







探索String、StringBuilder以及StringBuffer
String
string源码剖析
String类的实现是在 \jdk1.8.0_131\src\java\lang\String.java 文件中。
打开这个类文件就会发现String类是被final修饰的:
在 Java 8 中,String 内部使用 char 数组存储数据
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
......在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final byte[] value;
/** The identifier of the encoding used to encode the bytes in {@code value}. */
private final byte coder;
}(暂时不考虑java9版本的情况)
从上面可以看到几点:
- String类是final类,也就是说意味着,不能被继承,并且它的成员方法都默认为final方法。在Java中,被final修饰的类是不允许被继承的,并且该类中的成员方法都默认为final方法。在早期的JVM实现版本中,被final修饰的方法会被转为内嵌调用以提升执行效率。而从Java SE5/6开始,就渐渐摈弃这种方式了。因此在现在的Java SE版本中,不需要考虑用final去提升方法调用效率。只有在确定不想让该方法被覆盖时,才将方法设置为final。
- 上面列举出了String类中所有的成员属性,从上面可以看出String类其实是通过char数组来保存字符串的。
- value 数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
- 可以缓存hash值,因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算
为什么String需要保证不可变?
不可变的好处:
- 可以缓存hash值,因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算
- String Pool需要,如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
安全性。String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 的那一方以为现在连接的是其它主机,而实际情况却不一定是。
线程安全。String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
substring的实现:
public String substring(int beginIndex, int endIndex) {
if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
if (endIndex > value.length) {
throw new StringIndexOutOfBoundsException(endIndex);
}
int subLen = endIndex - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return ((beginIndex == 0) && (endIndex == value.length)) ? this
: new String(value, beginIndex, subLen);
}concat的实现
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
replace的实现
public String replace(char oldChar, char newChar) {
if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
if (i < len) {
char buf[] = new char[len];
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}从上面的三个方法可以看出,无论是substring、concat还是replace操作都不是在原有的字符串上进行的,而是重新生成了一个新的字符串对象。也就是说进行这些操作后,最原始的字符串并没有被改变。
在这里要永远记住一点:
“对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象”。
StringBuilder
源码剖析
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/** use serialVersionUID for interoperability */
static final long serialVersionUID = 4383685877147921099L;
/**
* Constructs a string builder with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuilder() {
super(16);
}
/**
* Constructs a string builder with no characters in it and an
* initial capacity specified by the {@code capacity} argument.
*
* @param capacity the initial capacity.
* @throws NegativeArraySizeException if the {@code capacity}
* argument is less than {@code 0}.
*/
public StringBuilder(int capacity) {
super(capacity);
}
/**
* Constructs a string builder initialized to the contents of the
* specified string. The initial capacity of the string builder is
* {@code 16} plus the length of the string argument.
*
* @param str the initial contents of the buffer.
*/
public StringBuilder(String str) {
super(str.length() + 16);
append(str);
}
.......可以看到,与String不同。
String没有继承其他类,但是StringBuilder继承了AbstractStringBuilder类
在StringBuilder中几乎没有定义成员属性,是通过继承父类,来封装的
父类源码
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
/**
* The count is the number of characters used.
*/
int count;
/**
* This no-arg constructor is necessary for serialization of subclasses.
*/
AbstractStringBuilder() {
}
/**
* Creates an AbstractStringBuilder of the specified capacity.
*/
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
......由上可以看到,
StringBuilder类通过继承父类,也封装了一个字符数组,定义如下:
char[] value;
与String不同,它不是final的,可以修改。另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:
int count;
StringBuilder继承自AbstractStringBuilder,它的默认构造方法是:
public StringBuilder() {
super(16);
}
调用父类的构造方法,父类对应的构造方法是:
AbstractStringBuilder(int capacity) {
value = new char[capacity];
}
也就是说,new StringBuilder()这句代码,内部会创建一个长度为16的字符数组,count的默认值为0。
append的实现
public AbstractStringBuilder append(String str) {
if (str == null) str = "null";
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}
append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展,实际使用的长度用count体现。具体来说,ensureCapacityInternal(count+len)会确保数组的长度足以容纳新添加的字符,str.getChars会拷贝新添加的字符到字符数组中,count+=len会增加实际使用的长度。
ensureCapacityInternal的代码如下:
private void ensureCapacityInternal(int minimumCapacity) {
if (minimumCapacity - value.length > 0)
expandCapacity(minimumCapacity);
}
如果字符数组的长度小于需要的长度,则调用expandCapacity进行扩展,expandCapacity的代码是:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0)
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
扩展的逻辑是,分配一个足够长度的新数组,然后将原内容拷贝到这个新数组中,最后让内部的字符数组指向这个新数组,这个逻辑主要靠下面这句代码实现:
value = Arrays.copyOf(value, newCapacity);
toString实现
字符串构建完后,我们来看toString代码:
public String toString() {
return new String(value, 0, count);
}StringBuffer
StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/
private transient char[] toStringCache;
/** use serialVersionUID from JDK 1.0.2 for interoperability */
static final long serialVersionUID = 3388685877147921107L;
/**
* Constructs a string buffer with no characters in it and an
* initial capacity of 16 characters.
*/
public StringBuffer() {
super(16);
}
/**
* Constructs a string buffer with no characters in it and
* the specified initial capacity.
*
* @param capacity the initial capacity.
* @exception NegativeArraySizeException if the {@code capacity}
* argument is less than {@code 0}.
*/
public StringBuffer(int capacity) {
super(capacity);
}
/**
* Constructs a string buffer initialized to the contents of the
* specified string. The initial capacity of the string buffer is
* {@code 16} plus the length of the string argument.
*
* @param str the initial contents of the buffer.
*/
public StringBuffer(String str) {
super(str.length() + 16);
append(str);
}
/**
* Constructs a string buffer that contains the same characters
* as the specified {@code CharSequence}. The initial capacity of
* the string buffer is {@code 16} plus the length of the
* {@code CharSequence} argument.
* <p>
* If the length of the specified {@code CharSequence} is
* less than or equal to zero, then an empty buffer of capacity
* {@code 16} is returned.
*
* @param seq the sequence to copy.
* @since 1.5
*/
public StringBuffer(CharSequence seq) {
this(seq.length() + 16);
append(seq);
}
@Override
public synchronized int length() {
return count;
}
@Override
public synchronized int capacity() {
return value.length;
}
........同样都是继承的AbstractStringBuilder父类
StringBuilder的insert方法
@Override
public StringBuilder insert(int index, char[] str, int offset,
int len)
{
super.insert(index, str, offset, len);
return this;
}StringBuffer的insert方法:
@Override
public synchronized StringBuffer insert(int index, char[] str, int offset,
int len)
{
toStringCache = null;
super.insert(index, str, offset, len);
return this;
}只是StringBuffer中的成员方法添加了synchronized关键字,用来保证线程安全
深入理解String,StringBuffer,StringBuilder
1、String str="hello world"和String str=new String("hello world")的区别
public class Main {
public static void main(String[] args) {
String str1 = "hello world";
String str2 = new String("hello world");
String str3 = "hello world";
String str4 = new String("hello world");
System.out.println(str1==str2);
System.out.println(str1==str3);
System.out.println(str2==str4);
}
}输出结果为:

为什么会出现这样的情况呢?
因为在class文件中有一部分 来存储编译期间生成的 字面常量以及符号引用,这部分叫做class文件常量池,在运行期间对应着方法区的运行时常量池。
因此在上述代码中,str1,str2,str3 ,str4都在编译期间生成了字面常量和符号引用,运行期间字面常量 "hello world" 被存储在方法区中的常量池(只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。
str1 和 str3 储存的都是 "hello world" 在常量池中的地址,str2 和 str4 中储存的是堆区中的对象的地址,而对象储存的是常量池中的地址。
总所周知,通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。因此通过new来创建对象,创建出的一定是不同的对象,即使字符串的内容是相同的。
2、String Pool
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;
否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 和 s2.intern() 方法取得同一个字符串引用。intern() 首先把 "aaa" 放到 String Pool 中,然后返回这个字符串引用,因此 s3 和 s4 引用的是同一个字符串。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s3 == s4); // true
如果是采用 "bbb" 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
String s5 = "bbb";
String s6 = "bbb";
System.out.println(s5 == s6); // true
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
3、new String("abc")
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
- "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
- 而使用 new 的方式会在堆中创建一个字符串对象。
创建一个测试类,其 main 方法中使用这种方式来创建字符串对象。
public class NewStringTest {
public static void main(String[] args) {
String s = new String("abc");
}
}
使用 javap -verbose 进行反编译,得到以下内容:
// ...
Constant pool:
// ...
#2 = Class #18 // java/lang/String
#3 = String #19 // abc
// ...
#18 = Utf8 java/lang/String
#19 = Utf8 abc
// ...
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=3, locals=2, args_size=1
0: new #2 // class java/lang/String
3: dup
4: ldc #3 // String abc
6: invokespecial #4 // Method java/lang/String."<init>":(Ljava/lang/String;)V
9: astore_1
// ...
在 Constant Pool 中,#19 存储这字符串字面量 "abc",#3 是 String Pool 的字符串对象,它指向 #19 这个字符串字面量。在 main 方法中,0: 行使用 new #2 在堆中创建一个字符串对象,并且使用 ldc #3 将 String Pool 中的字符串对象作为 String 构造函数的参数。
以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}4、String、StringBuffer以及StringBuilder的区别
既然在Java中已经存在了String类,那为什么还需要StringBuilder和StringBuffer类呢?
看这段代码
public class Main {
public static void main(String[] args) {
String string = "";
for(int i=0;i<10000;i++){
string += "hello";
}
}
}这段代码中
这句 string += "hello";的过程相当于将原有的string变量指向的对象内容取出与"hello"作字符串相加操作再存进另一个新的String对象当中,再让string变量指向新生成的对象。
反编译其字节码文件:

从这段反编译出的字节码文件可以很清楚地看出:
从第8行开始到第35行是整个循环的执行过程,并且每次循环会new出一个StringBuilder对象,然后进行append操作,最后通过toString方法返回String对象。也就是说这个循环执行完毕new出了10000个对象。
试想一下,如果这些对象没有被回收,会造成多大的内存资源浪费。从上面还可以看出:string+="hello"的操作事实上会自动被JVM优化成:
StringBuilder str = new StringBuilder(string);
str.append("hello");
str.toString();频繁的对String对象进行修改,会造成很大的内存开销。此时应该用StringBuffer或StringBuilder来代替String。
而new String()更加不适合,因为每一次创建对象都会调用构造器在堆中产生新的对象,性能低下且内存更加浪费。
再看下面这段代码
public class Main {
public static void main(String[] args) {
StringBuilder stringBuilder = new StringBuilder();
for(int i=0;i<10000;i++){
stringBuilder.append("hello");
}
}
}反编译字节码文件得到:
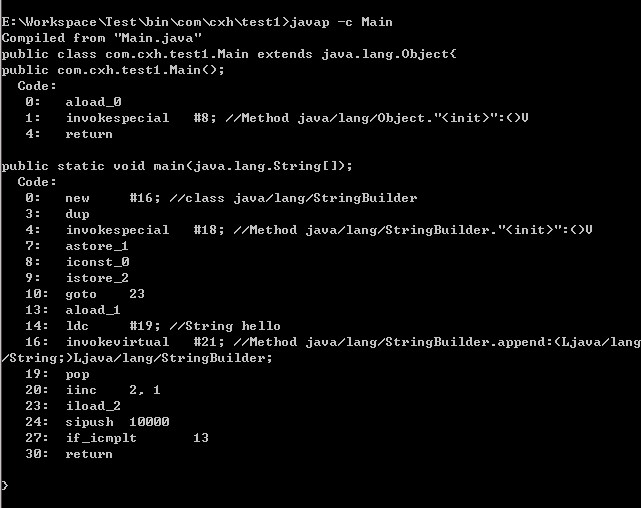
从这里可以明显看出,这段代码的for循环式从13行开始到27行结束,并且new操作只进行了一次,也就是说只生成了一个对象,append操作是在原有对象的基础上进行的。因此在循环了10000次之后,这段代码所占的资源要比上面小得多。
那么有人会问既然有了StringBuilder类,为什么还需要StringBuffer类?
查看源代码便一目了然,事实上,StringBuilder和StringBuffer类拥有的成员属性以及成员方法基本相同,区别是StringBuffer类的成员方法前面多了一个关键字:synchronized,不用多说,这个关键字是在多线程访问时起到安全保护作用的,也就是说StringBuffer是线程安全的。
性能测试
上才艺~~
public class Main {
private static int time = 50000;
public static void main(String[] args) {
testString();
testStringBuffer();
testStringBuilder();
test1String();
test2String();
}
public static void testString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
s += "java";
}
long over = System.currentTimeMillis();
System.out.println("操作"+s.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testStringBuffer () {
StringBuffer sb = new StringBuffer();
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
sb.append("java");
}
long over = System.currentTimeMillis();
System.out.println("操作"+sb.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testStringBuilder () {
StringBuilder sb = new StringBuilder();
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
sb.append("java");
}
long over = System.currentTimeMillis();
System.out.println("操作"+sb.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void test1String () {
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
String s = "I"+"love"+"java";
}
long over = System.currentTimeMillis();
System.out.println("字符串直接相加操作:"+(over-begin)+"毫秒");
}
public static void test2String () {
String s1 ="I";
String s2 = "love";
String s3 = "java";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
String s = s1+s2+s3;
}
long over = System.currentTimeMillis();
System.out.println("字符串间接相加操作:"+(over-begin)+"毫秒");
}
}执行结果

上面提到string+="hello"的操作事实上会自动被JVM优化,看下面这段代码:
public class Main {
private static int time = 50000;
public static void main(String[] args) {
testString();
testOptimalString();
}
public static void testString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
s += "java";
}
long over = System.currentTimeMillis();
System.out.println("操作"+s.getClass().getName()+"类型使用的时间为:"+(over-begin)+"毫秒");
}
public static void testOptimalString () {
String s="";
long begin = System.currentTimeMillis();
for(int i=0; i<time; i++){
StringBuilder sb = new StringBuilder(s);
sb.append("java");
s=sb.toString();
}
long over = System.currentTimeMillis();
System.out.println("模拟JVM优化操作的时间为:"+(over-begin)+"毫秒");
}
}
执行结果:
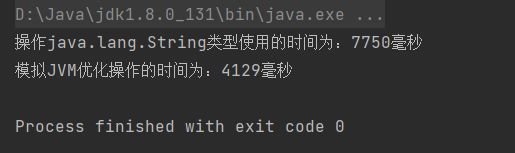
结论:
- 对于直接相加字符串,效率很高,因为在编译器便确定了它的值,也就是说形如"I"+"love"+"java"; 的字符串相加,在编译期间便被优化成了"Ilovejava"。这个可以用javap -c命令反编译生成的class文件进行验证。
对于间接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
- String、StringBuilder、StringBuffer三者的执行效率:StringBuilder > StringBuffer > String
当然这个是相对的,不一定在所有情况下都是这样。
比如String str = "hello"+ "world"的效率就比 StringBuilder st = new StringBuilder().append("hello").append("world")要高。
因此,这三个类是各有利弊,应当根据不同的情况来进行选择使用:
当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式;
当字符串相加操作较多的情况下,建议使用StringBuilder,如果采用了多线程,则使用StringBuffer。
常见面试题
1、下面这段代码的输出结果是什么?
String a = "hello2"; String b = "hello" + 2; System.out.println((a == b));输出结果为:true。
原因很简单,"hello"+2在编译期间就已经被优化成"hello2",因此在运行期间,变量a和变量b指向的是同一个对象。
2.下面这段代码的输出结果是什么?
String a = "hello2"; String b = "hello"; String c = b + 2; System.out.println((a == c));输出结果为:false。
由于有符号引用的存在,所以 String c = b + 2;不会在编译期间被优化,不会把b+2当做字面常量来处理的,因此这种方式生成的对象事实上是保存在堆上的。因此a和c指向的并不是同一个对象。
javap -c得到的内容:

3.下面这段代码的输出结果是什么?
String a = "hello2"; final String b = "hello"; String c = b + 2; System.out.println((a == c));输出结果为:true。
对于被final修饰的变量,会在class文件常量池中保存一个副本,也就是说不会通过连接而进行访问,对final变量的访问在编译期间都会直接被替代为真实的值。那么String c = b + 2;在编译期间就会被优化成:String c = "hello" + 2;
下图是javap -c的内容:
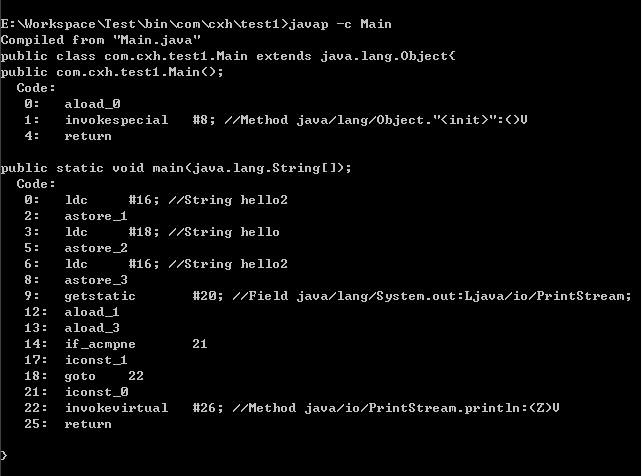
4.下面这段代码输出结果为:
public class Main {
public static void main(String[] args) {
String a = "hello2";
final String b = getHello();
String c = b + 2;
System.out.println((a == c));
}
public static String getHello() {
return "hello";
}
}输出结果为false。
这里面虽然将b用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定,因此a和c指向的不是同一个对象。
5.下面这段代码的输出结果是什么?
public class Main {
public static void main(String[] args) {
String a = "hello";
String b = new String("hello");
String c = new String("hello");
String d = b.intern();
System.out.println(a==b);
System.out.println(b==c);
System.out.println(b==d);
System.out.println(a==d);
}
}输出结果为:false,false,false,true
这里面涉及到的是String.intern方法的使用。在String类中,intern方法是一个本地方法,在JAVA SE6之前,intern方法会在运行时常量池中查找是否存在内容相同的字符串,如果存在则返回指向该字符串的引用,如果不存在,则会将该字符串入池,并返回一个指向该字符串的引用。因此,a和d指向的是同一个对象。
6.String str = new String("abc")创建了多少个对象?
这个问题在很多书籍上都有说到比如《Java程序员面试宝典》,包括很多国内大公司笔试面试题都会遇到,大部分网上流传的以及一些面试书籍上都说是2个对象,这种说法是片面的。
如果有不懂得地方可以参考这篇帖子:
http://rednaxelafx.iteye.com/blog/774673/
首先必须弄清楚创建对象的含义,创建是什么时候创建的?这段代码在运行期间会创建2个对象么?毫无疑问不可能,用javap -c反编译即可得到JVM执行的字节码内容:

很显然,new只调用了一次,也就是说只创建了一个对象。
而这道题目让人混淆的地方就是这里,这段代码在运行期间确实只创建了一个对象,即在堆上创建了"abc"对象。而为什么大家都在说是2个对象呢,这里面要澄清一个概念 该段代码执行过程和类的加载过程是有区别的。在类加载的过程中,确实在运行时常量池中创建了一个"abc"对象,而在代码执行过程中确实只创建了一个String对象。
因此,这个问题如果换成 String str = new String("abc")涉及到几个String对象?合理的解释是2个。
个人觉得在面试的时候如果遇到这个问题,可以向面试官询问清楚”是这段代码执行过程中创建了多少个对象还是涉及到多少个对象“再根据具体的来进行回答。
7.下面这段代码1)和2)的区别是什么?
public class Main {
public static void main(String[] args) {
String str1 = "I";
//str1 += "love"+"java"; 1)
str1 = str1+"love"+"java"; //2)
}
}1)的效率比2)的效率要高,1)中的"love"+"java"在编译期间会被优化成"lovejava",而2)中的不会被优化。下面是两种方式的字节码:
1)的字节码:

2)的字节码:

可以看出,在1)中只进行了一次append操作,而在2)中进行了两次append操作。
参考:
主要来自
探秘Java中的String、StringBuilder以及StringBuffer - Matrix海子 - 博客园
http://rednaxelafx.iteye.com/blog/774673/
JVM 常量池理解 - 走在架构师的大道上 Jack.Wang's home - BlogJava
http://www.jb51.net/article/36041.htm
个人博客:wggz.top
个人微信公众号:后端开发充电宝
欢迎关注👏
















 3280
3280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









