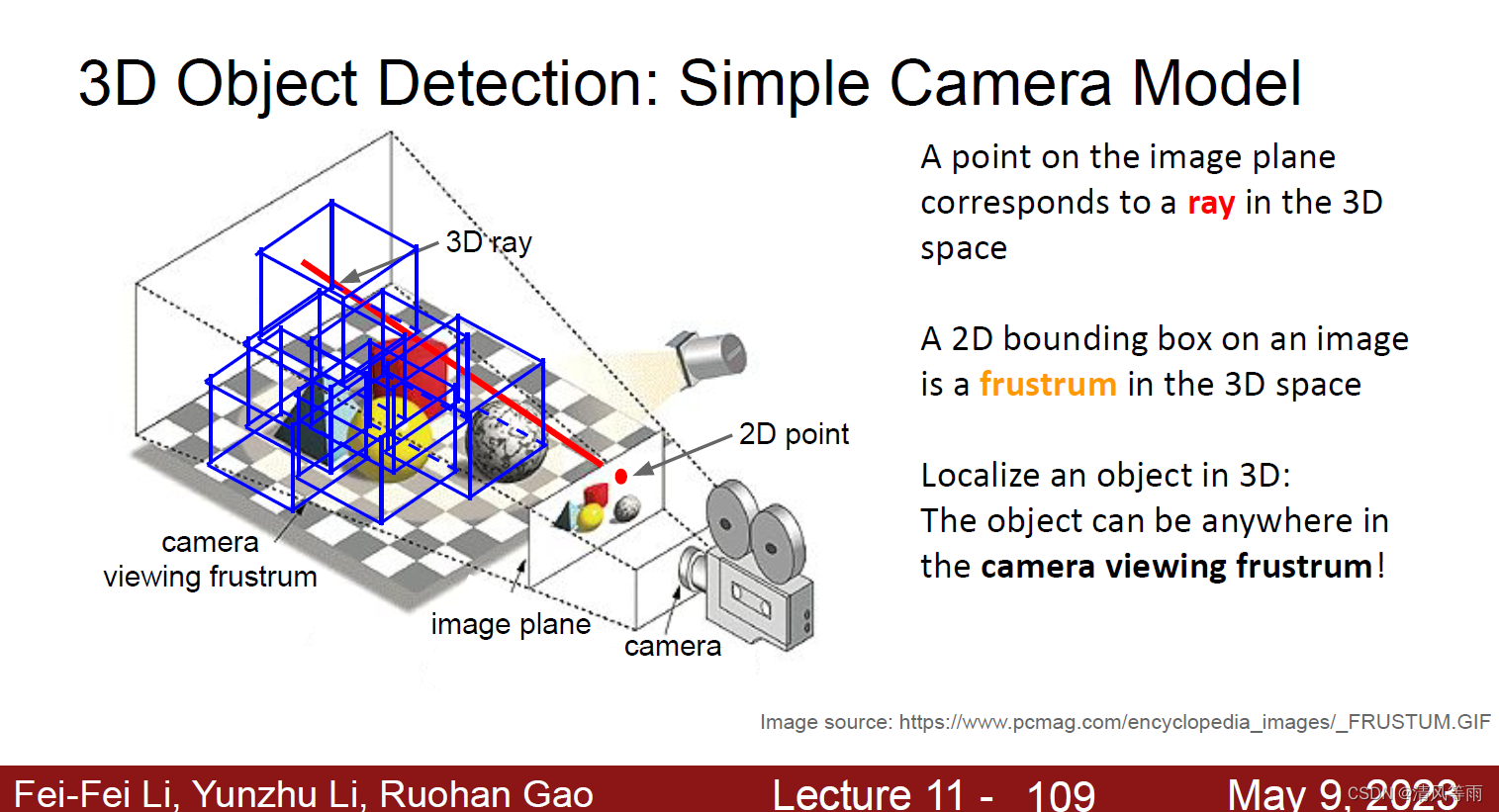
3D目标检测

总结
在这一讲中,我们重点了解了语义分割以及目标检测。同时,介绍了一下实例分割和一些其他的与目标检测相结合的视觉任务。
注
本文所有图片均来自于cs231公开课的网站之中。















 2211
2211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









