






集成学习方法

随机森林






实例
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.ensemble import RandomForestClassifier
#导入数据集
data = load_breast_cancer()
#查看特征维度
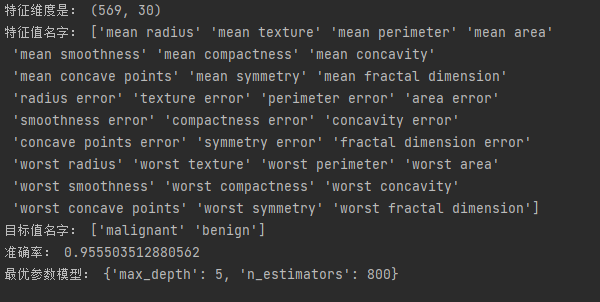
print('特征维度是:',data.data.shape)
#特征值名字
print('特征值名字:',data.feature_names)
#目标值名字
print('目标值名字:',data.target_names)
#分为训练集及测试集
x_train,x_test,y_train,y_test = train_test_split(data.data,data.target,train_size=0.25)
#随机森林预测(超参数调优)
rf = RandomForestClassifier()
param = {'n_estimators':[120,200,300,500,800],'max_depth':[5,8,15,20]}
#交叉验证与网格搜索
gc = GridSearchCV(rf,param_grid=param,cv=3)
gc.fit(x_train,y_train)
print('准确率:',gc.score(x_test,y_test))
print('最优参数模型:',gc.best_params_)
找到参数
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.ensemble import RandomForestClassifier
#导入数据集
data = load_breast_cancer()
#查看特征维度
print('特征维度是:',data.data.shape)
#特征值名字
print('特征值名字:',data.feature_names)
#目标值名字
print('目标值名字:',data.target_names)
#分为训练集及测试集
x_train,x_test,y_train,y_test = train_test_split(data.data,data.target,train_size=0.25)
#随机森林预测(超参数调优)
rf = RandomForestClassifier(n_estimators=800,max_depth=5)
# param = {'n_estimators':[120,200,300,500,800],'max_depth':[5,8,15,20]}
#
# #交叉验证与网格搜索
# gc = GridSearchCV(rf,param_grid=param,cv=3)
#
# gc.fit(x_train,y_train)
#
# print('准确率:',gc.score(x_test,y_test))
#
# print('最优参数模型:',gc.best_params_)
rf.fit(x_train,y_train)
#输出预测值
y_pre = rf.predict(x_test)
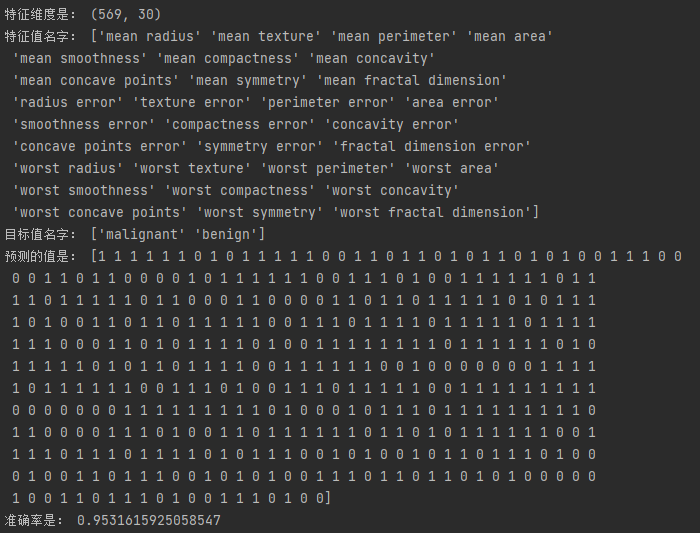
print('预测的值是:',y_pre)
#输出准确率
print('准确率是:',rf.score(x_test,y_test))


















 1277
1277

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









