









一、决策树原理
决策树通过判断特征值是否满足某范围条件(通过if…else对一系列问题进行推导),并选择两条路径中的一条,不断重复这个过程直到最终实现决策。
#下面采用酒的数据进行决策树的建模
#导入numpy
import numpy as np
#导入画图工具
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
#导入tree模型和数据集加载工具
from sklearn import tree, datasets
#导入数据集拆分工具
from sklearn.model_selection import train_test_split
wine = datasets.load_wine()
#只选取数据集的前两个特征值
X = wine.data[:,:2]
y = wine.target
#将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
#现在完成了数据集的拆分,接下来开始用决策树分类器进行分类
#设定决策树分类器最大深度为1,决策树的深度代表的是问题的数量
clf = tree.DecisionTreeClassifier(max_depth=1)
#拟合训练集
clf.fit(X_train, y_train)
#下面都是绘图相关的程序
#查看分类器的表现
#定义图像中分区的颜色和散点的颜色
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
#分别用样本的两个特征值创建图像的横轴和纵轴
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
#给每个分类中的样本分配不同的颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点把样本表示出来
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolors='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title('Classifier:Decision Tree(max_depth=1)')
plt.show()
#可以看到还是有很多点被错误地分类,这是由于深度小导致的,试试增大深度为3、5下的情况。
max_depth为1的时候决策树的分类图形

max_depth为3的时候决策树的分类图形

max_depth为5的时候决策树的分类图形

可以看到随着决策树最大深度的上升,分类器尽可能地将数据点放到正确的分类。
二、查看决策树具体实现过程
想知道决策树具体的实现,可以通过graphviz工具来分析
#导入graphviz工具
import graphviz
#导入决策树中输出graphviz的接口
from sklearn.tree import export_graphviz
#选择最大深度为3的分类模型
export_graphviz(clf2, out_file="wine.dot", class_names=wine.target_names,
feature_names=wine.feature_names[:2], impurity=False, filled=True)
#打开一个dot文件
with open("wine.dot") as f:
dot_graph = f.read()
#显示dot文件中的图像
graphviz.Source(dot_graph)
可以通过下载的graphviz工具bin目录下的gvedit.exe程序载入dot文件,graphviz工具下载链接。
我们可以看到决策树每一步决策的具体实现。从根节点第一个决策是判断样本的酒精含量小于等于12.79,决策的样本总共有133个。其中value=[47,48,38]指的是有47个样本属于class_0,有48个样本属于class_1,有38个样本属于class_2,如果样本满足条件则被分类为class_1,否则被分类为class_0,以此类推。最后可以在最底部的分支看到并不是所有的数据点都被正确归类。


决策树的优势就是可将模型数据化,但同时它还是不可避免地会出现过拟合。,为了避免过拟合,可以通过随机森林算法来实现。
三、随机森林
即使在建模的时候使用类似max_depth或者max_leaf_nodes等参数对决策树进行预剪枝处理,它还是不可避免地出现过拟合现象。为了解决决策树的不足,可以使用集合的方法来解决这个问题。
随机森林算法是一种集合学习方法,也可用于回归和分类。所谓集合学习方法指的是多个机器学习算法综合在一起,制造出一个更大的模型。
比较流行的集合算法有随机森林(Random Tree)和梯度上升决策树(Gradient Boosted Decision Tree, GBDT)
#随机森林的构建
#导入机器学习库里面的集合学习算法中的随机森林模型
from sklearn.ensemble import RandomForestClassifier
#导入酒集合
wine = datasets.load_wine()
#选择前两个特征
X = wine.data[:,:2]
y = wine.target
#将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y)
#设定随机森林的树数为6
forest = RandomForestClassifier(n_estimators=6, random_state=3)
#使用模型拟合数据
forest.fit(X_train, y_train)
结果输出随机森林的全部参数,下面说明下参数作用。
- bootstrap代表的是bootstrap sample,指的是放回抽样。这样可能会使抽到的样本重复出现,从而使每棵树在构建的时候彼此会存在差异。
- max_feathers选择最大值特征数量,默认选取全部特征。max_feathers越大,每棵树长得越像,因为每棵决策树都有更多的选择;而如果它变小,模型在数据拟合的时候就没有太多选择的空间,决策树在不得不制造更多的节点来拟合数据,因此每决策棵树长得各不相同。
- n_estimators选择随机森林中决策树的数量,在随机森林构建之后,决策树都会单独进行预测。如果是用在回归分析的话,随机森林会对所有决策树预测的值取平均值。如果用在分类,在森林内部会进行投票,即对每棵决策树对样本类别预测的概率取平均值,并把样本归类为在概率最高的类别。

#定义图像中分区和散点的颜色
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
#分别用样本的两个特征值创建图像的横纵坐标
x_min, x_max = X_train[:, 0].min() - 1, X_train[:, 0].max() + 1
y_min, y_max = X_train[:, 1].min() - 1, X_train[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02),
np.arange(y_min, y_max, .02))
Z = forest.predict(np.c_[xx.ravel(), yy.ravel()])
#给每个分类分配颜色
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
#用散点图表示出来
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolors='k')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("Classifier:RandomForest")
plt.show()

通过对比上述仅用一棵决策树,随机森林分类得更加细腻准确。
四、实战——这男/女朋友能不能要
采用随机森林对成年人数据集进行分析。成年人数据集可以在这里下载,此外这个网站还有很多其他的数据集库。

下载adult.data,这里的文件类型是.data,只需要将其更改为.csv即可。
# 导入数据分析库
import pandas as pd
# 用pandas打开csv文件 并给每列数据赋予特征名(feature name)
adult_data = pd.read_csv('adult.csv', header=None, index_col=False,
names=['Age', 'Company Type', 'Weight', 'Education',
'Length of Education', 'Marital Status', 'Career',
'Family Condition', 'Race', 'Gender', 'Assets Income',
'Assets Loss', 'Working Hours per Week', 'Birthplace',
'Income per Year'])
# 为了方便,只选取其中一部分数据(特征值)
adult_data_lite = adult_data[['Age', 'Company Type', 'Education', 'Career', 'Gender', 'Working Hours per Week', 'Income per Year']]
# 查看数据是否被过滤成功
display(adult_data_lite.head())
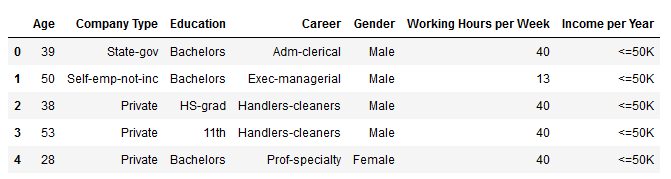
可以看到数据大多不是整数值,在数据处理的时候不是那么方便。为了让数据更加易于处理,可以用numpy中的get_dummies功能,它可以在现有的的数据集上添加虚拟变量,让数据集变成可用的格式。
# 使用get_dummies将文本数据转化为虚拟数值
data_dummies = pd.get_dummies(adult_data_lite)
# 对比样本原始特征和虚拟变量特征
print('Sample Native Features:\r\n', list(adult_data_lite.columns), '\r\n')
print('Virtual Variable Features:\r\n', list(data_dummies.columns))

可以看到get_dummies将字符串数据拆分成“特征名_特征值”的形式,将样本满足对应特征的值赋予1,否则为0。
# 显示数据集中的前5行
data_dummies.head()

可以看到数据集的特征值扩充为46个。
下面用特征向量X和分类标签y将数据集进行划分。
# 定义数据集的特征值
features = data_dummies.loc[:, 'Age':'Career_ Transport-moving']
# 将特征值赋值给X
X = features.values
# 将收入大于50K作为预测目标
y = data_dummies['Income per Year_ >50K'].values
print('Feature Shape: {}\n Tag Shape: {}\n'.format(X.shape, y.shape))

可以看到满足上述两个条件的的样本数据有32561条,每个样本有42个特征值。下面利用这些数据使用随机森林进行拟合模型。
from sklearn.model_selection import train_test_split
from sklearn import tree
# 使用决策树建模并做出决策
# 将数据拆分为训练集和测试集 随机每次都不同
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# 用最大深度为5的随机森林拟合数据集的数据
adult_data_tree = tree.DecisionTreeClassifier(max_depth=5)
adult_data_tree.fit(X_train, y_train)
print('Module Score:{:.2f}'.format(adult_data_tree.score(X_test, y_test)))
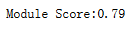
可以看到分数有0.79,模型的可信度还是可以的。
下面假设有一个人年龄28,在省机关工作,学历是硕士,性别女,每周工作40小时,职业是文员,将这些数据输入到模型看输出结果。看她值不值得,嘻嘻嘻嘻o
Mrs = [[28, 40, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0,]]
# 使用模型做出预测
dating_or_not = adult_data_tree.predict(Mrs)
if dating_or_not == 1:
print("go!!!")
else:
print("no!!!")

噢不!太残酷了,她不值得,看来要找富婆包养是不行了,还是要靠自己呀 : 3
但事实上这些数据是1994年美国的人口数据,收入指的是年收入,而非月入50k,所以这些数据放在真实场景可是不准确的哦!大概和TA还是机会呢。(我觉得女孩最重要的是soul!!!而非奈子!!!)















 4951
4951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









