






00 文章基本信息

01 摘要
以前方法存在的问题:
- 以前的方法都是对certain的historical
check-ins进行学习,得到用户的访问模式,但是对于uncertain的用户historical
check-ins(比如模糊和不完整,具体原因为inaccuracy of indoor GPS devices and personal privacy)就不奏效了。
our contributions:
- 提出一套framework:interactive multi-task learning (iMTL) framework
- 具体而言是两个encoder和一个decoder: temporal-aware activity encoder、spatial-aware location preference encoder和task-specific decoder
1 Introduction
这一块内容主要是对recommend next precise individual POIs to users with uncertain check-ins这一问题/目标进行解释。
-
第一,什么是uncertain check-ins
简单而言,下图中虚线框collective POIs l4(包含l9、l10)、l5(包含l6、l7、l8)中的check-ins都属于uncertain check-ins。比如在l5中,已知用户在t3访问了collective POIs l5中的l5。但是,在多数情况下,由于室内GPS的定位精度问题,只能判断用户进入了区域collective POIs l5却并不能确定用户是访问了l5中的具体哪一个POI,这就是所谓的uncertain check-ins问题。
-
第二,如何进行precise POI precise prediction with uncertain check-ins
具体实现方法如下框架所示。

2 Related Work
2.1 Next POI Recommendation
对于Next POI recommandation问题,目前的方法主要分为两大类:只研究sequential activity patterns/sequential location patterns以及同时研究considering both activity and location transition patterns这两种方法。后者前者要进步一些,但是后者没有实现以下两点:
- well characterize the underlying activity over uncertain check-ins;
- exploit the spatial and temporal contexts in a fine-grained way;
2.2 Multi-Task Learning for Recommendation
Multi-Task Learning多任务学习可以提高模型的性能和模型泛化能力,与MCARNN提出的同时考虑用户的activity和location方法不同,本文提出的iMTL方法主要有以下三点创新:
- iMTL well represents users’uncertain activities via fuzzy
characterization strategy; - iMTL delicately explores the interplay between activity and location for next POI recommendation via an interactive manner;
- iMTL performs model training by deriving pair-wise ranking loss of activity and location to improve the prediction performance of uncertain activity;
3 Data Description and Analysis
首先声明一点,目前没有带有collective POIs的可用数据集。
然后经过本文的收集整理,newly-construct得到一种数据集,该种数据集具有以下特点:
- individual POIs, e.g., l 6 , l 7 , l 8 , are grouped into a collective POI l 5 as shown 本文图1;
- The original check-ins l 1 → l 2 → l 6 are converted to l 1 → l 2
→ l 5 ; - Each check-in is formed as (u, l, t, c, y, g), meaning that user u visited POI l at time t, where l is associated with category c and POI type y (y = 0 denotes individual POI; y = 1 refers to collective POI) as well as geocoded(地理标志,有经纬度坐标) by g (latitude and longitude of l);
- we remove users and POIs with fewer than 10 check-ins; each individual POI is assigned with rating derived from Yelp;
同时,本文在构造新数据集时得到一下三种现象/结论(有助于理解用户的uncertain check-ins这一概念):
Obs.1: temporal-aware activities
users’activities exhibit the strong temporal pattern.

Obs.2: choice-driven check-ins at collective POIs(collective POI中选择面驱动)
这条不太好理解。
如本博客的第一张图所示,当用户离开POI l2时,在距离用户方圆△d的范围内有三个POIs可供用户选择,为什么用户选择了l5(collective POI)而不是l3(individual POI)或l4(collective POI)呢?
这是因为同样选择c1这一类POI时,l5这一collective POI中可供选择的POI更多(l5中c1这一类activity对应4个POI),即用户的选择面更大。
这就是所谓的choice-driven check-ins at collective POIs(用户选择面驱动的用户check-in行为)。
下图所示为距离用户方圆Distance范围内,用户的选择(这里成为uncertain check-ins,也就是未知的/可能的用户选择)受POI规模(用户选择面)的大小的影响程度。通过图示我们可以看到,在方圆0.4km范围内,CTL、CAL和PHO三个数据集中的用户选择(uncertain check-ins)受POI规模(用户选择面)的影响程度都在75%以上。

Obs.3: rating-driven check-ins at cold start POIs(用户评论rating驱动)
users prefer individual POIs with higher ratings inside the collective POI.用户更倾向于访问collective POI中具有更多rating评论的individual POI(进一步解决了用户在访问collective POI时面临的uncertain check-ins问题)。
如下图中CLT数据集所示,在collective POI中,70%以上的用户check-ins行为发生在具有3条以上rating的individual POI。换言之,在一个collective POI中(有多个individual POI可供选择时),70%以上的用户选择访问具有三条以上rating的individual POI。

4 The Proposed Methodology
首先是一些定义:
- For each user, we split his historical check-in records, i.e.,(u, l,t, c, y, g), into check-in sequences by day(按照day把用户的check-ins records划分成check-in sequences),并且each record is sorted by timestamps。
- The i-th temporal-aware activity (category)(在这里要理解一下activity这个概念,这里的activity强调的用户所进行的活动的分类。比如,你连着逛了万达、苏宁、茂业天地等几个不同的POI(也就是商场),这在activity上都属于一个activity,都叫“逛街”,同样你连着去了几个不同的电影院,但是在activity上都叫做“看电影”,因此这几个POI都属于一类category)
sequence of user u is denoted by a set of activity tuples.也就是 Au,i = {A ut 1 , A ut 2 , . . .}, where A ut k = (c ut k , y t u k , tuk ), y t u k ∈ {0, 1}.

- The i-th spatial-aware location sequence of user u is denoted by a set of location tuples, i.e., L u,i = {L ut 1 , L ut 2 , . . .}, where L ut k = (l t u k , g t u k ).
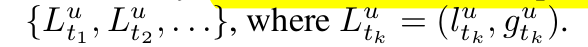
所以,整个问题的目标就是:Given A and L , our goal is to predict user u’s next activity c t n+1 and location l t n+1 at time t n+1 . If c t n+1 happens at a collective POI l t n+1 , we need to further recommend precise individual POIs inside l t n+1 given c t n+1 .
4.1 The iMTL Framework
The iMTL Framework主要由两大部分组成,a two-channel encoder和a task-specific decoder。
- The two-channel encoder, equipped with embedding, aggregation and recurrent layers, aims to capture the sequential correlations of activities and location preferences.
- the representations encoded by the recurrent layer are utilized in the task-specific decoder to interactively perform three (i.e., the next activity, POI type and POI) prediction tasks.
1.Temporal-aware Activity Encoder
先从整体上看Temporal-aware Activity Encoder的工作流程:

给定:Given an activity tuple A ut k = (c ut k , y t u k , t uk ) of user u。
如上图所示,Temporal-aware Activity Encoder的基本流程是:
-
先是准备工作,通过模糊分类fuzzy characterization得到用户的Cut k(用户所进行activity种类);

第一种情况,y t u k = 1,此时对应的POI为collective POI,此时c ut k为uncertain
activity,需要通过模糊分类策略fuzzy characterization得到用户的c ut
k。具体方法是根据上一节中第二个原则(选择面驱动原则)对collective POI中不同的activity
category赋予不同的权重,category对应的POI多的cj其权重βi就大。(如下图所示)最终得到一个c ut k值。

第二种情况,y t u k = 0,此时对应的POI为individual POI,上式中的M就是1,cj是什么,则c ut k是什么。 -
然后第一步,分别得到c ut k、t uk和y t u k对应的Embedding;
-
第二步,通过aggregation得到统一的向量x ut k;

-
第三步,将x ut k扔进LSTM来infer the hidden state of user u’s activity at t k;

其中,LSTM(·) captures the sequential correlations of activities, and h
ut k−1 encodes the previous activity until t k−1。
2.Spatial-aware Location Preference Encoder
这一块比较容易,As a user’s check-in is generally affected by the distance between the current location and the next visiting one, the spatial-aware location preference encoder aims to capture sequential location correlations by considering spatial contexts.
跟Temporal-aware Activity Encoder的工作流程一致,如下图所示可分为以下三步:

-
第一步,分别得到l t k、和d t k对应的Embedding;
-
第二步,通过aggregation得到统一的向量x ut k;

-
第三步,将x ut k扔进LSTM来infer the hidden state of location at t k;

3.Task-specific Decoder

Task-specific Decoder的主要任务是基于上面两个encoder得到的h ut n和~h ut n进行三次预测( the next activity, POI type and location)。
(1)Activity Prediction with Auxiliary Task
主要工作是predict user u’s next activity in the dot-product way, and the probability of next possible activity c t n+1 at time t n+1 is calculated by:

另外还有一个工作是进行POI type的预测,The POI type prediction task is formulated as below:

(2)Location Prediction with Interactive Fashion
前提,用户的activity and 和 visit是相互影响的:
the next location check-in is affected by the activity(activity影响location)
本文提出的方法是:
we concatenate the latent representations learned in the two-channel encoder together with the predicted results of activity and POI type:

由此我们得到:the probability of u’s next POI l t n+1 at time t n+1 is(location):

简单总结:activity prediction task和location prediction task是相互帮助、相互学习的
In sum, the activity prediction task assists in the location prediction task, which in turn influences the activity representation learning during the model training with back-propagation, that is, they are interactively enhanced by each other.















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









