




 本文深入解析DBSCAN密度聚类算法,介绍其通过邻域参数刻画样本分布,发现任意形状聚类的能力。阐述算法思想及实现过程,对比K-means在非凸数据集上的表现,展示参数选择对聚类效果的影响。
本文深入解析DBSCAN密度聚类算法,介绍其通过邻域参数刻画样本分布,发现任意形状聚类的能力。阐述算法思想及实现过程,对比K-means在非凸数据集上的表现,展示参数选择对聚类效果的影响。
相关概念
是一种密度聚类算法,它基于一组"邻域" (neighborhood) 参数来刻画样本分布的紧密程度.。可在噪声的空间数据库中发现任意形状的聚类。
给定数据集D={,
},定义下面几个概念:
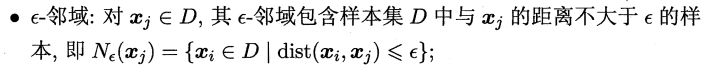

如下图:
故DBSCAN 将"簇"定义为:由密度可达关系导出的最大的 密度相连样本集合。
那么如何找这个“簇”呢?
====》即是由 x 密度可达的所有样本组成的集合。
算法思想
DBSCAN 算法先任选数据集中的一个核心对象为"种子" (seed),再由此出发确定相应的聚类簇。如下描述:
(1)Repeat
(2)从数据库中抽出一个未处理的点;
(3)IF抽出的点是核心点 THEN 找出所有从该点密度可达的对象,形成一个簇;
(4)ELSE 抽出的点是边缘点(非核心对象),跳出本次循环,寻找下一个点;
(5)UNTIL 所有的点都被处理。
详细过程如下:

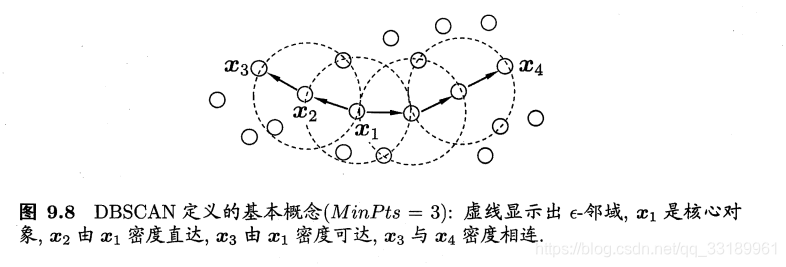
聚类生成过程如下图:
优缺点
缺点:
- DBSCAN对用户定义的参数很敏感,细微的不同都可能导致差别很大的结果,而参数(如邻域半径,核心对象邻域内最小样本数等)的选择无规律可循,只能靠经验确定。
优点:
- 对于非凸数据集的聚类表现好
实现
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
#准备数据
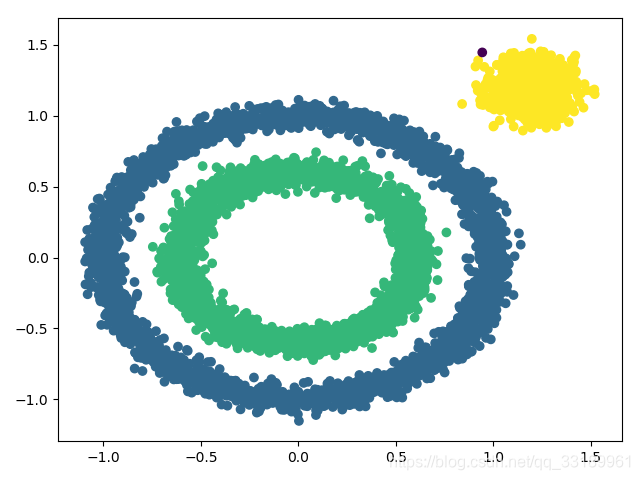
X1, y1=datasets.make_circles(n_samples=5000, factor=.6, noise=.05)
X2, y2 = datasets.make_blobs(n_samples=1000, n_features=2, centers=[[1.2,1.2]], cluster_std=[[.1]], random_state=9)
X = np.concatenate((X1, X2))
#开始聚类
y_pred = DBSCAN(eps = 0.1, min_samples = 10).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()DBSCAN函数:eps是邻域半径,min_samples是该邻域内应有的最小样本数。其余参数时默认值就好。
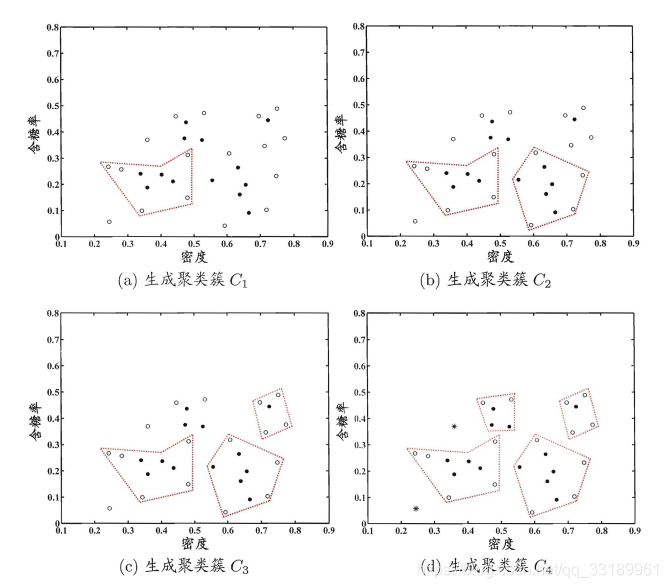
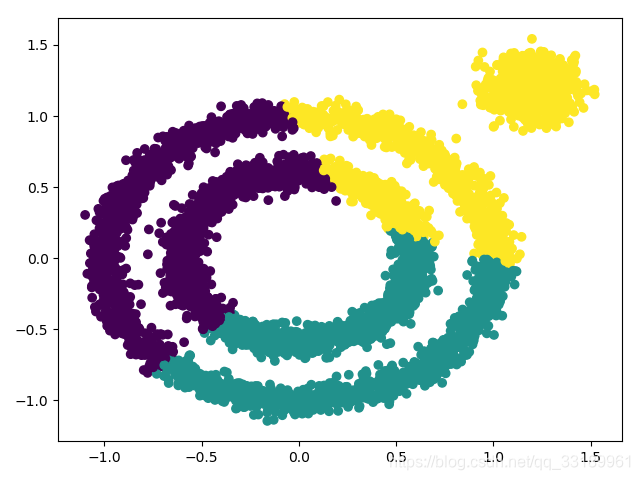
但是如果邻域半径和核心对象邻域内最小样本数等参数选取不好的话,则聚类效果会不一样,比如出现下面这种情况:
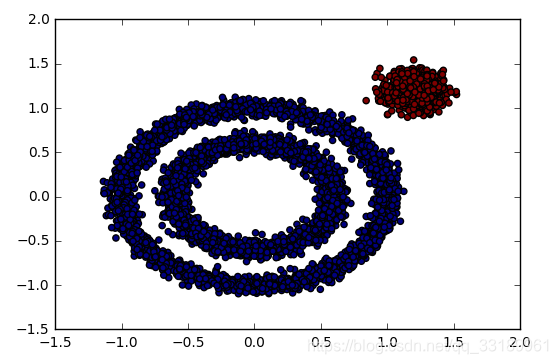
对于非凸数据集的聚类表现好,同样的数据如果采用k-means的话则是:
参考
- https://blog.csdn.net/u010670689/article/details/74936338(对比了DBSCAN和K-mean算法在处理特殊分布数据上的差异)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









