







本文采用虚拟机的方式来对hadoop集群进行搭建。
1.准备(搭建集群所用到的软件及系统前期配置):
- 虚拟机 : VMware
- linux:CentOS 6.5 .vmx
- sun公司的 jdk : jdk1.8.0_131
- ssh : 安装ssh,并设置免密
- hadoop : hadoop-3.0.0-alpha4
把CentOS进行克隆,克隆出两个,这样我们就有三台Linux了。
分别命名为:
master
node1
node2
在root用户下运行,对主机名进行修改 :
hostname // 查看当前系统主机名
vi /etc/sysconfig/network // 进入文件
HSOTNAME的属性赋值为想要修改的主机名 master
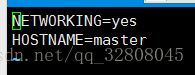
reboot // 重启 即可完成更改其他两台主机分别命名为 node1,node2。
对三台主机进行地址映射 :
ifconfig // 获取主机ip地址,为了完成映射
vi /etc/hosts // 打开添加地址映射 :
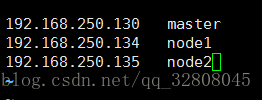
这样我们就不用每次都敲ip了,直接主机名称就可以了。(当然另外两台都需要进行相同的配置)
2. ssh免密的配置
rpm –qa | grep ssh // 验证ssh是否安装
yum install ssh -y // 若无信息列出即未安装,则进行安装 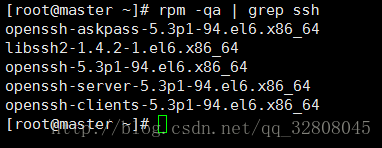
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa // 在~/.ssh/下生成公钥/私钥对 -P '' 密码为空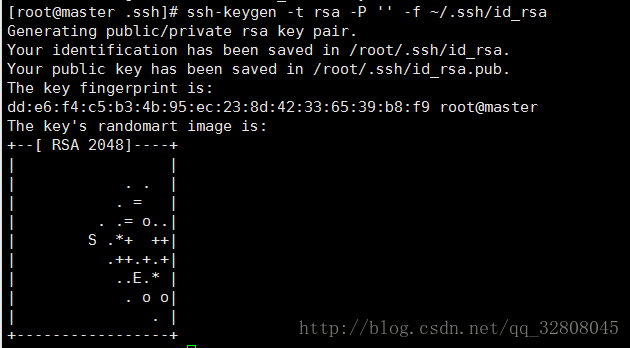
(randomart image看着也是挺有趣的。。。)
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys // 把公钥添加到authorzied_keys文件里
chmod 0600 ~/.ssh/authorized_keys // 修改authorized_keys的权限
ssh localhost // 验证ssh是否可以访问 验证ssh访问是否正常:
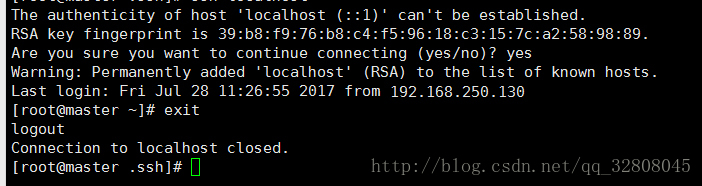
把另外两台机器也配好了之后,就可以做三台机器之间的联通了 :
scp id_rsa.pub node1:~/.ssh/master_rsa.pub // 把master公钥发给node1
再转到node1上执行 :
cat ~/.ssh/master_rsa.pub >> ~/.ssh/authorized_keys //把收到的公钥添加到文件中去node2 进行相同的步骤。(master的know_host文件中已经存在如节点node1的信息,以后连接都是免密的)。
就是三台虚拟机都相互把各自的公钥都发一遍,这样在每一台机器的~/.ssh/know_host文件里面都有其他节点的ssh信息。并把收到的公钥添加到authorized_keys文件下,这样下一次就可以免密登录了。
第一次访问时会出现询问

确定就好,之后都是秒连的。
遇到的问题:
1. ssh: connect to host node1 port 22: Connection timed out
检查/etc/hosts文件中的映射 地址->主机名 是否有错
2. Host key verification failed.
当询问 “…..(yes/no)?”时直接敲了个回车。 应敲yes
jdk的安装
- 下载
可以直接访问官网下载符合自己机器的jdk。
注意:需选中 Accept License Agreement - 解压
tar zxvf jdk-8u131-linux-x64.tar.gz // 解压jdk压缩包
- 配置环境变量
vi /etc/profile // 配置环境变量在空白处添加解压后jdk所在的路径 :
export JAVA_HOME=/opt/softwares/jdk1.8.0_131
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=.:$JAVA_HOME/bin:$PATHsource /etc/profile // 使环境变量生效验证jdk是否安装完成 :
java -version // 会出现jdk版本信息
可利用scp命令发送jdk到其余虚拟机中然后更改/etc/profile
或是重复相同操作
hadoop的安装和配置
1.下载
访问hadoop官网下载。
2.解压
tar zxvf hadoop-3.0.0-alpha4.tar.gz3.为了方便可以配置一下环境变量
vi /etc/profileexport HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATHsource /etc/profile // 使环境变量生效验证安装 :
hadoop version
4.配置文件
在hadoop文件加下:
cd etc/hadoop/ // 此目录下含有hadoop的配置件
需要配置的文件有 :
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
workers
(单节点及伪分布式可查看官网)
vi hadoop-env.sh # The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/opt/softwares/jdk1.8.0_131因为hadoop是在JVM上运行的所以要在其配置文件中指定jdk的path
vi core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
第一个fs.defaultFS是指定hdfs的URI
第二个hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site.xml中不配 置namenode和datanode的存放位置,默认就放在这个路径中
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9001</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>
dfs.replication 副本个数,默认是3
dfs.namenode.secondary.http-address 为了保证整个集群的可靠性secondarnamenode配置在其他机器比较好
dfs.http.address 进入hadoop web UI的端口
vi mapred-site.xml <configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker.http.address</name>
<value>0.0.0.0:50030</value>
</property>
<property>
<name>mapred.task.tracker.http.address</name>
<value>0.0.0.0:50060</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>mapreduce框架的参数
最后一个是hadoop jar包的路径
vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> <name>yarn.resourcemanager.webapp.address</name>
<value>master:8099</value>
</property>
</configuration>
NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn 的webUI端口是8099
vi workers // datanode节点设置node1
node2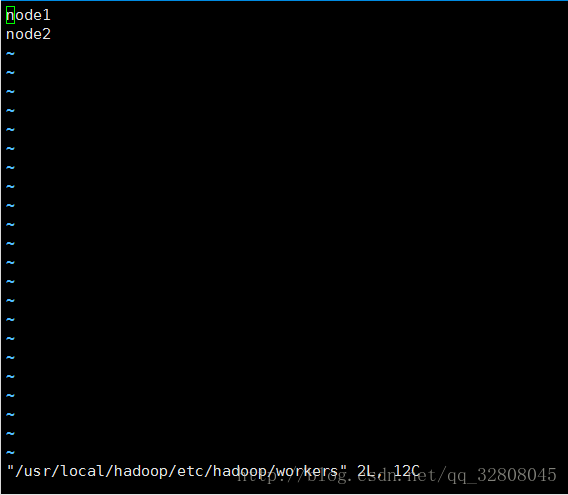
5.发送到其余虚拟机中或是重复相同操作
启动hadoop
hdfs namenode -format // 首次启动格式化namenode
start-all.sh // 启动hadoop集群
jps // 查看JVM运行的程序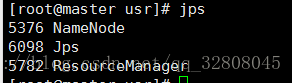
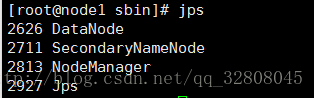
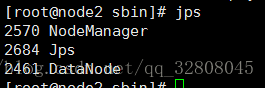
遇到的问题 :

在hadoop/sbin/
vi start-dfs.sh
vi stop-dfs.sh
添加
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
当报错YARN_RESOURCEMANAGER_USER时
vi start-yarn.sh
vi stop-yarn.sh
添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
50070端口配置文件中设置了,却还是不能访问
vi /etc/selinux/config
修改
#This file controls the state of SELinux on the system.
#SELINUX= can take one of these three values:
#enforcing - SELinux security policy is enforced.
#permissive - SELinux prints warnings instead of enforcing.
#disabled - No SELinux policy is loaded.
SELINUX=enforcingSELINUX的属性改为disabled
namenode启动了datanode没有启动(多次格式化namenode造成的)
在master的hadoop路径下 :
vi hdfs/name/current/VERSION拷贝clusterID
datanode的hadoop路径下 :
vi hdfs/data/current/VERSION替换掉datanode的clusterID
开启不需要format了
参考:
http://hadoop.apache.org/docs/r3.0.0-alpha4/hadoop-project-dist/hadoop-common/ClusterSetup.html
http://hadoop.apache.org/docs/r3.0.0-alpha4/hadoop-project-dist/hadoop-common/SingleCluster.html
推荐:http://blog.csdn.net/mxfeng/article/details/72770432?locationNum=15&fps=1















 2650
2650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









