







from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(2017)
导入数据
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
- 我们来看看数据具体的图像
%matplotlib inline
plt.plot(x_train, y_train, 'bo')
[<matplotlib.lines.Line2D at 0x27478786128>]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-k0OrFM8L-1570107669452)(output_4_1.png)]
- 然后, 把数据转换成
tensorflow的tensor形式
x = tf.constant(x_train, name='x')
y = tf.constant(y_train, name='y')
定义一个线性模型
- 定义模型的
w以及b参数 - 用
w, b定义这个线性模型
w = tf.Variable(initial_value=tf.random_normal(shape=(), seed=2017), dtype=tf.float32, name='weight')
b = tf.Variable(initial_value=0, dtype=tf.float32, name='biase')
with tf.variable_scope('Linear_Model'):
y_pred = w * x + b
注意tf.variable_scope()这个函数, 它是用来规定一个变量的区域的, 在这个with语句下定义的所有变量都在同一个变量域当中, 域名就是variable_scope()的参数.
那么它有什么用呢?
实际上, 所有变量域中的变量的名字都以域名为前缀:
print(w.name)
print(y_pred.name)
weight:0
Linear_Model/add:0
# 开启交互式会话
sess = tf.InteractiveSession()
# 一定要有初始化这一步!!!
sess.run(tf.global_variables_initializer())
好了, 现在我们可以看一下这个线性模型的输出具体长什么样了
%matplotlib inline
# 要先将`tensor`的内容`fetch`出来
y_pred_numpy = y_pred.eval(session=sess)
plt.plot(x_train, y_train, 'bo', label='real')
plt.plot(x_train, y_pred_numpy, 'ro', label='estimated')
plt.legend()
<matplotlib.legend.Legend at 0x27478a663c8>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V0qk57gl-1570107669453)(output_13_1.png)]
优化模型
- 定义误差函数
前面提到过, 为了优化我们的模型, 需要构建一个误差(loss)函数, 来告诉我们优化的好坏程度.
而这里, 我们想要预测值和真实值尽可能接近, 因此, 我们就用上面定义的loss进行衡量.
loss = tf.reduce_mean(tf.square(y - y_pred))
# 看看在当前模型下的误差有多少
print(loss.eval(session=sess))#跟sess.run(loss.eval())是一样的
28.152376
- 现在我们用梯度下降法去优化这个模型
首先我们需要求解误差函数对于每个参数的梯度. 通过求导知识可以知道是下面的形式:
∂ ∂ w = 2 n ∑ i = 1 n x i ( w x i + b − y i ) ∂ ∂ b = 2 n ∑ i = 1 n ( w x i + b − y i ) \frac{\partial}{\partial w} = \frac{2}{n} \sum_{i=1}^n x_i(w x_i + b - y_i) \\ \frac{\partial}{\partial b} = \frac{2}{n} \sum_{i=1}^n (w x_i + b - y_i) ∂w∂=n2i=1∑nxi(wxi+b−yi)∂b∂=n2i=1∑n(wxi+b−yi)
但实际上我们并不会这么去用, 因为tensorflow拥有自动求导功能, 省去了这些数学知识以及手工求导的复杂工作. 可以通过下面的代码去获得一个标量对参数的导函数
w_grad, b_grad = tf.gradients(loss, [w, b])
print('w_grad: %.4f' % w_grad.eval(session=sess))
print('b_grad: %.4f' % b_grad.eval(session=sess))
w_grad: 68.7412
b_grad: 9.6534
对梯度乘上一个步长(lr)来更新参数.一般我们把这个步长称为学习率
lr = 1e-2
w_update = w.assign_sub(lr * w_grad)
b_update = b.assign_sub(lr * b_grad)
sess.run([w_update, b_update])
[0.49174082, -0.09653385]
在更新参数完成后, 我们再一次看看模型的输出结果
%matplotlib inline
y_pred_numpy = y_pred.eval(session=sess)
plt.plot(x_train, y_train, 'bo', label='real')
plt.plot(x_train, y_pred_numpy, 'ro', label='estimated')
plt.legend()
<matplotlib.legend.Legend at 0x27478b03320>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LmMJPTUu-1570107669453)(output_22_1.png)]
更新一次之后, 我们发现红色点跑到了蓝色点附近, 相比之前靠得更近了, 说明通过梯度下降模型得到了优化. 当然我们可以多更新几次
%matplotlib notebook
fig = plt.figure()
ax = fig.add_subplot(111)
plt.ion()
fig.show()
fig.canvas.draw()
sess.run(tf.global_variables_initializer())
for e in range(10):
sess.run([w_update, b_update])
y_pred_numpy = y_pred.eval(session=sess)
loss_numpy = loss.eval(session=sess)
ax.clear()
ax.plot(x_train, y_train, 'bo', label='real')
ax.plot(x_train, y_pred_numpy, 'ro', label='estimated')
ax.legend()
fig.canvas.draw()
plt.pause(1)
print('epoch: {}, loss: {}'.format(e, loss_numpy))
<IPython.core.display.Javascript object>
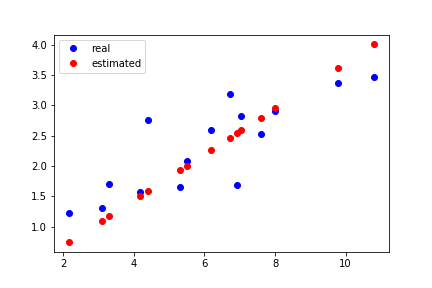
epoch: 0, loss: 0.6212941408157349
epoch: 1, loss: 0.2677772343158722
epoch: 2, loss: 0.2607705891132355
epoch: 3, loss: 0.2601791024208069
epoch: 4, loss: 0.2597087323665619
epoch: 5, loss: 0.2592428922653198
epoch: 6, loss: 0.2587795853614807
epoch: 7, loss: 0.25831854343414307
epoch: 8, loss: 0.2578599452972412
epoch: 9, loss: 0.2574036419391632
<IPython.core.display.Javascript object>

再来看看最后的模型结果吧
%matplotlib inline
plt.plot(x_train, y_train, 'bo', label='real')
plt.plot(x_train, y_pred_numpy, 'ro', label='estimated')
plt.legend()
<matplotlib.legend.Legend at 0x27478bc1b00>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qM7XRo6i-1570107669454)(output_26_1.png)]
sess.close()
经过 10 次更新,我们发现红色的预测结果已经比较好的拟合了蓝色的真实值。
现在你已经学会了你的第一个机器学习模型了,再接再厉,完成下面的小练习。
小练习:
重启 notebook 运行上面的线性回归模型,但是改变训练次数以及不同的学习率进行尝试得到不同的结果
多项式回归
# 将之前的`graph`清除
tf.reset_default_graph()
# 定义一个多变量函数
w_target = np.array([0.5, 3, 2.4]) # 定义参数
b_target = np.array([0.9]) # 定义参数
f_des = 'y = {:.2f} + {:.2f} * x + {:.2f} * x^2 + {:.2f} * x^3'.format(
b_target[0], w_target[0], w_target[1], w_target[2]) # 打印出函数的式子
print(f_des)
y = 0.90 + 0.50 * x + 3.00 * x^2 + 2.40 * x^3
同样地, 我们看看这个多项式的图像
%matplotlib inline
import matplotlib.pyplot as plt
# 画出这个函数的曲线
x_sample = np.arange(-3, 3.1, 0.1)
y_sample = b_target[0] + w_target[0] * x_sample + w_target[1] * x_sample ** 2 + w_target[2] * x_sample ** 3
print(x_sample.shape)
plt.plot(x_sample, y_sample, label='real curve')
plt.legend()
(61,)
<matplotlib.legend.Legend at 0x27478c0ab70>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q1STpOtz-1570107669455)(output_34_2.png)]
首先我们构造形如 [ x , x 2 , x 3 ] [x, x^{2}, x^{3}] [x,x2,x3]这样的数据, 把多项式回归问题转换为线性回归问题
x_train = np.stack([x_sample ** i for i in range(1, 4)], axis=1)
print(x_train.shape)
x_train = tf.constant(x_train, dtype=tf.float32, name='x_train')
y_train = tf.constant(y_sample, dtype=tf.float32, name='y_train')
print(x_train)
(61, 3)
Tensor("x_train:0", shape=(61, 3), dtype=float32)
构造线性模型
w = tf.Variable(initial_value=tf.random_normal(shape=(3, 1)), dtype=tf.float32, name='weights')
b = tf.Variable(initial_value=0, dtype=tf.float32, name='bias')
def multi_linear(x):
return tf.squeeze(tf.matmul(x, w) + b)
y_ = multi_linear(x_train)
sess = tf.InteractiveSession()
画出模型输出的结果和真实结果的对比
%matplotlib inline
sess.run(tf.global_variables_initializer())
x_train_value = x_train.eval(session=sess)
y_train_value = y_train.eval(session=sess)
y_pred_value = y_.eval(session=sess)
print(x_train_value.shape)
print(y_train_value.shape)
plt.plot(x_train_value[:,0], y_pred_value, label='fitting curve', color='r')
plt.plot(x_train_value[:,0], y_train_value, label='real curve', color='b')
plt.legend()
(61, 3)
(61,)
<matplotlib.legend.Legend at 0x27479c63c18>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kuXCdEnn-1570107669456)(output_41_2.png)]
同样地, 定义loss函数
loss = tf.reduce_mean(tf.square(y_train - y_))
loss_numpy = sess.run(loss)
print(loss_numpy)
820.94867
# 利用`tf.gradients()`自动求解导数
w_grad, b_grad = tf.gradients(loss, [w, b])
print(w_grad.eval(session=sess))
print(b_grad.eval(session=sess))
[[ -71.73235]
[-151.54886]
[-473.57257]]
-27.968672
# 利用梯度下降更新参数
lr = 1e-3
w_update = w.assign_sub(lr * w_grad)
b_update = b.assign_sub(lr * b_grad)
我们来看看更新一次之后的效果
%matplotlib inline
sess.run([w_update, b_update])
x_train_value = x_train.eval(session=sess)
y_train_value = y_train.eval(session=sess)
y_pred_value = y_.eval(session=sess)
loss_numpy = loss.eval(session=sess)
plt.plot(x_train_value[:,0], y_pred_value, label='fitting curve', color='r')
plt.plot(x_train_value[:,0], y_train_value, label='real curve', color='b')
plt.legend()
plt.title('loss: %.4f' % loss_numpy)
Text(0.5, 1.0, 'loss: 595.1406')
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zFn7wbQz-1570107669457)(output_47_1.png)]
可以看到, 一次更新的效果并不好, 那让我们多尝试几次
%matplotlib notebook
fig = plt.figure()
ax = fig.add_subplot(111)
plt.ion()
fig.show()
fig.canvas.draw()
sess.run(tf.global_variables_initializer())
for e in range(100):
sess.run([w_update, b_update])
x_train_value = x_train.eval(session=sess)
y_train_value = y_train.eval(session=sess)
y_pred_value = y_.eval(session=sess)
loss_numpy = loss.eval(session=sess)
ax.clear()
ax.plot(x_train_value[:,0], y_pred_value, label='fitting curve', color='r')
ax.plot(x_train_value[:,0], y_train_value, label='real curve', color='b')
ax.legend()
fig.canvas.draw()
plt.pause(0.1)
if (e + 1) % 20 == 0:
print('epoch: {}, loss: {}'.format(e + 1, loss_numpy))
<IPython.core.display.Javascript object>
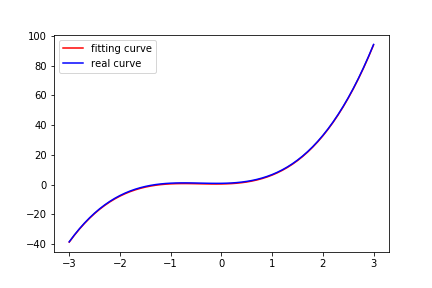
epoch: 20, loss: 22.765066146850586
epoch: 40, loss: 5.385499954223633
epoch: 60, loss: 1.3279372453689575
epoch: 80, loss: 0.3785684108734131
epoch: 100, loss: 0.1546773463487625
<IPython.core.display.Javascript object>
可以看到,经过 100 次更新之后,可以看到拟合的线和真实的线已经完全重合了
小练习:上面的例子是一个三次的多项式,尝试使用二次的多项式去拟合它,看看最后能做到多好















 820
820

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









