






一、英文的词频统计
import jieba
import numpy as np
import PIL.Image as Image
from wordcloud import WordCloud
#读取stopwords.txt
with open('stopwords.txt','r',encoding ='utf-8') as f:
st = f.readlines()
stopwords = [i.strip() for i in st]
stopwords.append('\n')
# 导入
with open("the little prince.txt", 'r') as file:
datas = file.readlines()
# 处理
words = []
for i in datas:
words += i.replace("\n", "").replace(".", "").replace(":", "").replace("...", "").split(" ")
#去除停用词
for j in stopwords:
if j in words:
#将words中的每一个j都删除
for k in range(words.count(j)):
words.remove(j)
dict_counts = {}
for word in words:
#如果是一个字的就不统计了
if len(word)>1:
dict_counts[word] = words.count(word)
#print(words)
#排序
lists = list(dict_counts.items())
lists.sort(key = lambda x:x[-1],reverse = True)
#输出前n条的数据
def put(n):
global lists
word_s = []
for i in range(n):
word_s.append(lists[i][0])
print(lists[i])
word_space = ' '.join(word_s)
return word_space
res = put(50)
pic = np.array(Image.open("pig.jpg"))
wordclo = WordCloud(
font_path='impact.ttf', # 设置字体,本机的字体
mask=pic, # 设置背景图片
background_color='white', # 设置背景颜色
max_font_size=180, # 字体最大值
max_words=1000, # 设置最多字数
stopwords={'i'} # 设置停用词,不出现
).generate(res)
image = wordclo.to_image()
image.show() #显示图片
wordclo.to_file('result1.png')其中the little prince.txt是这样的:
stopwords.txt是这样的:
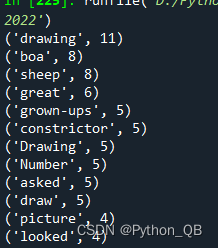
最后统计出是:
输出的图片:
二、中文分词
中文分词需要用到jieba.lcut()
其他基本类似
import jieba
import numpy as np
import PIL.Image as Image
from wordcloud import WordCloud
#读取stopwords.txt
with open('stopwords.txt','r',encoding ='utf-8') as f:
st = f.readlines()
stopwords = [i.strip() for i in st]
stopwords.append('\n')
#stopwords = [i.strip() for i in open('stopwords.txt', encoding='UTF-8').readlines()]
#读取data.txt
with open('da.txt','r',encoding ='utf-8') as f:
w = f.read()
words = jieba.lcut(w)
#print(words)
#去除停用词
for j in stopwords:
if j in words:
#将words中的每一个j都删除
for k in range(words.count(j)):
words.remove(j)
dict_counts = {}
for word in words:
#如果是一个字的就不统计了
if len(word)>1:
dict_counts[word] = dict_counts.get(word,0)+1
dict_counts[word] = words.count(word)
#print(words)
#排序
lists = list(dict_counts.items())
lists.sort(key = lambda x:x[-1],reverse = True)
#输出前n条的数据
def put(n):
global lists
word_s = []
for i in range(n):
word_s.append(lists[i][0])
print(lists[i])
word_space = ' '.join(word_s)
return word_space
res = put(100)
pic = np.array(Image.open("mo.jpg"))
wordclo = WordCloud(
font_path='STXINGKA.TTF', # 设置字体,本机的字体
mask=pic, # 设置背景图片
background_color='white', # 设置背景颜色
max_font_size=180, # 字体最大值
max_words=1000, # 设置最多字数
stopwords={'呢'} # 设置停用词,不出现
).generate(res)
image = wordclo.to_image()
image.show() #显示图片
wordclo.to_file('result.png')打印结果:
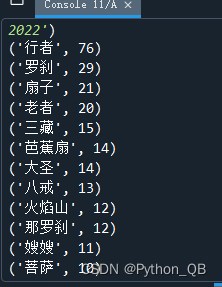
图片:


















 922
922











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









