







一.摘要
1.出发点:(1)深度网络对对抗攻击(adversarial
attack)即对对抗样本的天生缺陷。
(2)当输入信息与自然样本差别并不大是却被网络错误的分类,如下图。


2.作者提出方法和论证如下:
(1)从鲁棒优化的角度研究了神经网络的抗差鲁棒性。这与很多最近的相关工作具有广泛的一致性 eg:防御蒸馏,特征压缩。
(2)根据方法的原理性使得该方法在普遍范围内是通用和有效的,即使用最强的一阶攻击,以防御几乎所有对手的攻击。
3.结果:
(1)这些方法训练我们的网络,极大地提高对几乎有所的对抗攻击的鲁棒性
(2)定义良好的对手类的是走向完全抵抗对抗攻击的深度学习模型的重要一步
二.Introduction
1.首先作者介绍了对抗攻击在很多领域聚有重要的意义,其中对抗攻击可以微调输入使得较好的分类模型产生不正确的输出。换句话说即使模型对良性的例子进行了正确的分类,这种微调变化对人类来说也是不可察觉的,但对深度模型来说是致命的。除了安全方面的影响外,这种现象还表明我们当前的模型没有以一种健壮的方式学习底层的概念。所有这些发现都提出了一个基本问题:
2.接着作者提出了相关工作(1)防御蒸馏 (2)特征压缩。
(1)生成对抗样本
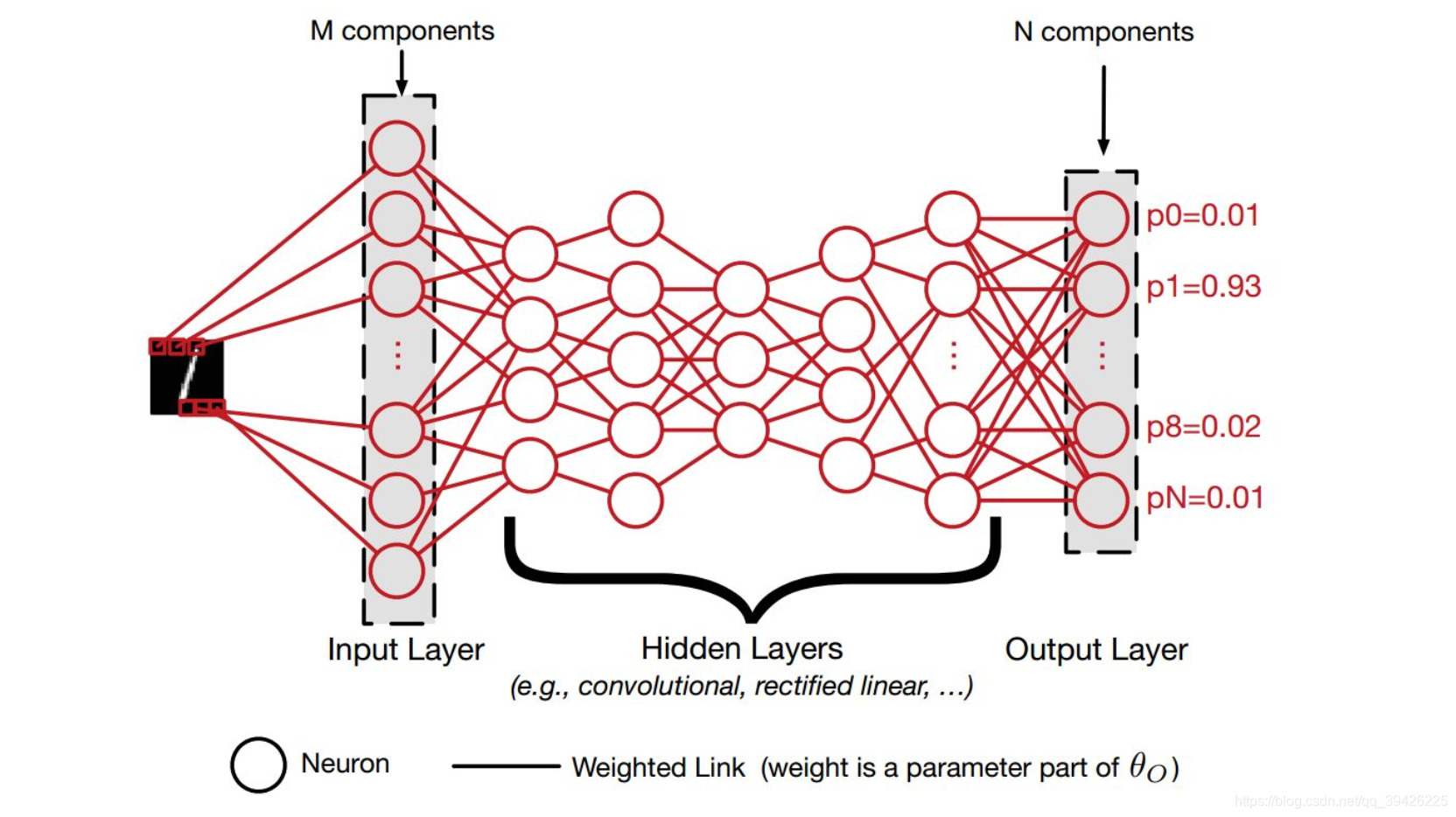
1)首先先给出DNN基本架构,下图表示了深度网络如何对输入信息进行分类的基本流程。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 224
224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









