







上一篇文章《语音降噪模型归纳汇总》,很意外地收到了点赞收藏和关注,如此的反馈给了我极大的鼓舞,这里就再梳理了一下loss函数相关的知识,以求方便能作为一份工具性质的文章展现出来。能力一般,水平有限,欢迎大家指正。
干货分享:欢迎收藏点赞加关注
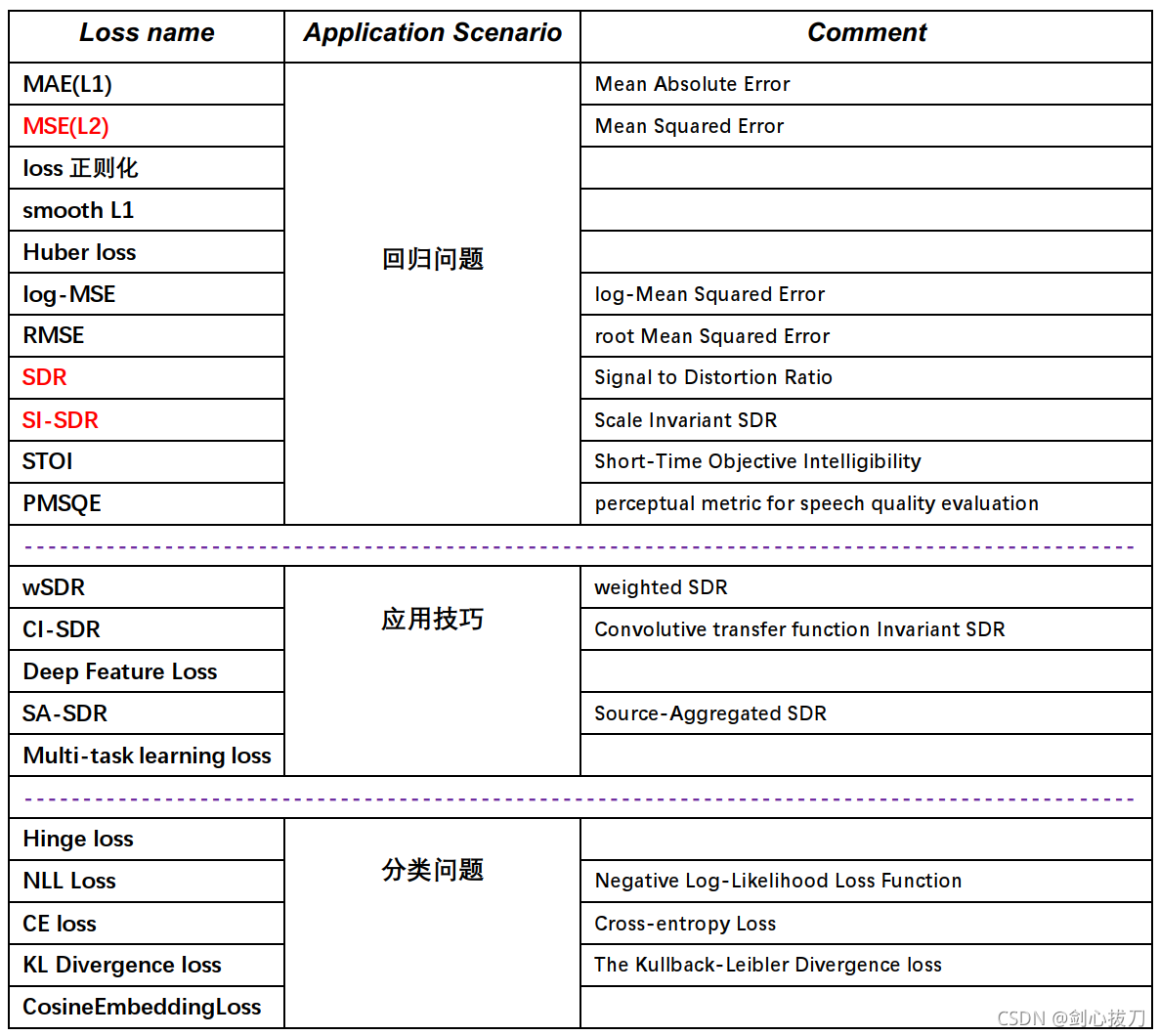
目录
前言
- 什么是损失(Loss)?
预测值(估计值)与实际值(预期值、参考值、ground truth)之间会存在差异, “损失”意味着模型因未能产生预期结果而受到的惩罚。 - 损失函数的作用?
损失函数将通过比较模型的预测输出和预期输出来确定模型的性能,进而寻找优化方向。如果二者之间的偏差非常大,则损失值会很大;如果偏差很小或值几乎相同,损失值会非常低。因此,需要使用合适的损失函数,当模型在数据集上进行训练时,该函数可以适当地惩罚模型。 - 根据应用场景,损失函数可以分为两个大类:回归问题 和 分类问题。
- 本文会着重渗透语音降噪方向的loss函数,基于torch。
一、回归问题 Loss
1、MAE Loss(L1 Loss)
平均绝对误差(MAE)损失,也称L1范数损失,计算实际值和预测值之间绝对差之和的平均值。

适用于回归问题,MAE loss对异常值更具鲁棒性,尤其是当目标变量的分布有离群值时(小值或大值与平均值相差很大)。
函数:torch.nn.L1Loss
2、MSE Loss(L2 Loss)
均方误差(MSE)损失,也称为L2范数损失,计算实际值和预测值之间平方差的平均值。
平方意味着较大的误差比较小的误差会产生更大的惩罚,所以MSE的收敛速度要比L1-loss要快得多。但是,L2 Loss对异常点更敏感,鲁棒性差于L1。
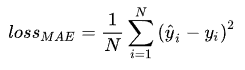
对于大多数回归问题,一般是使用MSE loss而不是L1-loss。
函数: torch.nn.MSELoss
3、loss正则化

-
正则化有防止过拟合的作用,为啥呢?
正则化之所以能够降低过拟合的原因在于,正则化是结构风险最小化的一种策略实现。给loss function加上正则化项,能使得新得到的优化目标函数h = f+normal,需要在f和normal中做一个权衡(trade-off),如果还像原来只优化f的情况下,那可能得到一组解比较复杂,使得正则项normal比较大,那么h就不是最优的,因此可以看出加正则项能让解更加简单,符合奥卡姆剃刀理论,同时也比较符合在偏差和方差(方差表示模型的复杂度)分析中,通过降低模型复杂度,得到更小的泛化误差,降低过拟合程度。L1正则化与L2正则化
注:dropout有防止过拟合的作用。 -
PyTorch实现: L2正则项是通过optimizer优化器的参数 weight_decay(float, optional) 添加的,用于设置权值衰减率,即正则化中的超参 \lambda ,默认值为0。
e.g. optimizer = torch.optim.SGD(model.parameters(),lr=0.01,weight_decay=0.01)
注:根据公式,添加正则化项,loss值会随着超参 \lambda 设定不同程度的变大,而实际pytorch实现过程中却并未出现如此现象,原因是loss在计算的时候没有把权重损失算进去。
4、Smooth L1 Loss
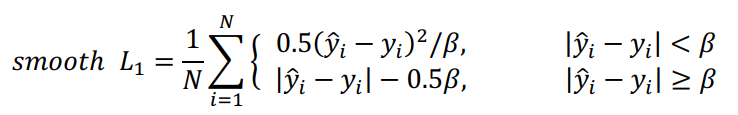
一般取 \beta=1 。smooth L1和L1-loss函数的区别在于, smooth L1在0点附近使用L2使得它更加平滑, 它同时拥有L2 Loss和L1 Loss的部分优点。
函数:torch.nn.SmoothL1Loss
5、Huber Loss
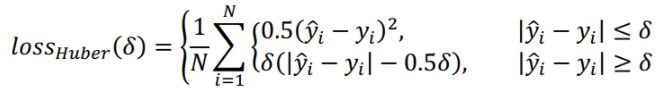
残差比较小时,此函数是二次函数;残差比较大时,此函数是线性函数。残差,即观测值和预测值之间的差值。与平方误差损失相比,Huber损失对数据中的异常值不那么敏感。使函数二次化的小误差值是多少取决于“超参数” \delta ,它可以调整。当 \delta=1 时,退化成SmoothL1Loss。
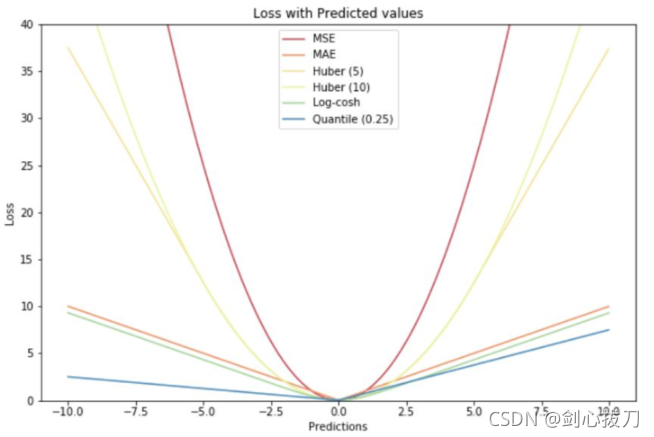
函数:torch.nn. HuberLoss
以下内容的更详细解析,请移步至传送门 模型训练——Loss函数
6、Log-MSE Loss
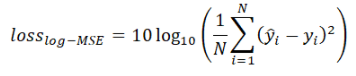
7、RMSE Loss
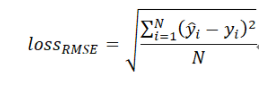
8、SDR Loss
SDR loss在很多论文中也称作SNR loss。
物理意义和解析过程引自台湾省台湾大学李宏毅教授的教材,符号使用有些非常规,注意观察。
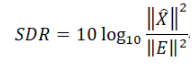
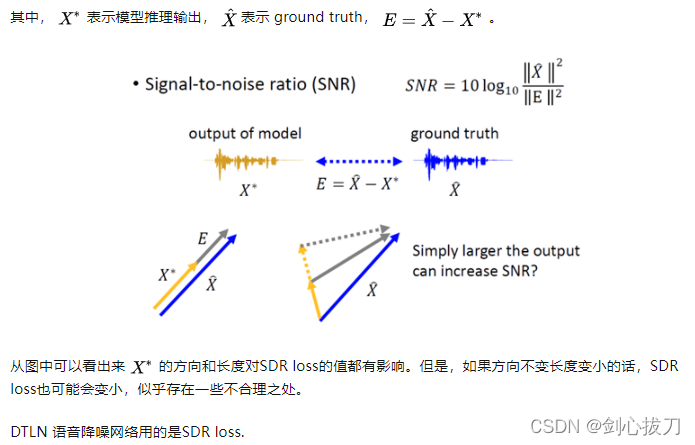
9、SI-SDR Loss

10、STOI Loss
公式原理参考论文:
《On Loss Functions for Supervised Monaural Time-Domain Speech Enhancement》
开源代码:
https://github.com/speechbrain/speechbrain/blob/develop/speechbrain/nnet/loss/stoi_loss.py
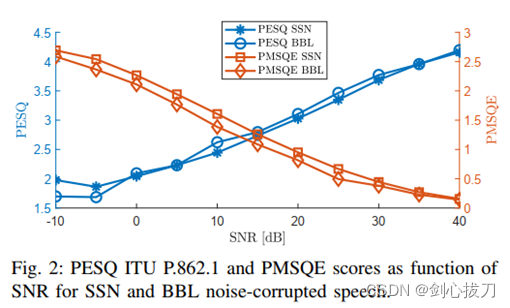
11、PMSQE Loss
对语音质量评估的主要metric,有PESQ(POLQA)、SDR、STOI等,为啥SDR和STOI都有对应的loss函数,PESQ没有呢 ?
因为成为loss函数的前提是算法可微可导,PESQ算法本身不具备。
PMSQE损失函数是用于近似PESQ metric的一种语音质量算法。经过处理的语音信号的PESQ分数是1到4.5之间值,其中1表示质量极差,4.5表示完全没有失真。PMSQE loss函数的设计与PESQ成反比,低PMSQE值对应高PESQ值。PMSQE的定义范围为3到0,其中0相当于未失真信号,3相当于极低的质量。
参考论文
《On Loss Functions for Supervised Monaural Time-Domain Speech Enhancement》
开源代码:
http://sigmat.ugr.es/PMSQE/PMSQE.zip
二、技巧性应用 Loss
1、wSDR Loss

参考论文
《PHASE-AWARE SPEECH ENHANCEMENT WITH DEEP COMPLEX U-NET》
开源代码
https://github.com/chanil1218/DCUnet.pytorch/blob/master/train.py
2、CI-SDR Loss

公式没看懂,看懂的同学帮忙解释一下~
参考论文
《CONVOLUTIVE TRANSFER FUNCTION INVARIANT SDR TRAINING CRITERIA FOR MULTI-CHANNEL REVERBERANT SPEECH SEPARATION》
开源代码
https://github.com/fgnt/ci_sdr
3、Deep Feature Loss

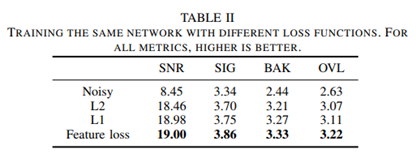
参考论文
《Speech Denoising with Deep Feature Losses》
开源代码
https://github.com/francoisgermain/SpeechDenoisingWithDeepFeatureLosses
4、SA-SDR Loss

参考论文
《SA-SDR: A NOVEL LOSS FUNCTION FOR SEPARATION OF MEETING STYLE DATA》
5、Multi-task learning loss

https://zhuanlan.zhihu.com/p/269492239
《Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics》. Alex Kendall, Yarin Gal, Roberto Cipolla. CVPR, 2018. (important)
基本思想是估计每个任务的不确定度,每个loss的加权与不确定度关联,如果不确定度大,自动把loss的权重减小。
《Bounding Box Regression with Uncertainty for Accurate Object Detection》. Yihui He, Chenchen Zhu, Jianren Wang, Marios Savvides, Xiangyu Zhang. CVPR, 2019.
以下内容的更详细解析整理在->传送门 模型训练——Loss函数
三、分类问题 Loss
1、Hinge Loss
2、NLL Loss
3、Cross Entropy Loss
4、KL Divergence Loss
5、CosineEmbeddingLoss
以上内容的更详细解析整理在->传送门 模型训练——Loss函数
参考文章
https://zhuanlan.zhihu.com/p/358570091
https://blog.csdn.net/zhangxb35/article/details/72464152
pytorch的官方loss函数实现解析链接:
https://pytorch.org/docs/stable/nn.html#loss-functions


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











