







核心概要
技术方向:
- NameServer高可用、
- 同步刷盘、
- Dledger主从架构、
- 事务消息
- 同步消费
业务方向:
- 可用性校验
- 定时补偿机制
- 降级方案
NameServer高可用
和kafka不一样,RocketMQ中并没有 master 选举功能,在RocketMQ集群中,1台机器只能要么是Master,要么是Slave,这个在初始的机器配置里面,就定死了的。
不会像kafka那样存在master动态选举,所以通过配置多个master节点来保证rocketMQ的高可 用。
多个 master 节点组成集群,单个 master 节点宕机或者重启对应用没有影响
优点:高可用,所有模式中性能最高
缺点:可能会有少量消息丢失(配置相关),单台机器重启或宕机期间,该机器下未被消费的消息在机器恢复前不可订阅,影响消息实时性
注意:使用同步刷盘可以保证消息不丢失,同时 Topic 相对应的 queue 应该分布在集群中各个 master节点,而不是只在某各 master 节点上,否则,该节点宕机会对订阅该 topic 的应用造成影响。
多 master 模式
多个 master 节点组成集群,单个 master 节点宕机或者重启对应用没有影响。
优点:所有模式中性能最高
缺点:单个 master 节点宕机期间,未被消费的消息在节点恢复之前不可用,消息的实时性就受到影响。
注意:使用同步刷盘可以保证消息不丢失,同时 Topic 相对应的 queue 应该分布在集群中各个master 节点,而不是只在某各 master 节点上,否则,该节点宕机会对订阅该 topic 的应用造成影响。
多 master 多 slave 异步复制模式
在多 master 模式的基础上,每个 master 节点都有至少一个对应的 slave。 master 节点可读可写,但是 slave只能读不能写,类似于 mysql 的主备模式。
优点: 在 master 宕机时,消费者可以从 slave 读取消息,消息的实时性不会受影响,性能几乎和多 master 一样。
缺点:使用异步复制的同步方式有可能会有消息丢失的问题。
多 master 多 slave 同步双写模式
同多 master 多 slave 异步复制模式类似,区别在于 master 和 slave 之间的数据同步方式。
优点:同步双写的同步模式能保证数据不丢失。
缺点:发送单个消息 RT 会略长,性能相比异步复制低10%左右。刷盘策略:同步刷盘和异步刷盘(指的是节点自身数据是同步还是异步存储)
注意:要保证数据可靠,需采用同步刷盘和同步双写的方式,但性能会较其他方式低。
同步刷盘
刷盘策略指的是broker中消息的落盘方式,即消息发送到broker内存后消息持久化到磁盘的方式。分为 同步刷盘与异步刷盘:
同步刷盘:当消息持久化到broker的磁盘后才算是消息写入成功。
异步刷盘:当消息写入到broker的内存后即表示消息写入成功,无需等待消息持久化到磁盘。异步刷盘策略会降低系统的写入延迟,RT变小,提高了系统的吞吐量 。消息写入到Broker的内存,一般是写入到了PageCache。对于异步刷盘策略,消息会写入到PageCache后立即返回成功ACK。但并不会立即做落盘操 作,而是当PageCache到达一定量时会自动进行落盘
所以,我们可以简单的把RocketMQ的刷盘方式 flushDiskType配置成同步刷盘就可以保证消息在刷盘过程中不会丢失了。
Dledger主从架构
Dledger的文件同步
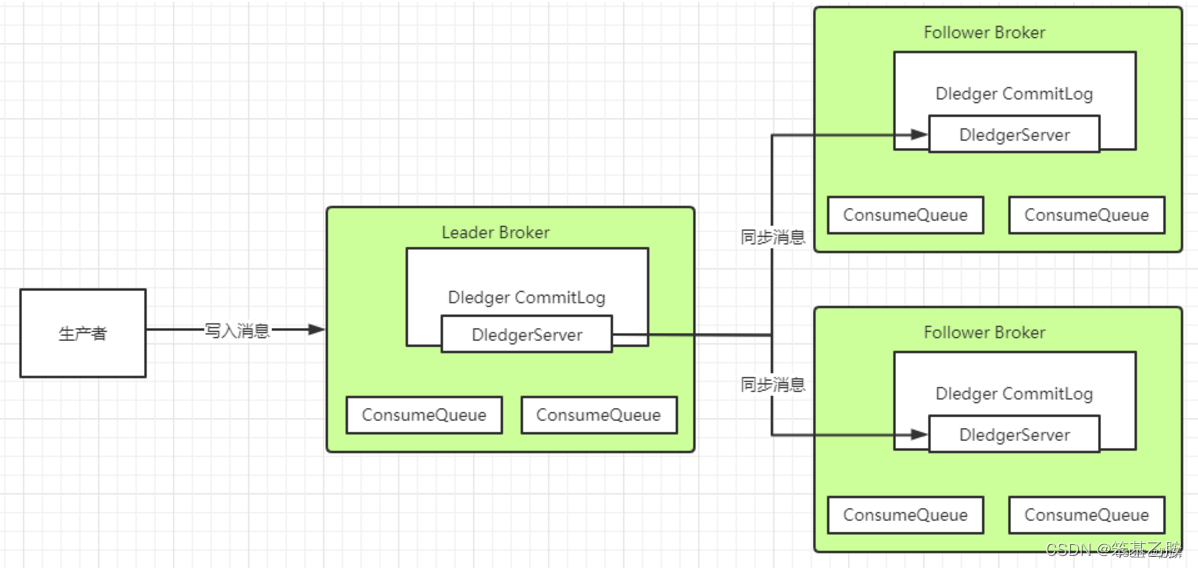
在使用Dledger技术搭建的RocketMQ集群中,Dledger会通过两阶段提交的方式保证文件在主从之间成功同步。
Leader Broker上的Dledger收到一条数据后,会标记为uncommitted状态,然后他通过自己的DledgerServer组件把这个uncommitted数据发给Follower Broker的DledgerServer组件。
接着Follower Broker的DledgerServer收到uncommitted消息之后,必须返回一个ack给Leader Broker的Dledger。然后如果Leader Broker收到超过半数的Follower Broker返回的ack之后,就会把消息标记为committed状态。
最后, Leader Broker上的DledgerServer就会发送committed消息给Follower Broker上的DledgerServer,让他们把消息也标记为committed状态。这样,就基于Raft协议完成了两阶段的数据同步。
事务消息
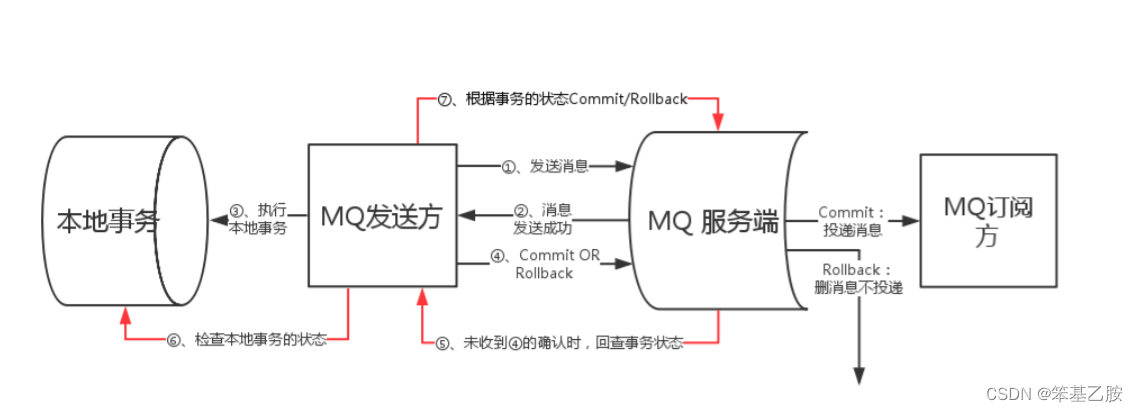
这张图说明了事务消息的大致方案,分为两个逻辑:正常事务消息的发送及提交、事务消息的补偿流程
事务消息发送及提交:
发送消息(half消息)
服务端响应消息写入结果
根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
根据本地事务状态执行Commit或者Rollback(Commit操作生成消息索引,消息对消费者可见)
补偿流程:
对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”
Producer收到回查消息,检查回查消息对应的本地事务的状态
根据本地事务状态,重新Commit或者Rollback
补偿阶段用于解决消息Commit或者Rollback发生超时或者失败的情况。
同步消费
参考我个人的博客:
ocketMQ工作原理之消息的消费
正常情况下,消费者端都是需要先处理本地事务,然后再给MQ一个ACK响应,这时MQ就会修改Offset,将消息标记为已消费,从而不再往其他消费者推送消息。所以在Broker的这种重新推送机制下,消息是不会在传输过程中丢失的。但是也会有下面这种情况会造成服务端消息丢失。
比如下面的代码示例,接收到MQ的消息后,我们开启一个新的线程处理业务逻辑,并异步返回一个成功标记。这时就会出现业务逻辑处理失败,但是由于成功的消息已经返回,此时就出现了数据不一致的问题。
这种异步消费的方式,就有可能造成消息状态返回后消费者本地业务逻辑处理失败造成消息丢失的可能。所以使用同步消费机制,就能避免该阶段丢消息的情况
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("please_rename_unique_group_name_4");
consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs,
ConsumeConcurrentlyContext context) {
new Thread(){
public void run(){
//处理业务逻辑
System.out.printf("%s Receive New Messages: %s %n", Thread.currentThread().getName(), msgs);
}
};
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
});
可用性校验
对于核心业务的MQ可以在发送核心数据之前发送一个half消息,校验一下当前MQ是否可用。
为什么要发送half消息?
half消息是在订单系统进行下单操作前发送,并且对下游服务的消费者是不可见的(放入对应的half消息对应的RMQ_SYS_TRANS_HALF_TOPIC队列)。这个消息的作用更多的体现在确认RocketMQ的服务是否正常。相当于嗅探下RocketMQ服务是否正常,并且通知RocketMQ。
如果没有half消息这个流程,那我们通常是会在订单系统中先完成下单,再发送消息给MQ。这时候写入消息到MQ如果失败就会出现数据不一致的问题。而half消息如果写入失败,我们就可以认为MQ的服务是有问题的,这时,就不能通知下游服务了。我们可以在下单时给订单一个状态标记,然后等待MQ服务正常后再进行补偿操作,等MQ服务正常后重新下单通知下游服务。
定时补偿机制
如果校验未通过怎么办?
可以考虑将要发送的MQ数据落库到临时表进行标记,再通过定时补偿机制处理。
比如起一个定时任务(JobPushOrder),扫码临时表数据,重复推送数据
如果MQ长时间处于异常状态怎么办?
可以在配置中心配置一个是否开启推送数据的定时任务,就上面的JobPushOrder,默认isPush:true
在另外开启一个定时任务,比如10分钟执行一次,检查MQ的状态,如果异常就修改isPush:false,然后
JobPushOrder中通过判断标记是否继续推送数据。
如果异常也可以及时的推送报警信息到运维或者开发人员
降级方案
NameServer挂了如何保证消息不丢失,这个是RocketMQ特有的问题
NameServer在RocketMQ中,是扮演的一个路由中心的角色,提供到Broker的路由功能。但是其实路由中心这样的功能,在所有的MQ中都是需要的。kafka是用zookeeper和一个作为Controller的Broker一起来提供路由服务,整个功能是相当复杂的。而RabbitMQ是由每一个Broker来提供路由服务。而只有RocketMQ把这个路由中心单独抽取了出来,并独立部署。
NameServer集群中任意多的节点挂掉,都不会影响他提供的路由功能。那如果集群中所有的NameServer节点都挂了呢?
在这种情况下,RocketMQ相当于整个服务都不可用了,那他本身肯定无法给我们保证消息不丢失了。我们只能自己设计一个降级方案来处理这个问题了。例如在订单系统中,如果多次尝试发送RocketMQ不成功,那就只能另外找给地方(Redis、文件或者内存等)把订单消息缓存下来,然后起一个线程定时的扫描这些失败的订单消息,尝试往RocketMQ发送。这样等RocketMQ的服务恢复过来后,就能第一时间把这些消息重新发送出去。整个这套降级的机制,在大型互联网项目中,都是必须要有的。
















 2086
2086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











