







1、文件上传下载io流程
本地读写文件流程:
使用FileInputStream根据文件路径读取文件流到InputStream中,使用while循环读取inputStream的每个字节,将其存到一个byte数组。
写文件则将要写的内容使用getBytes方法将其转成字节数组,接着使用File类新建一个文件,其中可能会抛出文件找不到等异常,要做对应的catch处理,然后用write将字节数组输出。
最后要做close和flush操作。
文件服务器上传下载流程:
后端通过MultipartRequest对象获取上传文件的文件路径,接着通过PrintWriter将该文件的字节流输出到指定的文件上以此完成上传。
下载操作则,根据文件路径到指定目录下获取文件,将文件对象转为byte数组,创建File对象,将其write到前端。
2、mysql索引原理,b树与b+树区别
mysql索引原理是快速查找,通过快速匹配到指定字段找到对应行数据。所以索引的字段长度也会影响到查询的速度。
B树:
每个节点既保存索引,又保存数据
B+树
只有叶子节点保存数据
增加了相邻接点的指向指针。
B+树
- 所有的叶子结点使用链表相连,便于区间查找和遍历。B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
- b+树的中间节点不保存数据,能容纳更多节点元素。
B树
B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
索引失效
1.有or必全有索引;
2.复合索引未用左列字段;
3.like以%开头;
4.需要类型转换;
5.where中索引列有运算;
6.where中索引列使用了函数;
7.如果mysql觉得全表扫描更快时(数据少);
3、事务的特点
原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)
1、原子性:原子性即不可分割性,含义是一个事务必须把它产生的所有更改作为一个单独的工作单元进行提交或者回滚。
2、一致性:工作单元中每个动作的执行结果必须被落实,不能出现有的成功了而有的失败了。
3、隔离性:隔离性指的是各个独立事务之间的交互程度,是由一致性和并发性共同决定的。
4、持久性指的是一个事务一旦提交,那它对数据库的更改就应该是永久的,不会因系统的失败而丢失。
4、事务的原理
Java事务的类型有三种:JDBC事务、JTA(Java Transaction API)事务、容器事务。
1、JDBC事务 JDBC 事务是用 Connection 对象控制的。JDBC Connection 接口( java.sql.Connection )提供了两种事务模式:自动提交和手工提交。 java.sql.Connection 提供了以下控制事务的方法:public void setAutoCommit(boolean)public boolean getAutoCommit()public void commit()public void rollback() 使用 JDBC 事务界定时,您可以将多个 SQL 语句结合到一个事务中。JDBC 事务的一个缺点是事务的范围局限于一个数据库连接。一个 JDBC 事务不能跨越多个数据库。
2、JTA是一种高层的,与实现无关的,与协议无关的API,应用程序和应用服务器可以使用JTA来访问事务。 JTA允许应用程序执行分布式事务处理——在两个或多个网络计算机资源上访问并且更新数据,这些数据可以分布在多个数据库上。JDBC驱动程序的JTA支持极大地增强了数据访问能力。
3、容器事务主要是J2EE应用服务器提供的,容器事务大多是基于JTA完成,这是一个基于JNDI的,相当复杂的API实现。相对编码实现JTA事务管理, 我们可以通过EJB容器提供的容器事务管理机制(CMT)完成同一个功能,这项功能由J2EE应用服务器提供。
5、mysql事务的默认等级
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysql默认的事务隔离级别为repeatable-read
//
mybatis事务
MyBatis将事务抽象成了Transaction接口:其接口定义如下:
获取connection的创建(create)、提交(commit)、回滚(rollback)、关闭(close)功能。
MyBatis的事务管理分为两种形式:
- 使用JDBC的事务管理机制:即利用java.sql.Connection对象完成对事务的提交(commit())、回滚(rollback())、关闭(close())等。
- 使用MANAGED的事务管理机制:这种机制MyBatis自身不会去实现事务管理,而是让程序的容器如(JBOSS,Weblogic)来实现对事务的管理。
6、==和equals的区别
对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
7、Oracle与mysql区别、索引类别等等
1、对事务的提交
MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮
2、 分页查询
MySQL是直接在SQL语句中写"select... from ...where...limit x, y",有limit就可以实现分页;而Oracle则是需要用到伪列ROWNUM和嵌套查询
3、事务隔离级别
MySQL是read commited的隔离级别,而Oracle是repeatable read的隔离级别,同时二者都支持serializable串行化事务隔离级别,可以实现最高级别的
读一致性。每个session提交后其他session才能看到提交的更改。Oracle通过在undo表空间中构造多版本数据块来实现读一致性,每个session
查询时,如果对应的数据块发生变化,Oracle会在undo表空间中为这个session构造它查询时的旧的数据块
MySQL没有类似Oracle的构造多版本数据块的机制,只支持read commited的隔离级别。一个session读取数据时,其他session不能更改数据,但
可以在表最后插入数据。session更新数据时,要加上排它锁,其他session无法访问数据
4、对事务的支持
MySQL在innodb存储引擎的行级锁的情况下才可支持事务,而Oracle则完全支持事务
5、保存数据的持久性
MySQL是在数据库更新或者重启,则会丢失数据,Oracle把提交的sql操作线写入了在线联机日志文件中,保持到了磁盘上,可以随时恢复
6、并发性
MySQL以表级锁为主,对资源锁定的粒度很大,如果一个session对一个表加锁时间过长,会让其他session无法更新此表中的数据。
虽然InnoDB引擎的表可以用行级锁,但这个行级锁的机制依赖于表的索引,如果表没有索引,或者sql语句没有使用索引,那么仍然使用表级锁。
Oracle使用行级锁,对资源锁定的粒度要小很多,只是锁定sql需要的资源,并且加锁是在数据库中的数据行上,不依赖与索引。所以Oracle对并
发性的支持要好很多。
7、逻辑备份
MySQL逻辑备份时要锁定数据,才能保证备份的数据是一致的,影响业务正常的dml使用,Oracle逻辑备份时不锁定数据,且备份的数据是一致
8、 复制
MySQL:复制服务器配置简单,但主库出问题时,丛库有可能丢失一定的数据。且需要手工切换丛库到主库。
Oracle:既有推或拉式的传统数据复制,也有dataguard的双机或多机容灾机制,主库出现问题是,可以自动切换备库到主库,但配置管理较复杂。
9、性能诊断
MySQL的诊断调优方法较少,主要有慢查询日志。
Oracle有各种成熟的性能诊断调优工具,能实现很多自动分析、诊断功能。比如awr、addm、sqltrace、tkproof等
10、权限与安全
MySQL的用户与主机有关,感觉没有什么意义,另外更容易被仿冒主机及ip有可乘之机。
Oracle的权限与安全概念比较传统,中规中矩。
11、分区表和分区索引
MySQL的分区表还不太成熟稳定。
Oracle的分区表和分区索引功能很成熟,可以提高用户访问db的体验。
12、管理工具
MySQL管理工具较少,在linux下的管理工具的安装有时要安装额外的包(phpmyadmin, etc),有一定复杂性。
Oracle有多种成熟的命令行、图形界面、web管理工具,还有很多第三方的管理工具,管理极其方便高效。
13、最重要的区别
MySQL是轻量型数据库,并且免费,没有服务恢复数据。
Oracle是重量型数据库,收费,Oracle公司对Oracle数据库有任何服务。
Oracle索引
非唯一索引(最常用) NonUnique
唯一索引 Unique
位图索引 Bitmap
分区索引 Partitioned
非分区索引 NonPartitioned
正常型B树 Normal
基于函数的索引 Function-based
B-tree:
适合与大量的增、删、改(OLTP);
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)
典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
Bitmap:
适合与决策支持系统;
做UPDATE代价非常高;
非常适合OR操作符的查询;
基数比较少的时候才能建位图索引;
8、什么时候要开启索引
加快查询,修改操作远小于查询操作
9、什么是分布式部署
分布式就是通过计算机网络将后端工作分布到多台主机上,多个主机一起协同完成工作。
10、什么是微服务
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通(通常是基于HTTP的Restful API).每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建
11、hashMap的底层结构
HashMap实际上是一个“链表的数组”的数据结构,每个元素存放链表头结点的数组,即数组和链表的结合体。
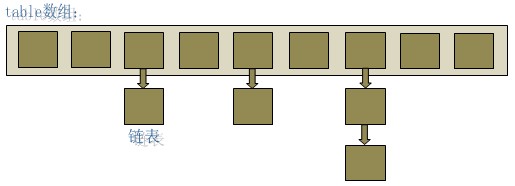
HashMap底层就是一个数组,数组中的每一项又是一个链表。当新建一个HashMap的时候,就会初始化一个数组
Entry就是数组中的元素,每个Map.Entry就是一个key-value对,它持有一个指向下一个元素的引用,这就构成了链表。
12、stringbuffer和stringbuilder
String类是不可变类,任何对String的改变都 会引发新的String对象的生成;StringBuffer则是可变类,任何对它所指代的字符串的改变都不会产生新的对象。
String是final的。
StringBuffer和StringBuilder类的区别也是如此,他们的原理和操作基本相同,区别在于StringBufferd支持并发操作,线性安全的,适 合多线程中使用。StringBuilder不支持并发操作,线性不安全的,不适合多线程中使用。新引入的StringBuilder类不是线程安全的,但其在单线程中的性能比StringBuffer高。
//
final可以被继承吗?
1. final修饰的类,为最终类,该类不能被继承。如String 类
2. final修饰的方法可以被继承和重载,但不能被重写
3. final修饰的变量不能被修改,是个常量
13、springcloud(大致看看)
-
Eureka:服务注册于发现。
-
Feign:基于动态代理机制,根据注解和选择的机器,拼接请求 url 地址,发起请求。
-
Ribbon:实现负载均衡,从一个服务的多台机器中选择一台。
-
Hystrix:提供线程池,不同的服务走不同的线程池,实现了不同服务调用的隔离,避免了服务雪崩的问题。
-
Zuul:网关管理,由 Zuul 网关转发请求给对应的服务。
负载均衡的意义是什么?
在计算中,负载均衡可以改善跨计算机,计算机集群,网络链接,中央处理单元或磁盘驱动器等多种计算资源的工作负载分布。负载均衡旨在优化资源使用,最大吞吐量,最小响应时间并避免任何单一资源的过载。使用多个组件进行负载均衡而不是单个组件可能会通过冗余来提高可靠性和可用性。负载平衡通常涉及专用软件或硬件,例如多层交换机或域名系统服务进程。
14、redis持久化流程、方式
Redis 如同其他的存储组件一样,提供了两类持久化方式:快照,和全量追加日志。
快照:按照时间进行备份
日志:只记录更改操作。
持久化流程:将redis中的数据转化为二进制流存储在硬盘上,需要恢复时候将其反序列化恢复。
15、rabbitmq传递信息的方式
MQ两种消息传输方式,点对点(代码中的简单传递模式),发布/订阅(代码中路由模式)。要是你熟悉RabbitMQ SpringBoot配置的话,就是simple和direct。
16、rabbitmq消息队列流程
生产者生产过程:
(1)生产者连接到 RabbitMQ Broker 建立一个连接( Connection) ,开启 个信道 (Channel)
(2) 生产者声明一个交换器 ,并设置相关属性,比如交换机类型、是否持久化等
(3)生产者声明 个队列井设置相关属性,比如是否排他、是否持久化、是否自动删除等
(4)生产者通过路由键将交换器和队列绑定起来。
(5)生产者发送消息至 RabbitMQ Broker ,其中包含路由键、交换器等信息。
(6) 相应的交换器根据接收到的路由键查找相匹配的队列 如果找到 ,则将从生产者发送过来的消息存入相应的队列中。
(7) 如果没有找到 ,则根据生产者配置的属性选择丢弃还是回退给生产者
(8) 关闭信道。
(9) 关闭连接。
消费者接收消息的过程:
(1)消费者连接到 RabbitMQ Broker ,建立一个连接(Connection ,开启 个信道(Channel)
(2) 消费者向 RabbitMQ Broker 请求消费相应队列中的消息,可能会设置相应的回调函数, 以及做 些准备工作。
(3)等待 RabbitMQ Broker 回应并投递相应队列中的消息, 消费者接收消息。
(4) 消费者确认 ack) 接收到的消息
(5) RabbitMQ 从队列中删除相应己经被确认的消息
(6) 关闭信道。
(7)关闭连接。















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









