







最近,由于导师要求,略微地了解了DQN,个人总结如下:
强化学习的关键要素:action,state,reward,environment,关于这些基础知识不再赘述了,我将从为什么会有DQN,DQN是怎么工作的,以及DQN的应用三个方面来写:
1、为什么会有DQN?
DQN是在Q-learning的基础之上改进的,由于Q-learning无法解决一些高维状态空间的问题,即Q-learning会导致Q表所占的空间很大,而且搜索速度会变慢,因此将Q-learning与强化学习相结合,用神经网络拟合Q值,会解决Q值矩阵过大的问题。
当环境中的状态数超过现代计算机容量时(Atari游戏有12833600个状态),标准的强化学习模式就不太有效了。
2、DQN是怎么工作的?
强化学习之DQN流程详解https://blog.csdn.net/Ivy_yijing1115/article/details/79857992
DQN思想:价值函数近似Value Function Approximation
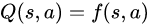
例:f为线性函数,都通过矩阵运算降维输出为单值的Q。
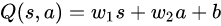
2.1DQN中的神经网络(两个结构相同,参数不同)
神经网络的可能是以下两种情况:
①input:action,state(1),……,state(n) output:n个Q值
②input:state(1),……,state(n) output:action的值
神经网络的更新是基于以下公式:
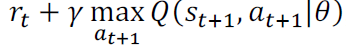
2.2DQN两项关键技术experience replay,fixed target q-network
经验回放(Experience replay)https://blog.csdn.net/suoyan1539/article/details/79571010
①experience replay:1)深度神经网络作为有监督学习模型,要求数据满足独立同分布,2)但 Q Learning 算法得到的样本前后是有关系的。为了打破数据之间的关联性,Experience Replay 方法通过存储-采样的方法将这个关联性打破了。
②fixed target q-network:Q值需要Q估计和Q现实两个估计值,那么这个策略就是在只有一个Q估计网络的情况下,复制一个结构完全一样的Q现实网络–而这个Q现实网络是每几个step才更新一次,更新的时候把Q估计当前的参数权值直接复制过来。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









