







转自:http://blog.csdn.net/shanyongxu/article/details/51190820,本人学习受益匪浅,楼主把重点都标记出来了,请点击链接查看原文,尊重楼主大大版权。
中英文字符大小和文本边界问题
ASCII,UTF-8,Unicode编码下的中英文字符大小
当对字符串进行发送和接受时,编码方式很关键,服务端与客户端显然要采用相同的编码方式才行,否则一方的到的就是乱码.演示一下,看一下常见的编码格式下中英文字符的写法:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace ShowCode
{
class Program
{
static void Main(string[] args)
{
string[] strArray = { "b","abcd","乙","甲乙丙丁"};
byte[] buffer;
string mode, back;
foreach (string str in strArray)
{
for (int i = 0; i < 3; i++)
{
if (i==0)
{
buffer = Encoding.ASCII.GetBytes(str);
back = Encoding.ASCII.GetString(buffer,0,buffer.Length);
mode="ASCII";
}
else if (i==1)
{
buffer = Encoding.UTF8.GetBytes(str);
back = Encoding.UTF8.GetString(buffer,0,buffer.Length);
mode = "UTF-8";
}
else
{
buffer = Encoding.Unicode.GetBytes(str);
back = Encoding.Unicode.GetString(buffer,0,buffer.Length);
mode = "Unicode";
}
Console.WriteLine("Mode: {0},String: {1},Buffer.Length:{2}",mode,str,buffer.Length);
Console.Write("Buffer: ");
for (int j = 0; j < buffer.Length; j++)
{
Console.Write(buffer[j]+" ");
}
Console.WriteLine("\nRetrived: {0}\n",back);
}
}
}
}
}
关于代码的输出,看一下:
Mode: ASCII,String: b,Buffer.Length:1
Buffer: 98
Retrived: b
Mode: UTF-8,String: b,Buffer.Length:1
Buffer: 98
Retrived: b
Mode: Unicode,String: b,Buffer.Length:2
Buffer: 98 0
Retrived: b
Mode: ASCII,String: abcd,Buffer.Length:4
Buffer: 97 98 99 100
Retrived: abcd
Mode: UTF-8,String: abcd,Buffer.Length:4
Buffer: 97 98 99 100
Retrived: abcd
Mode: Unicode,String: abcd,Buffer.Length:8
Buffer: 97 0 98 0 99 0 100 0
Retrived: abcd
Mode: ASCII,String: 乙,Buffer.Length:1
Buffer: 63
Retrived: ?
Mode: UTF-8,String: 乙,Buffer.Length:3
Buffer: 228 185 153
Retrived: 乙
Mode: Unicode,String: 乙,Buffer.Length:2
Buffer: 89 78
Retrived: 乙
Mode: ASCII,String: 甲乙丙丁,Buffer.Length:4
Buffer: 63 63 63 63
Retrived: ????
Mode: UTF-8,String: 甲乙丙丁,Buffer.Length:12
Buffer: 231 148 178 228 185 153 228 184 153 228 184 129
Retrived: 甲乙丙丁
Mode: Unicode,String: 甲乙丙丁,Buffer.Length:8
Buffer: 50 117 89 78 25 78 1 78
Retrived: 甲乙丙丁
这样可以得出几个结论:
1.ASCII不能保存中文;
2.UTF-8和Unicode都是边长编码.在对ASCII字符编码时,UTF-8更省空间,只占一个字节,与ASCII编码方式和长度相同;Unicode在对ASCII字符编码时,占用2个字节,且第二个字节补零;
3.UTF8在对中文编码是需要占用3字节;Unicode对中文编码只需要2个字节.
不知道你注意到没有,咱们前面客户端-服务端采用的编码方式都是Unicode,这样才能保证两边的字符都能正确显示.
文本边界问题
除了字符编码问题之外,还存在一个问题:当客户端分两次向流中写入字符串时,我们主观上将这两次写入视为两次数据发送;然而服务器有可能将这两次合起来作为一条数据发送,这在两个请求间隔时间比较短的情况下尤其如此.同样,也有可能客户端只进行了一次数据发送,但是服务端分成了两个请求进行处理.
假设在客户端发送两条”Welcome to SDUT.COM!”,则数据到达服务端时可能出现三种情况.
第一种是理想的情况,此时两条消息被视为两个独立请求由服务端完整接受.
第二种是一条消息被当做两条消息接受了.
第三种是两条消息合并为一条了.
出现这种情况的原因是,当通过NetworkStream写入数据时,数据并没有立即发送远程主机,而是保存在了TCP缓存(TCP Buffer)中,经过一段时间之后才发送:
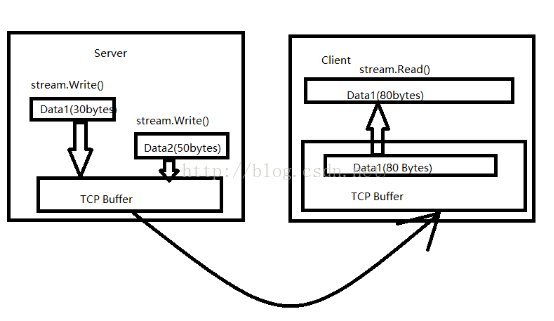
对于传输二进制文件来说,这不是事,但是对于文本文件来说,就需要确定两次发送文本的边界,否则就可能给对方带来困惑.先来模拟一下这种情况,对客户端进行修改,不通过用户输入,而是通过一个for循环连续发送三条数据过去,这样发送数据的间隔更短.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net;
using System.Net.Sockets;
using System.Text;
using System.Threading.Tasks;
namespace Client
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("CLient is running...");
TcpClient client;
const int BufferSize = 8192;
try
{
client = new TcpClient();
//与服务器建立连接
client.Connect(IPAddress.Parse("192.168.3.19"), 9322);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
return;
}
//打印连接到的服务端信息
Console.WriteLine("Server Connected! Local: {0} --> Server: {1}", client.Client.LocalEndPoint, client.Client.RemoteEndPoint);
NetworkStream streamToServer = client.GetStream();
string msg;
Console.Write("Sent:");
msg = "Welcome to SDUT.COM!";
for (int i = 0; i < 3; i++)
{
byte[] buffer = Encoding.Unicode.GetBytes(msg);//获得缓存
try
{
streamToServer.Write(buffer, 0, buffer.Length);
Console.WriteLine("Sent: {0}", msg);
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
break;
}
}
streamToServer.Dispose();
client.Close();
}
}
}
运行服务器,再运行客户端,可能会出现意想不到的情况,为啥呢?大家回想一下HTTP协议,在实际的请求和应答之前包含了HTTP头,其中是一些与请求相关的信息,比如浏览器信息,Cookie信息,请求方式信息等.我们也可以订立自己的协议来解决这个问题,比如,对于上面的情况,我们就可以这么定义一个协议:
[length=XXX]
其中XXX是实际发送的字符串长度(注意不是字节数组buffer的长度),因此对于上面的请求,实际发送的数据为”[length=20]Welcome to SDUT.COM!”.而服务端接受字符串之后,首先读取这个”元数据”的内容,然后再根据”元数据”内容来读取实际的数据.”元数据”内容可能有下面这样两种情况:
1.”[” ”]”中括号是完整的,可以读取到length的字节数.接着根据这个数值与后面的字符串长度相比,如果相等,这说明发送了一条完整数据;多了说明接受的字节数多了,取出合适的长度,将剩余的进行缓存;少了说明接收的不够,将受到的字节进行一个缓存,等待下次请求,然后将两条信息合并.
2.“[” “]”中括号本身就不完整,此时读不到length的值,因为中括号里的内容被截断了,所以将读到的数据进行缓存,等待读取下次发送来的数据,然后将两次数据合并之后再按上面的方式进行处理.
看一个案例:
private string[] GetActualString(string input, List<string>outputList)
{
if (outputList==null)
{
outputList = new List<string>();
}
if (!string.IsNullOrEmpty(temp))
{
input = temp + input;
}
string output = "";
string pattrern = @"(?<=^\[length=)(\d+)(?=])"; //[length= 前加\去掉[的语法作用,让他作为一个普通的字符串
int length;
if (Regex.IsMatch(input, pattrern))
{
Match m = Regex.Match(input, pattrern);
//获取消息字符串实际应用的长度
length = Convert.ToInt32(m.Groups[0].Value);
//获取需要进行截取的位置
int startIndex = input.IndexOf(']')+1;
//获取从此位置开始后所有字符的长度
output = input.Substring(startIndex);
if (output.Length==length)
{
//如果output的长度与消息字符串的应用长度相等
//说明刚好是完整的一条消息
outputList.Add(output);
temp = "";
}
else if (output.Length<length)
{
//如果之后的长度小于应用的长度
//说明没有发完整,则应将整条信息,包括元数据,全部缓存
//与下一条数据合并起来再进行处理
temp = input;
//此时程序应该退出,因为需要等待下一条数据到来才能继续处理
}
else if (output.Length>length)
{
/*
如果之后的长度大于应用的长度
说明消息发完整了,但是有多余的数据
多余的数据可能是截断消息,也可能是多条完整消息.
*/
//截取字符串
output = output.Substring(0,length);
outputList.Add(output);
temp = "";
//缩短intput的长度
input = input.Substring(startIndex+length);
//递归调用
GetActualString(input,outputList);
}
}
else//说明"[","]"就不完整
{
temp = input;
}
return outputList.ToArray();
} 正则表达式语法可查阅:正则表达式;
?<=pattern :非获取匹配,反向肯定预查,与正向肯定预查类似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。
(?=pattern)非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。
预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
所以代码中 @"(?<=^\[length=)(\d+)(?=)" 能匹配前面为[length=且后面为]的1个或多个数字,这样写可以得到这个数字。
这个方法接受一个满足协议格式要求的输入字符串,然后返回一个数组,这是因为如果出现多次请求合并成一个发送过来的数据,那么就将他们全部返回.随后为了简单起见,在这个类中添加了一个静态的Test()方法和PrintOutput()帮主方法,进行了一个简单的测试,注意这里直接输入了length=13,这是提前计算好的.
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Text.RegularExpressions;
using System.Threading.Tasks;
namespace ShowCode
{
public class RequestHandler
{
private string temp = string.Empty;
public string[] GetActualString(string input)
{
return GetActualString(input,null);
}
private string[] GetActualString(string input, List<string>outputList)
{
if (outputList==null)
{
outputList = new List<string>();
}
if (!string.IsNullOrEmpty(temp))
{
input = temp + input;
}
string output = "";
string pattrern = @"(?<=^\[length=)(\d+)(?=])";
int length;
if (Regex.IsMatch(input, pattrern))
{
Match m = Regex.Match(input, pattrern);
//获取消息字符串实际应用的长度
length = Convert.ToInt32(m.Groups[0].Value);
//获取需要进行截取的位置
int startIndex = input.IndexOf(']')+1;
//获取从此位置开始后所有字符的长度
output = input.Substring(startIndex);
if (output.Length==length)
{
//如果output的长度与消息字符串的应用长度相等
//说明刚好是完整的一条消息
outputList.Add(output);
temp = "";
}
else if (output.Length<length)
{
//如果之后的长度小于应用的长度
//说明没有发完整,则应将整条信息,包括元数据,全部缓存
//与下一条数据合并起来再进行处理
temp = input;
//此时程序应该退出,因为需要等待下一条数据到来才能继续处理
}
else if (output.Length>length)
{
/*
如果之后的长度大于应用的长度
说明消息发完整了,但是有多余的数据
多余的数据可能是截断消息,也可能是多条完整消息.
*/
//截取字符串
output = output.Substring(0,length);
outputList.Add(output);
temp = "";
//缩短intput的长度
input = input.Substring(startIndex+length);
//递归调用
GetActualString(input,outputList);
}
}
else//说明"[","]"就不完整
{
temp = input;
}
return outputList.ToArray();
}
public static void Test()
{
RequestHandler handler = new RequestHandler();
string input;
//第一种情况:一条消息完整发送
input = "[length=13]欢迎各位来到山东理工大学!";
handler.PrintOutput(input);
//第二种情况:两条完整消息一次发送
input = "欢迎各位来到山东理工大学!";
input = string.Format("[length=13]{0}[length=13]{0}",input);
handler.PrintOutput(input);
//第三种情况测试A:两条消息不完整发送
input = "[length=13]欢迎各位来到山东理工大学![length=13]欢迎各位";
handler.PrintOutput(input);
input = "来到山东理工大学!";
handler.PrintOutput(input);
//第三种情况测试B:两条消息不完整发送
input = "[length=13]欢迎各位来到山东";
handler.PrintOutput(input);
input = "理工大学![length=13]欢迎各位来到山东理工大学!";
handler.PrintOutput(input);
//第四种情况:元数据不完整
input = "[leng";
handler.PrintOutput(input);//不会有输出
input = "th=13]欢迎各位来到山东理工大学!";
handler.PrintOutput(input);
}
private void PrintOutput(string input)
{
Console.WriteLine("输入: "+input);
string[] outputArray = GetActualString(input);
foreach (string output in outputArray)
{
Console.WriteLine("输出: "+output);
}
Console.WriteLine();
}
}
}
测试代码如下:
static void Main(string[] args)
{
RequestHandler.Test();
}
运行程序:
输入: [length=13]欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输入: [length=13]欢迎各位来到山东理工大学![length=13]欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输入: [length=13]欢迎各位来到山东理工大学![length=13]欢迎各位
输出: 欢迎各位来到山东理工大学!
输入: 来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输入: [length=13]欢迎各位来到山东
输入: 理工大学![length=13]欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
输入: [leng
输入: th=13]欢迎各位来到山东理工大学!
输出: 欢迎各位来到山东理工大学!
完美!!!接下来就让我们看看使用异步方式实现对多客户端多请求的处理.















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









