







全文参考https://www.bilibili.com/video/av68735378?p=54
图像的读写
读
img = cv.imread( filepath, 1|0|-1)
- 参数1:
文件路径建议不包含中文,如果文件路径出现错误不会报错,但print(img)=none - 参数2:
cv.IMREAD_COLOR = 1:忽略图像透明度的彩色图像cv.IMREAD_GRAYSCALE = 0:灰度图像cv.IMREAD_UNCHANGED = -1:读入图像包括aplha通道(透明度)
查看img
type(img) = numpy.ndarray
img.shape = (w,h)
显示
cv.imshow( 窗口名称,图像变量)
可以通过设置不同的窗口名称新建多个窗口,一般用以下代码显示一张图片:
cv.namedWindow('img',cv.WINDOW_AUTOSIZE|CV.WINDOW_NORMAL) //autosize自动生成窗口大小不允许调整,normal允许手动调整窗口大小
cv.imshow('image',img)
cv.waitKey(0) //等待任意键按下后执行后续语句
cv.destroyAllWindows()
用matplotlib显示图片
因为cv.imread读入彩色图片的顺序是BGR,但matplotlib显示图片的顺序是RGB,所以二者需要转换:
imgRGB = cv.cvtColor(img, cv.COLOR_BGR2RGB)
plt.imshow(imgRGB)
plt.show()
写
cv.imwrite( filepath, 图像变量)
cv.waitKey(0) & 0xFF
一般需要从键盘中获取按下的某个键值时,可以使用如下语句:
k = cv.waitKey(0) & 0xFF //按位与操作,使得中英文输入法下的按键读入值都是同一个
print(k)
ord()
是一种获取字母unicode编码的方法,例如:
ord('a') = 97
ord('b') = 98 // ...以此类推
绘图
线段
确定起点和终点
import numpy as np
# 生成一张黑色的512*512,有3个通道的图
img = np.zeros((512,512,3),np.uint8)
# 画一条起点为(0,0),终点为(511,511),蓝色,粗细为5px的线段
cv.line(img, (0,0),(511,511),(255,0,0),5)
矩形
确定左上角和右下角
# 在img上画一个左上角坐标为(300,300),右下角坐标为(400,400),绿色,粗细为3px的矩形
cv.rectangle(img,(300,300),(400,400),(0,255,0),3)
圆
确定圆心和半径
# 在img上画一个圆心坐标为(300,300),半径为100,红色,粗细为10px的圆圈
cv.circle(img, (300,300), 100, (0,0,255), 10)
若粗细设为-1即表示填充
椭圆
确定椭圆中心,长短轴长度,椭圆延顺时针方向角度,椭圆弧面的起始和结束角度,是否填充
角度:水平轴为0度,角度按顺时针增加
# 在img上画一个中心坐标为(256,256),长短轴长度为(100,50),旋转角度0,0度起始180度结束,蓝色,填充的椭圆
cv.ellipse(img, (256,256),(100,50), 0, 0, 180, (255,0,0), -1)
多边形
确定顶点数量及坐标
# 生成一张512*512的黑色图
img = np.zeros((512,512,3),np.uint8)
# 确定一个顶点数组,类型为np.int32
pts = np.array([[100,100],[300,150],[400,400],[50,350]], np.int32)
# 根据顶点数组画出闭合的,黄色的,粗细为10的多边形
cv.polylines(img, [pts], True, (255,255,0), 10)
# 若以上这句的True改成False,将会得到不闭合的折线,最后两个顶点之间不连接
文字
确定文本、位置坐标、字体、大小、颜色、粗细、线条类型
font = cv.FONT_HERSHEY_SIMPLEX
# 在img上的(10,300)坐标处添加文本“opencv”,字体为font,4像素大小,颜色为白色,粗细为10px
cv.putText(img,"opencv", (10,300), font, 4, (255,255,255), 10)
查看opencv支持的字体:
import numpy as np
import cv2
import matplotlib as plt
# 图片大小
w = 800
h = 900
# 第一行字的坐标
w1 = 100
h1 = 50
# 生成一张800*800的黑图
img = np.zeros((h,w,3), np.uint8)
# 获取所有cv2字体
fonts = [i for i in dir(cv2) if 'FONT' in i]
for font in fonts:
# 经过排错,发现有三种cv2的字体在调C++函数时找不到
font = 'cv2.' + font
h1 = h1 + 50
try:
cv2.putText(img, font, (w1,h1), eval(font), 1, (255,255,255), 1)
except:
print(font+' is none')
cv2.putText(img, font +' is none', (w1,h1), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,0), 1)
continue
cv2.namedWindow('cvfont',cv2.WINDOW_NORMAL)
cv2.imshow('cvfont', img)
cv2.waitKey(0)
cv2.destroyAllWindows()

鼠标画图
鼠标双击画圆,其他鼠标事件类似:
import cv2 as cv
import numpy as np
# 定义鼠标操作函数
def draw_circle(event, x, y, flags, param):
if event == cv .EVENT_LBUTTONDBLCLK:
cv.circle(img, (x, y), 100, (255, 0, 0), -1)
# 创建黑色图像
img = np.zeros((512,512,3), np.uint8)
# 创建窗口
cv.namedWindow('image')
# 绑定窗口和事件函数
cv.setMouseCallback('image', draw_circle)
# 监听事件
while(1):
cv.imshow('image',img)
# 20秒后按下ESC关闭窗口
if cv.waitKey(20) & oxFF == 27:
break
cv.destroyAllWindows()
查看opencv支持的鼠标事件:
import cv2 as cv
enents = [i for i in dir(cv) if 'EVENT' in i]
print(events)
events
[‘EVENT_FLAG_ALTKEY’, ‘EVENT_FLAG_CTRLKEY’, ‘EVENT_FLAG_LBUTTON’, ‘EVENT_FLAG_MBUTTON’, ‘EVENT_FLAG_RBUTTON’, ‘EVENT_FLAG_SHIFTKEY’, ‘EVENT_LBUTTONDBLCLK’, ‘EVENT_LBUTTONDOWN’, ‘EVENT_LBUTTONUP’, ‘EVENT_MBUTTONDBLCLK’, ‘EVENT_MBUTTONDOWN’, ‘EVENT_MBUTTONUP’, ‘EVENT_MOUSEHWHEEL’, ‘EVENT_MOUSEMOVE’, ‘EVENT_MOUSEWHEEL’, ‘EVENT_RBUTTONDBLCLK’, ‘EVENT_RBUTTONDOWN’, ‘EVENT_RBUTTONUP’]
图像基本操作
访问像素
- 第一种方法
px = img[100,100]得到坐标为(100,100)处的[B G R]像素
blue|green|red = img[100,100,0|1|2]得到坐标为(100,100)处的B|G|R值 - 第二种方法
# 访问(100,100)处的B|G|R值
img.item(100,100,0|1|2)
# 设置像素值
img.itemset((100,100,0|1|2), 200)//把(100,100)处的B|G|R值设为200
访问图像属性
- img.shape = (height, width, channels)
- img.size = height*width
- img.dtype = uint8|…
ROI
切片操作例如img[50:100,100:200]
图像通道分割合并
分割:
- b, g, r = cv.split(img) //耗时,非必须不用
- b = img[:, :, 0] | g = img[:, :, 1] | r = img[:, :, 2]
合并:
img = cv.merge((b, g, r))
边框
imgwithborder = cv.copyMakeBorder(img, 10, 10, 10, 10, cv.BORDER_REPLICATE)
borders
[‘BORDER_CONSTANT’, ‘BORDER_DEFAULT’, ‘BORDER_ISOLATED’, ‘BORDER_REFLECT’, ‘BORDER_REFLECT101’, ‘BORDER_REFLECT_101’, ‘BORDER_REPLICATE’, ‘BORDER_TRANSPARENT’, ‘BORDER_WRAP’]
测试中发现加粗的两种可以正常显示纯色边框,其余的无变化
图像算术运算
加
通道不同的图像不能相加
# 定义x,y两个像素值
x = np.uint8([250])
y = np.uint8([10])
# 不会溢出 :等于最大值
cv.add() = [[255]]
# 会溢出:结果等于260对2的8次方取余
x + y = [4]
融合
可以实现一张图片向另一张图片渐变的效果
cv.addWeighted(img1, 0.9, img2, 0.1, 偏差,输出目标)
偏差一般为0,输出目标可省略
按位运算
# 与
cv.bitwise_and(src1, src2, dst, mask)
# 反
cv.bitwise_not(src1, src2, dst, mask)
# 或
cv.bitwise_or(src1, src2, dst, mask)
# 异或
cv.bitwise_xor(src1, src2, dst, mask)
阈值
ret, mask = cv.threshold(img, threshold=20, maxval=200, cv.THRESH_BINARY)
# ret = threshold
# mask = 大于阈值的像素都赋值为maxval
抠图:如何实现一个不透明LOGO跟一张大图的融合
步骤
- 原图
- LOGO小图
- 切片处理原图中的ROI即打算跟LOGO融合的位置
- LOGO小图灰度化,将LOGO和底色区分开
- LOGO小图用阈值函数变成黑白图——mask
- LOGO小图进行反色操作——mask_inverse
- 原图的ROI自己跟自己按位与,mask用mask_inverse,即原图ROI中的LOGO位置变成了0
- 小图自己按位与,mask用5.中的mask,使除了LOGO的背景都为0,此时小图和原图的ROI区域形成了凹凸关系
- 用cv.add将小图和原图ROI相加即可,再将得到的结果赋值到原图上
关于运算速度
- 当数组比较小的时候,直接用python最快;反之numpy更快
- 同样的操作,opencv比numpy快
色彩空间
转换
cv.cvtColor(input_image, flag)
常用flag:
- cv.COLOR_BGR2GRAY
- cv.COLOR_BGR2HSV
色彩模式
- BGR
蓝绿红,取值范围[0, 255],由浅到深 - HSV
色调H:[0,179]
饱和度S:[0,255]
亮度V:[0,255]
利用HSV进行目标检测
因为HSV的三个参数可以将图片中的不同目标区分出来,因此可以进行目标检测(抠图)
- 确定目标的HSV阈值范围lower_blue = np.array([0, 0, 81]),upper_blue = np.array([115,255,255])
- 利用阈值获取mask = cv.inRange(img_hsv, lower_blue, upper_blue)
- 显示mask即可看到需要的部分为白色,不需要的部分为黑色
- 将mask和原图按位与得到res = cv.bitwise_and(img, img, mask = mask)
怎么确定第一步中的阈值范围
做一个滑块函数观察目标图片
滑块函数的思路:
# init
hsv_low = np.array([0, 0, 0])
hsv_high = np.array([0, 0, 0])
# define function to get value
def h_low(value):
hsv_low[0] = value
......
# creat Trackbar
cv.namedWindow('img')
cv.createTrackbar('H low', 'image', 0, 180, h_low)
......
# display
while True:
dst = cv.cvtColor(img, cv.COLOR_BGR2HSV)
dst = cv.inRange(dst, hsv_low, hsv_high)
cv.imshow('dst', dst)
if cv.waitKey(1) & 0xFF == ord('q'):
break
cv.destroyAllWindows()
图片几何变换
缩放
dst = cv.resize(src,(width, height)|fx,fy, interpolation = cv.INTER_CUBIC)
缩放大小由自定义大小或者设置fx,fy决定
平移
dst = cv.wrapAffine(src, M, (cols,rows))
M是2*3矩阵,表示(a1x+b1y+c1,a2x+b2y+c2)
旋转
确定坐标系和旋转方向:
左上角原点,逆时针旋转

按(x0,y0)为旋转中心旋转,则可以看作先绕原点旋转,再按(x0,y0)不变将像素全部平移回来,可以等同于按下图矩阵计算

加尺度

仿射变换
三点确定一个变换矩阵

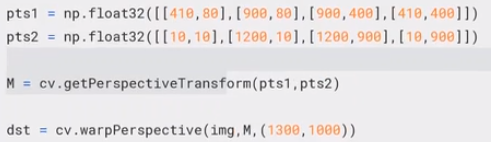
透视变换
缩放加平移的效果
四点确定变换,其中至少三个点不共线
阈值处理
简单阈值
retval, dst = cv.threshold(src, thresh, maxval, type)
retval = thresh
dst = 处理后的图片
几种阈值处理方式(type)

自适应阈值
dst = cv.adaptiveThreshold(img, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY,11,2)
11指邻域尺寸,一般为3,5,7,11
2指算出来值后-2
cv.ADAPTIVE_THRESH_MEAN_C意思是说邻域中所有值权重一样
cv.ADAPTIVE_THRESH_GAUSSIAN_C意思是说邻域权重设置高斯分布
Ostu阈值
例如在双峰直方图中选择一个阈值,使得被这个阈值分开的两个部分的灰度方差最小
算法原理:按直方图从左到右穷举选择阈值点,计算求出最小的方差,计算方差时每个灰度值有权重(将直方图面积看作1,两部分各自有权重)

图片平滑处理(滤波)
均值滤波
在像素点周围框一个框,使得原始像素点变为整个框的平均值
dst = cv.blur(img, (3, 3)) # 选择3*3的框
高斯滤波
在像素点周围框一个框,根据二维高斯分布对像素分配权重计算加权值(离该像素越近权重越高)
内核大小长宽可以不同,但需要是正奇数
dst = cv.GaussianBlur(img,(5,5),0) # 5*5的高斯框,sigma设为0
中值滤波
选择像素点框里的中值作为代替中心元素的像素值,框为正奇数的正方形
dst = cv.medianBlur(img,5)#5*5的框
双边滤波
综合考虑空间信息和色彩信息,空间指的是和高斯滤波相同的坐标距离越远权重越小,色彩指的是色彩差别越大权重越小(保护了边缘信息)
dst = cv.bilateralFilter(img,9,75,75) #框大小为9*9,空间和色彩的sigma参数为75
参考https://blog.csdn.net/duwangthefirst/article/details/79971369
关于2个sigma参数:
简单起见,可以令2个sigma的值相等;
如果他们很小(小于10),那么滤波器几乎没有什么效果;
如果他们很大(大于150),那么滤波器的效果会很强,使图像显得非常卡通化;
关于参数d:
过大的滤波器(d>5)执行效率低。
对于实时应用,建议取d=5;
对于需要过滤严重噪声的离线应用,可取d=9;
d>0时,由d指定邻域直径;
d<=0时,d会自动由sigmaSpace的值确定,且d与sigmaSpace成正比
2D卷积
dsit = cv.filter2D(img,ddepth,kernel,anchor,delta,borderType)
ddepth:期望输出的图像深度,设为1则代表前后深度一致
kernel:自定义的核
anchor:默认值(-1,-1)代表未过滤的像素点位于核中心
delta:滤波后的图片可以统一加上delta值
borderType:边界填充方法(默认镜像扩充)
形态学操作
提取图像最基本的形状,例如手写数字识别中的骨架提取
腐蚀
使图片中的形状越来越细直到完全被周围的背景像素腐蚀,原理就是判断整个核全在形状中时,令中心值为原值,否则为背景值
erosion = cv.erode(img, kernel, iteration=1)
同样也有borderType、anchor等参数,和滤波类似
膨胀
与腐蚀正好相反,只要核有任意一点在前景中,中心值就设为前景值,否则为背景值
dilation = cv.dilate(img,kernel,iteration=1)
通用形态学函数
dst = cv.morphologyEx(img,op,kernel)
op表示形态学操作
(以下图片中不和谐的鼠标均为截图时不小心留下的)
| op | 名称 | 变化前 | 变化后 |
|---|---|---|---|
| cv.MORPH_OPEN | 开运算:先腐蚀再膨胀 |  |  |
| cv.MORPH_CLOSE | 闭运算:先膨胀再腐蚀 |  | |
| cv.MORPH_GRADIENT | 梯度运算:膨胀-腐蚀 |  |  |
| cv.MORPH_TOPHAT | 礼帽运算:原始-开 |  |  |
| cv.MORPH_BLACKHAT | 黑帽运算:闭-原始 |  |  |
核函数
kernel = cv.getStructuringElement(shape,(5,5))
| shape | 名称 | kernel |
|---|---|---|
| cv.MORPH_RECT | 正方形 |  |
| cv.MORPH_CROSS | 十字形 |  |
| cv.MORPH_ELLIPSE | 椭圆形 |  |
Canny边缘检测
理论
通过计算像素之间的梯度来检测边缘
- 滤波降噪
- 计算梯度:对平滑后的图像进行水平和垂直方向的sobel滤波得到两个方向的一阶导数,从而计算出每个像素的边缘梯度
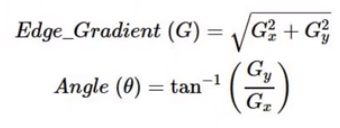
- 非极大值抑制:判断在每个像素处,该像素是否为其领域内的局部最大值,是则进入下一步,否则被抑制
- 双阈值处理:

纵坐标是梯度值,横坐标是
A、B、C分别是上一步筛选后的像素构成的线,在maxVal以上的像素可以确定是边缘,在minVal以下的像素一定不是边缘,在maxVal和minVal中间有两种:C与A(肯定是边缘)相连,B完全属于中间,则把C判定为边缘,B判定为非边缘
代码
edges = cv.Canny(img,threshold1,threshold2)

图像金字塔

高斯金字塔
pyrDown
原理:先用一个高斯核与图像进行2d卷积,然后去除掉偶数行和偶数列
r0 = cv.pyrDown(img)
r1 = cv.pyrDown(r0)
r2 = cv.pyrDown(r1)
r3 = cv.pyrDown(r2)

pyrUp
原理:在每个像素的右侧和下方分别插入零行和零列,再用之前向下采样时的高斯核(由于面积扩大为原来的四倍,均值降为了1/4,所以这里的高斯核需要再乘以4)进行滤波
r0 = cv.pyrUp(img)
r1 = cv.pyrUp(r0)
r2 = cv.pyrUp(r1)
r3 = cv.pyrUp(r2)

采样可逆性
先下采样再上采样后图像是完全一样的吗?
不一样!看起来相似,但每个像素值不完全相同

拉普拉斯金字塔
用于图像压缩,是高斯金字塔上采样和下采样之间的差值


利用图像金字塔进行图像融合
- 具有在下采样和上采样的过程中能够保持大小相同的两张图片AB

- 分别生成AB图像的高斯金字塔(6层)


- 分别生成AB图像的拉普拉斯金字塔
cv.substract(上采样图,下采样图)


- 将第3步中的AB图像金字塔分别取一半拼接在一起
ls=np.hstack((la[:, 0:int(cols/2)], lb[:, int(cols/2):0]))

- 根据第4步中的图片重建
cv.add(上一层高斯加0, 差值)

图像轮廓
与边缘检测相比,图像轮廓可以将检测出的边缘连接起来形成一个整体
找轮廓
contours, hierarchy = cv.findContours(img, mode, method)
- contours:返回的图像轮廓
[[轮廓1(若干点[x, y]组成的list)], [轮廓2], [轮廓3]....., [轮廓n]] - hierarchy:图像轮廓的包含层次信息
[ [ [轮廓1(后一个轮廓的索引,前一个轮廓的索引,第一个子轮廓的索引,父轮廓的索引(缺少索引则置-1)], [轮廓2],[轮廓3],....,[ 轮廓n] ] ] - 0,1,2
- 2a,3(2为父轮廓)
- 3a,4,5(3为父轮廓)

- img:原始图像处理后的8位单通道的二值图像
- mode:轮廓检索模式(cv.RETR_TREE(建立树结构)、cv.RETR_EXTERNAL(只检测外轮廓)、cv.RETR_LIST(不建立等级关系)、cv.RETR_CCOMP(只建立两级层次结构))
- method:轮廓的近似方法,默认cv.CHAIN_APPROX_SIMPLE
画轮廓
img = cv.drawContours(img, contours, contourIdx, color, thickness, lineType, hierarchy, maxLevel)
- img:若不想直接作用在当前图片需提前copy一份
- contours:轮廓List
- contourIdx:边缘索引,-1表示绘制全部轮廓
- color
- thickness:-1表示绘制实心轮廓
- lineType:线形
- hierarchy:层次信息
- maxLevel:轮廓层次深度
图像梯度Sobel算子检测边缘
理论
Sobel算子结合了高斯平滑和微分求导运算,是一种离散的微分算子
代码
- dst = cv.Sobel(img, ddepth, dx, dy, ksize, scale, delta, borderType)
- ddepth:输出图像深度(cv.CV_8U(负值为被置为0)、cv.CV_64F
- dx:x方向求导,用1、0表示开关
- dy:y方向求导,用1、0表示开关
- ksize:默认为3,可取1、3、5、7,越大检测到的边缘越粗
convertabs(cv.Sobel(img,cv.CV_64F,dx,dy,ksize=5))
SobelX+Y = cv.addWeighted(sobelx,0.5,sobely,0.5,1)

Scharr算子:与Sobel算子仅核的权重不同
Scharr边缘检测效果更强但噪声也更多

Laplacian算子
laplacian = cv.Lapplacian(img, cv.CV_64F)

算子小结
- Sobel:一阶导数近似值
- Scharr:一阶导数近似值
- Laplacian:二阶导数近似值
图像轮廓特征:面积、周长、质心、边界
原理
-空间矩: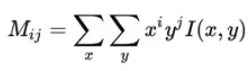
- 质量:图像非零元素的个数
- 质心:
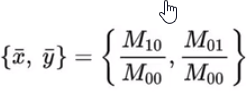
- 平移不变性
- 尺度不变性
- 旋转不变性
图像矩运算
cnt = contours[0] # 取某一个轮廓
M = cv.moments(cnt) # 包含各种矩M的字典
质心
cx = int(M[‘m10’]/M[‘m00’])
cy = int(M[‘m01’]/M[‘m00’])
ctd = np.array([[[cx, cy]]]) # 存成一个坐标点,用于后续画轮廓和质心
面积
area = cv.contourAera(cnt)
通过Hu矩验证旋转不变性来判断两个对象的一致性
retval = cv.matchShapes(contour1, contour2,1, 0, 0)
retval是一个float值,越接近0说明越一致
图像轮廓拟合
多边形拟合
Douglas-Peucker算法:先找轮廓上距离最远的两点练成直线,再找轮廓上距离该直线最远的点练成三角形,接着将新找到的距离当前多边形最远的点加入,循环该过程直到新的点距离当前多边形距离低于设定的精度
approxCurve = cv.approxPolyDP(curve, epsilon, closed)
curve:原始轮廓
epsilon:精度,通常设置为多边形总长度的百分比形式(eg.0.2*cv.arcLength(cnt,True))越小越接近原轮廓形状
closed:曲线是否闭合
凸包拟合
- 选中一条轮廓

hull = cv.convexHull(cnt)

检测凸包:任意两点在该轮廓内
cv.isContourConvex(hull)——True
cv.isContourConvex(cnt)——False
Solidity:轮廓面积与其凸包面积之比
hull_area = cv.contourArea(hull)
area = cv.contourArea(cnt)
solidity = float(area)/hull_area
矩形包围框拟合
x,y,w,h = cv.boundingRect(cnt)
x,y是左上角坐标,w,h分别代表宽和高

宽高比
aspect_ratio = float(w)/h
Extent:轮廓面积/边界矩形面积
area = cv.contourArea(cnt)
rect_area = w*h
extent = float(area)/rect_area
旋转包围框拟合:最小面积的矩形
rect = cv.minAreaRect(cnt)
box = cv.boxPoints(rect)

圆形包围框拟合
(x,y),radius = cv.minEnclosingCircle(cnt)
center = (int(x),int(y)) #这里转换成Int型是为了满足画轮廓、圆之类的参数要求
radius = int(radius)

最优拟合椭圆
ellipse = cv.fitEllipse(cnt) # ellipse = (x,y),(MA,ma),angle
img_elps = cv.ellipse(img, ellipse, (255,0,0), 5) #可以直接画

最优直线拟合
[vx, vy, x, y] = cv.fitLine(cnt, cv.DIST_L2, 0, 0.01, 0.01)
vx和vy分别是以原点为中心的两条射线的端点,代表直线方向
x,y是直线中心点坐标,根据这四个值可以算出直线的两个端点坐标值如下

轮廓特征值:轮廓像素点坐标、max/min、mean、极点
numpy获取像素点
numpy.nonzero(img)返回两个array,分别存了x坐标和y坐标
接着用numpy.transpose(numpy.nonzero(img))转换成一个由[x,y]坐标组成的二维array([[x,y],[x,y],…])
OpenCV获取像素点
cv.findNonZero(img)返回结果如上
可以获取轮廓长度进行排序获得最长的轮廓
最大值和最小值
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(imgray, mask = mask)
val=值
loc=坐标(x,y)
imray=单通道灰度图
mask=指定区域
平均颜色和平均灰度
mean_val = cv.mean(img, mask = mask)
彩色图返回(B,G,R,Alpha)
轮廓的极点(左右上下)
leftmost = tuple(cnt[cnt[:,:,0].argmin()][0])
rightmost = tuple(cnt[cnt[:,:,0].argmax()][0])
topmost = tuple(cnt[cnt[:,:,1].argmin()][0])
bottommost = tuple(cnt[cnt[:,:,1].argmax()][0])

















 1954
1954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









