







图文匹配以及图像的QA是图像与文本多模态融合,是计算机视觉与自然语言处理的交叉。
图文匹配:将图像与文本都映射到一个相同的语义空间,然后通过距离对他们的相似度进行判断。
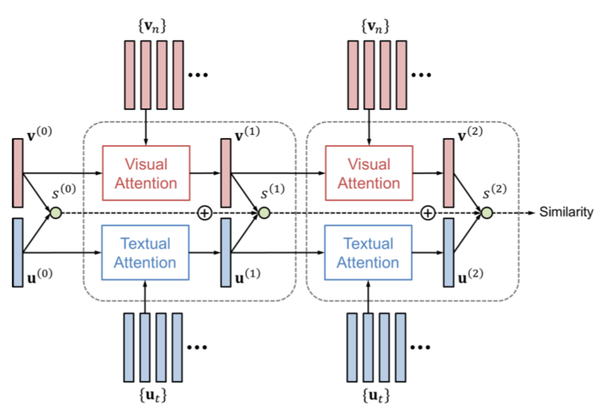
图文匹配问题与VQA最大的不同就是,需要比对两种特征之间的距离。将文本和图像分别做attention,DAN计算每一步attention后的文本和图像向量相似度累加得到similarity.
VQA:给定一张图像和一个关于该图像内容的文字问题,视觉问答旨在从若干候选文字回答中选出正确的答案,本质上是一个分类问题,其核心思想是让图像的Attention的位置随着问题进行变化。
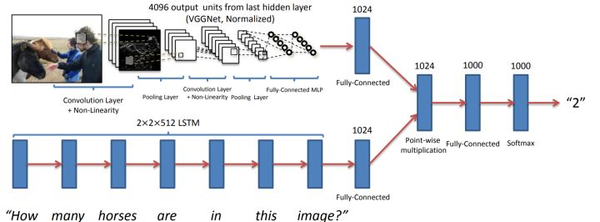
使用CNN从图像中提取图像特征,用RNN从文字问题中提取文本特征,融合视觉和文本特征,最后通过全连接层进行分类。该任务的关键是如何融合这两个模态的特征。 直接融合的方法几种:视觉和文本特征向量拼接、逐元素相加或相乘、内积、外积。
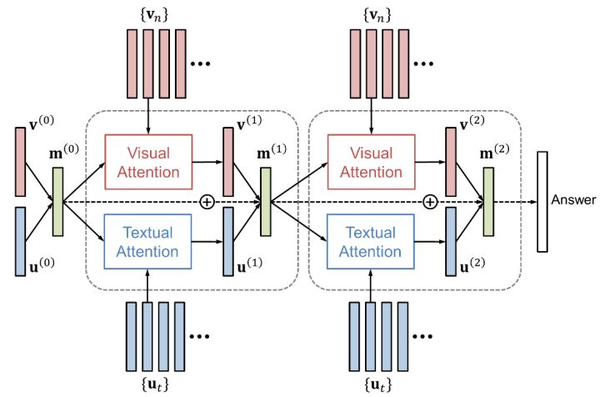
注意力机制包括视觉注意力(“看哪里”)和文本注意力(“关注哪个词”)两者。DAN将视觉和文本的注意力结果映射到一个相同的空间,并据此同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3068
3068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









