







1 前言
知识图谱对齐的目标是链接不同知识库中的相等实体。为了更好的利用图结构信息和图元素信息(如名称、描述、属性),大多数工作都是通过实体间的连接关系进行图元素信息的传播。然而,由于图的异质性,对齐的实体精确度受不同邻居聚合影响较大。这篇工作提出了仅利用图元素信息的交互模型,该算法不是聚集邻居,而是计算邻居之间的交互,能够捕捉到邻居之间的细粒度匹配信息。类似地,属性之间的交互也被建模。实验结果表明,在DBP15K数据集上,对于HitRatio@1,作者的模型比最好的方法提高1.9-9.7%的性能。
2 相关背景
为了利用图元素信息,目前最可行的方式是采用图节点信息将节点初始化为embedding,再通过GCN的变种对邻居信息进行聚合更新其embedding。然而,不同的图谱结构高度异质,所以并不是相同的实体会有相似的邻居。例如,图1中矩形表示需要对齐的实体,圆形表示其邻居。从图中,可以看到对于G2中“english”实体在G1中找不到对应的实体。在这种情况下,使用GCN整合不同的邻居信息可能会将错误进行传播导致错误,关系数越多的节点中,这种现象就愈发明显。虽然有些工作区分了不同邻居的影响,但本质上,基于GCN的模型仍然混合了不同的图元素信息去表示一个实体。对于这个问题,HMAN将图结构信息和图元素信息分别进行模型处理,然而,这项工作忽略了邻居的图元素信息。更进一步的有,和大多数整合邻居信息的工作类似,这项工作也会导致错误信息在匹配实体之间进行传播。
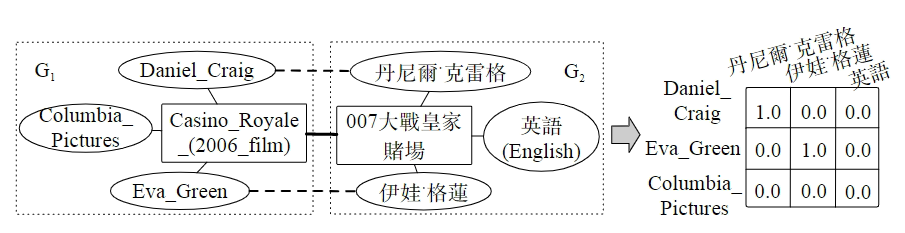
图1 实体对齐
为了处理邻居或属性匹配导致的噪声信息,作者提出了一种只利用图元素信息的Bert交互模型,这种模型对实体和邻居的名称、描述、属性采用统一的处理方式。具体来说,作者模仿人类对比不同实体的处理方式,先比较实体后再比较是否具备相似的邻居。在此基础上,对于任何一段名称、描述和属性的向量嵌入,作者对每对邻居或属性采用交互的方式而不是通过聚合的方式进行处理。通过这种方式,作者可以在匹配的邻居之间获取细粒度精确的语义匹配信息以及消除不相似的邻居带来的负面影响,如图1所示。
3 问题定义
定义: 知识图谱:将记作为
,这里
属于
,
属于
,
属于
,
属于
分别表示实体、关系、属性名和属性值。
记做实体
的
跳邻居,其中第
个邻居包含关系
和对应的邻居实体
。
,记做实体
的属性,这里第
个属性包含一个属性名称
和对应的属性值
,
表示不考虑跳数的实体
的所有邻居。
和
分别表示
和
的元素个数。
问题 : 知识图谱对齐:给两个图谱、
和一个已经对齐的实体对
,作者的目标是对不同实体学习一个相似度排序函数
,基于这个相似度函数,作者按相似度从高到低对
进行排序。
4 BERT-INT模型
BERT-INT模型的整体框架如图2所示,它将BERT模型作为基础的表示单元对实体的名称、描述、属性和属性值进行嵌入,交互模型建立在由Bert产生的embedding之上。交互模型更进一步分为名称/描述交互视图、邻居交互视图和属性交互视图。之后采用统一的二元整合函数从邻居交互视图和属性交互视图抽取特征进一步评估实体匹配的得分。另外,为了理解邻居交互视图,作者对邻居实体之间的交互和对应的多跳的邻居关系也进行了建模。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2019
2019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









