






损失函数
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
预测与偏置

常见的损失函数
Error 与 Bias
e
t
=
f
t
−
d
t
e_{t}={f_{t}-d_{t}}
et=ft−dt
f
t
f_{t}
ft是预测数据,
d
t
d_{t}
dt是真实数据
b
i
a
s
=
1
n
∑
n
e
t
bias = \frac{1}{n}\sum_{n}e_{t}
bias=n1n∑et
RMSE
R
M
S
E
=
1
n
∑
n
e
t
2
RMSE= \sqrt{\frac{1}{n}\sum_{n}e_{t}^2}
RMSE=n1n∑et2


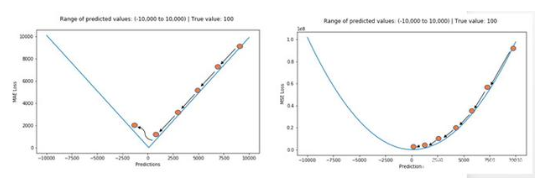
整体偏向离群值。
平均绝对误差(Mean Absolute Error,MAE)
M
A
E
=
1
n
∑
n
∣
e
t
∣
MAE= \frac{1}{n}\sum_{n}|e_{t}|
MAE=n1n∑∣et∣


受离群点(脱离样本分布的异常值)影响较小。
MAPE
M
A
P
E
=
1
n
∑
n
∣
e
t
∣
d
t
MAPE = \frac{1}{n}\sum_{n}\frac{|e_{t}|}{d_{t}}
MAPE=n1n∑dt∣et∣
也就是误差占真实值的比例,如果同样的误差,当其真实值较小时,会造成误差极大的现象,也就意味着更容易受到较小真实值的影响。
比较

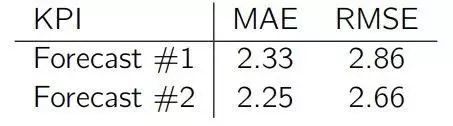


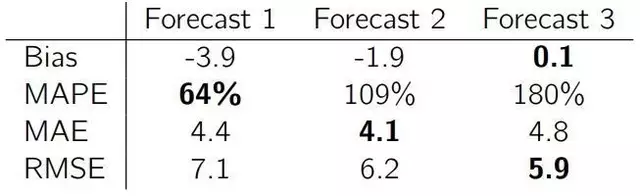
Forecast1 采用样本中较低的值
Forecast2 采用样本的中位数
Forecast3 采用样本的平均数

Huber 损失函数
H
u
b
e
r
=
{
1
2
e
t
2
,
f
o
r
∣
e
t
∣
≤
δ
δ
∣
e
t
∣
−
1
2
δ
2
,
o
t
h
e
r
w
i
s
e
Huber = \begin{cases} \frac{1}{2}e_{t}^2,&for|e_{t}|\leq\delta\\ \delta|e_{t}|-\frac{1}{2}\delta^2,&otherwise\\ \end{cases}
Huber={21et2,δ∣et∣−21δ2,for∣et∣≤δotherwise
Huber损失对数据中的异常点没有平方误差损失那么敏感。本质上,Huber损失是绝对误差,只是在误差很小时,就变为平方误差。误差降到多小时变为二次误差由超参数
δ
(
d
e
l
t
a
)
\delta(delta)
δ(delta)来控制。当Huber损失在
[
0
−
δ
,
0
+
δ
]
[0-\delta, 0+\delta]
[0−δ,0+δ]之间时,等价为MSE,而在
[
−
∞
,
δ
]
[-\infty, \delta]
[−∞,δ]和
[
δ
,
+
∞
]
[\delta,+\infty]
[δ,+∞]时为MAE。Huber损失结合了MSE和MAE的优点,对异常点更加鲁棒。

# huber 损失
def huber(true, pred, delta):
loss = np.where(np.abs(true-pred) < delta , 0.5*((true-pred)**2), delta*np.abs(true - pred) - 0.5*(delta**2))
return np.sum(loss)















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









