







卷积神经网络目前可以说是家喻户晓了,但对于想我这样的新手应该怎么快速的入门呢?
作为萌新,我也有问题三连:
- 1、卷积神经网络(CNN)和神经网络有什么关系?
- 2、卷积神经网络有哪些操作步骤呢(内部结构)?
- 3、能不能整个例子看看效果呀?
下面就借着回答上面的三个问题的时机,来揭开卷积神经网络的面纱。
1、卷积神经网络(CNN)和神经网络有什么关系?
先来看传统的神经网络
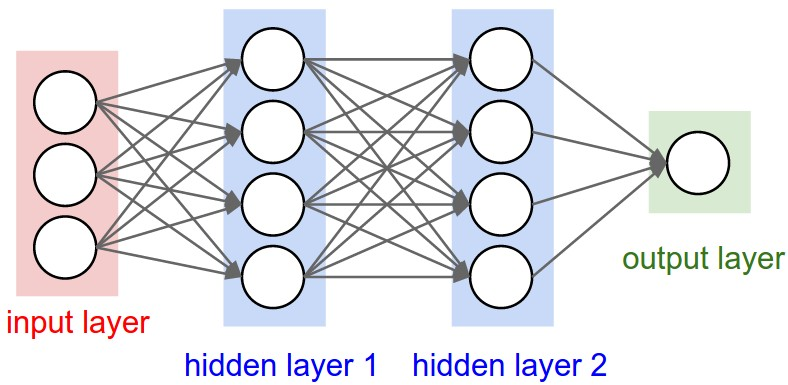
这个神经网络还是熟悉的神经网络,包含两个隐层。
下面就来看卷积神经网络

不难看出,卷积神经网络是在三维上操作的,这是因为卷积神经网络利用输入是图片的特点,把神经元设计成三个维度 : width,height,depth w i d t h , h e i g h t , d e p t h ( 注意这个depth不是神经网络的深度,而是用来描述神经元的) 。
比如输入的图片大小是 32×32×3(rgb) 32 × 32 × 3 ( r g b ) ,那么输入神经元就也具有 32×32×3 32 × 32 × 3 的维度。
可以先直观的这样理解卷积神经网络和传统神经网络的区别。
2、卷积神经网络有哪些操作步骤呢(内部结构)?
卷积神经网络一般可以分为以下几层:
1)、卷积层(Convolutional layer)
每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。
卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
2)、线性整流层(Rectified Linear Units layer, ReLU layer)
这一层神经的活性化函数(Activation function)使用线性整流(Rectified Linear Units, ReLU) f(x)=max(0,x) f ( x ) = m a x ( 0 , x ) 。
3)、池化层(Pooling layer)
通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
4)、全连接层( Fully-Connected layer)
把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
下图是个卷积神经网络的例子:
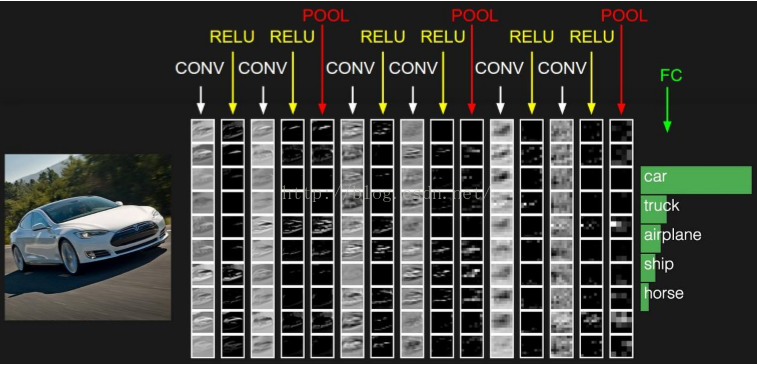
下面就开始介绍卷积神经网络的内部主要结构(卷积层,池化层)。
1)、卷积层(Convolutional layer)
我们首先介绍卷积层的几个特性(局部感知,共享权值),然后就看看到底什么是卷积以及它的作用。
局部感知
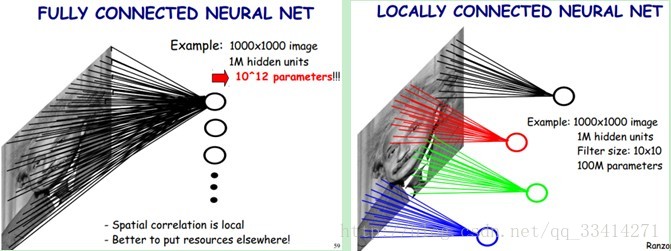
如上图所示,可以看出左图是“全感知”方式,每个像素都要输入同时输入到一个神经元。右图是“局部感知”方式,每个神经元每次负责一个区域的感知任务。
因为两个相距很远的像素之间的关系并不大。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。
共享权值
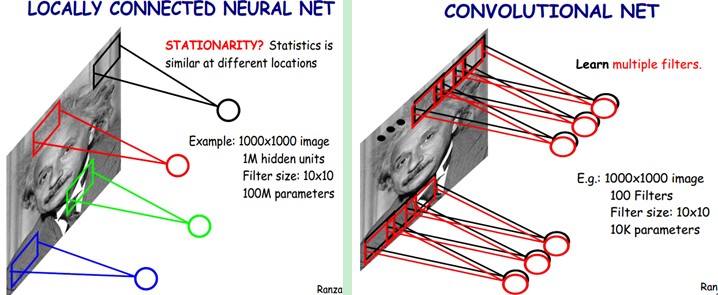
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。
在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
如果应用参数(权值)共享的话,实际上每一层计算的操作就是输入层和权重的卷积!这也就是卷积神经网络名字的由来。
卷积
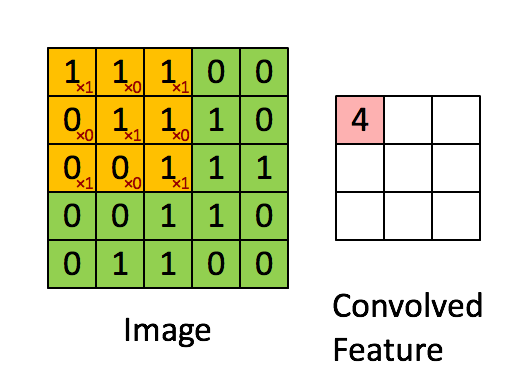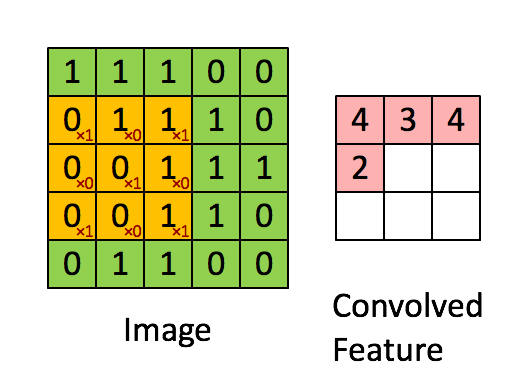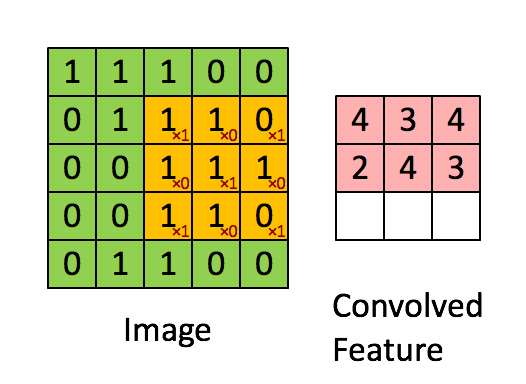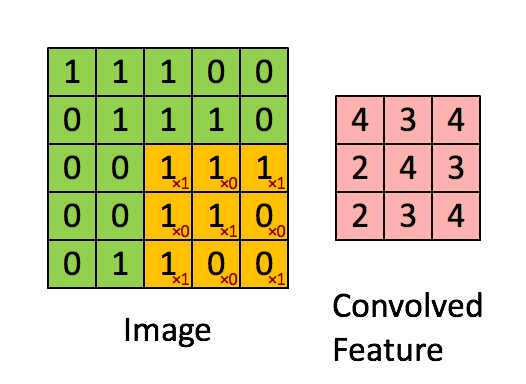
如上图就是一个取对角线元素的卷积方式。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
多卷积核
上面所述只有1个卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:
每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道:
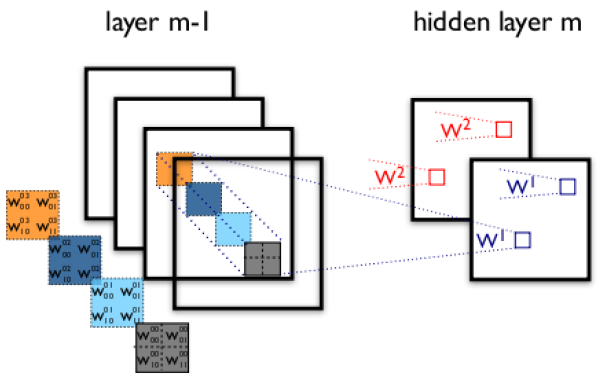
其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。
所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
2)、池化层(Pooling layer)
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。
例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。
学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
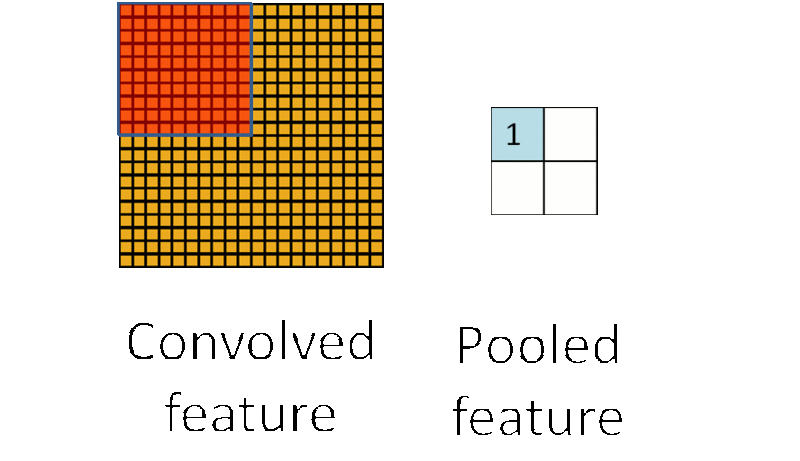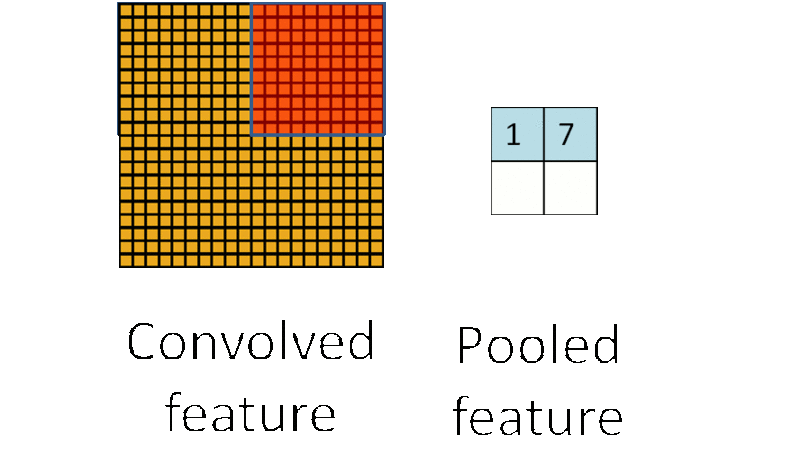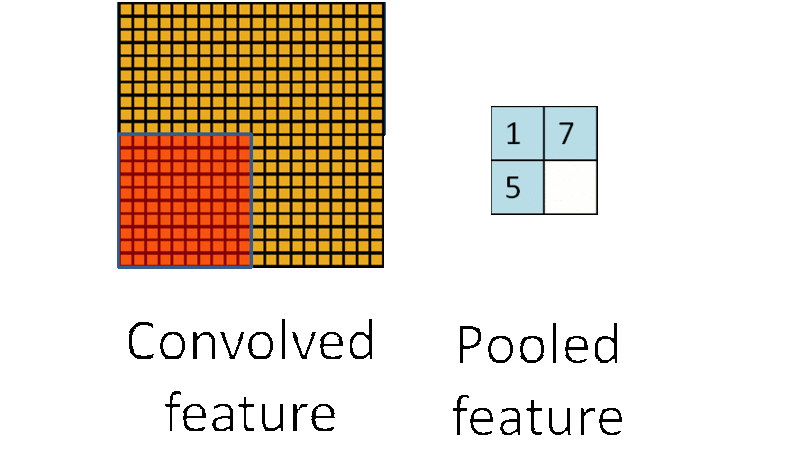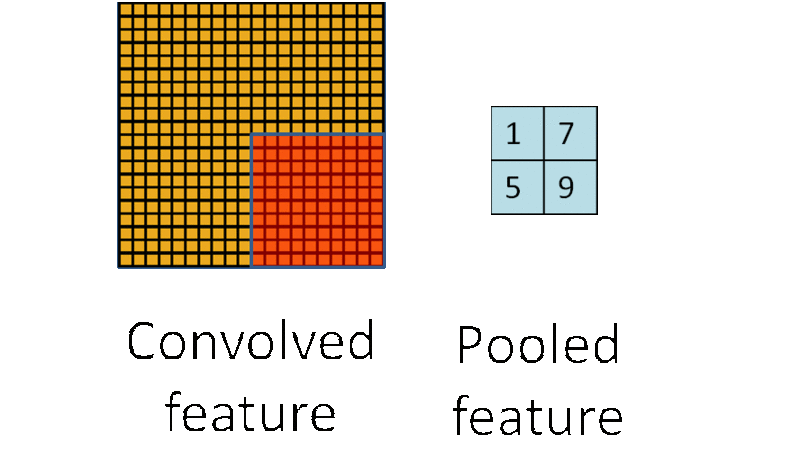
子采样有两种形式,一种是均值子采样(mean-pooling),一种是最大值子采样(max-pooling)。两种子采样看成特殊的卷积过程,如图下图所示:
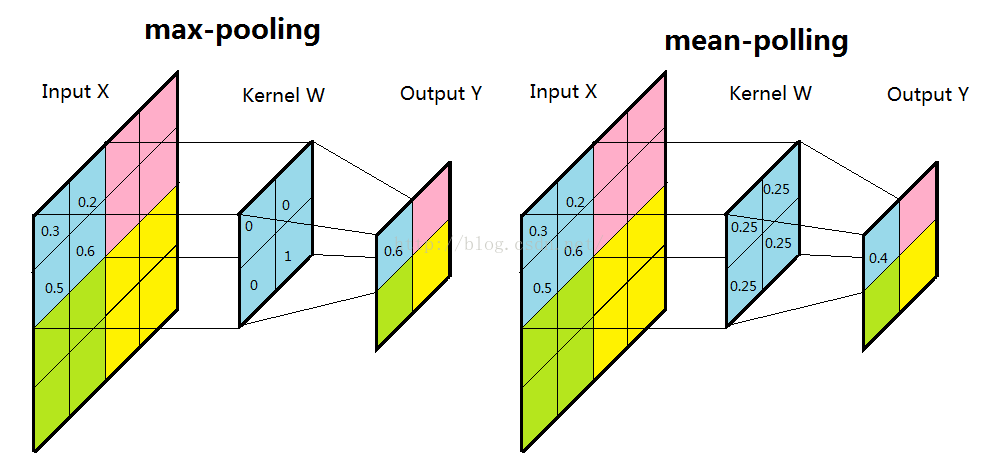
(1)均值子采样的卷积核中每个权重都是0.25,卷积核在原图inputX上的滑动的步长为2。均值子采样的效果相当于把原图模糊缩减至原来的1/4。
(2)最大值子采样的卷积核中各权重值中只有一个为1,其余均为0,卷积核中为1的位置对应被卷积核覆盖部分值最大的位置。卷积核在原图上的滑动步长为2。最大值子采样的效果是把原图缩减至原来的1/4,并保留每个2*2区域的最强输入。
3、能不能整个例子看看效果呀?
使用pytorch和MNIST手写数据进行训练
我们用一个 class 来建立 CNN 模型. 这个 CNN 整体流程是 卷积( Conv2d ) -> 激励函数( ReLU ) -> 池化, 向下采样 ( MaxPooling ) -> 再来一遍 -> 展平多维的卷积成的特征图 -> 接入全连接层 ( Linear ) -> 输出
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( #input shape (1,28,28)
nn.Conv2d(in_channels=1, #input height
out_channels=16, #n_filter
kernel_size=5, #filter size
stride=1, #filter step
padding=2 #con2d出来的图片大小不变
), #output shape (16,28,28)
nn.ReLU(),
nn.MaxPool2d(kernel_size=2) #2x2采样,output shape (16,14,14)
)
self.conv2 = nn.Sequential(nn.Conv2d(16, 32, 5, 1, 2), #output shape (32,7,7)
nn.ReLU(),
nn.MaxPool2d(2))
self.out = nn.Linear(32*7*7,10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) #flat (batch_size, 32*7*7)
output = self.out(x)
return output
完整代码:https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/401_CNN.py
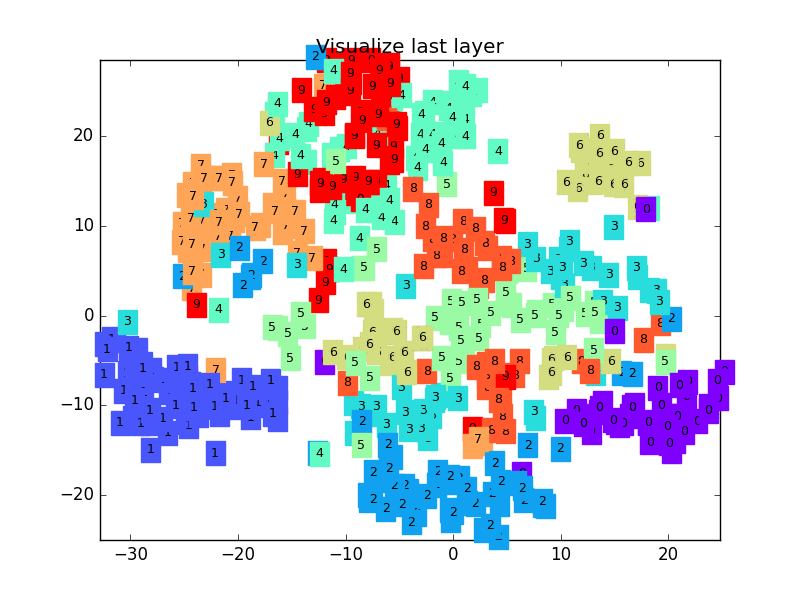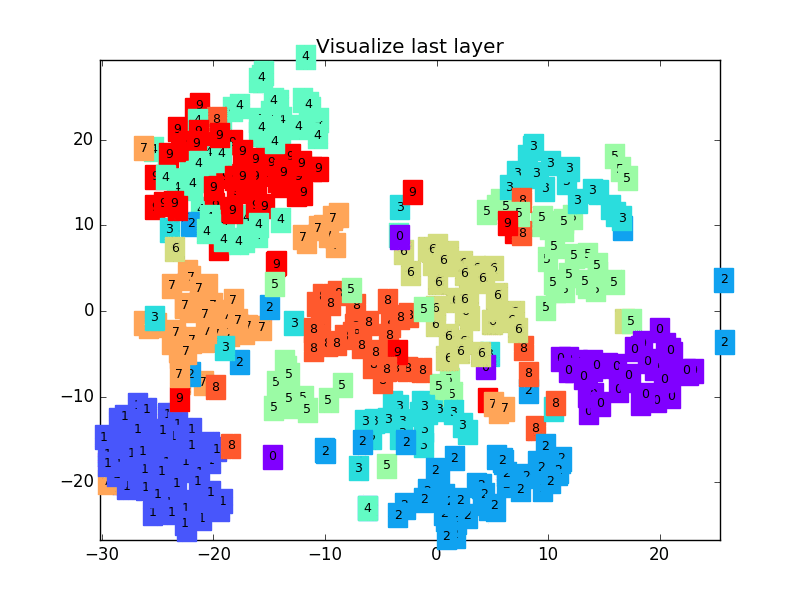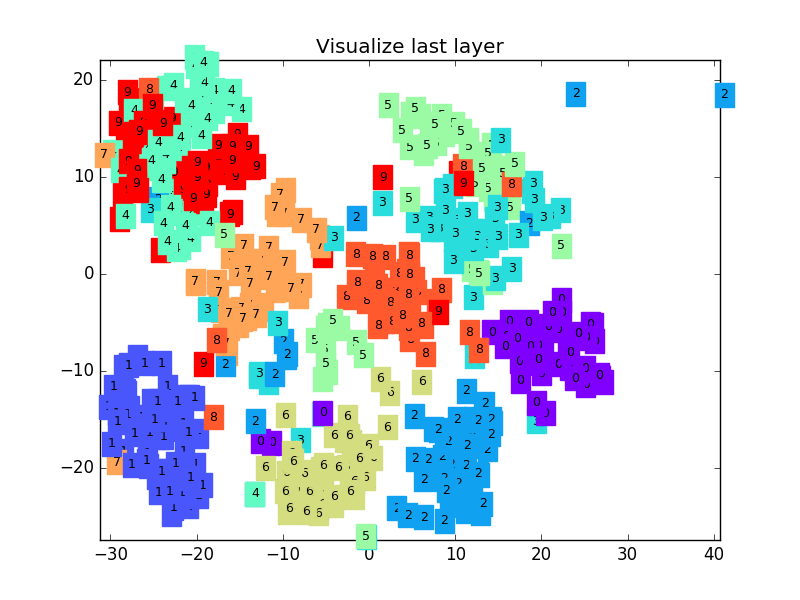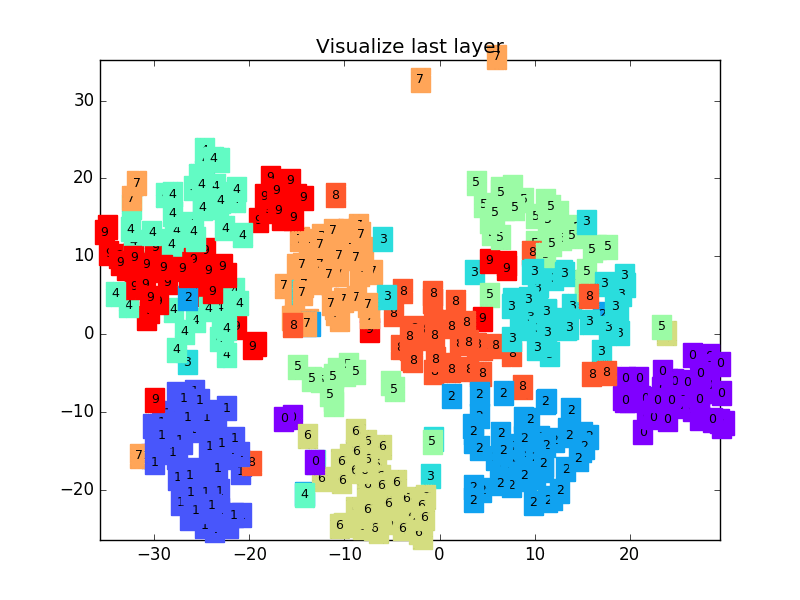
参考文献:
http://blog.csdn.net/yunpiao123456/article/details/52437794
http://blog.csdn.net/qq_25762497/article/details/51052861














 4026
4026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









