




 本文通过具体的编程实例,展示了如何使用神经网络解决复杂的数据分类问题。从数据预处理到模型搭建、训练及评估,全面介绍了神经网络的基本原理和技术要点。
本文通过具体的编程实例,展示了如何使用神经网络解决复杂的数据分类问题。从数据预处理到模型搭建、训练及评估,全面介绍了神经网络的基本原理和技术要点。
神经网络与深度学习(吴恩达)第三周编程
原coursera课程主页
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from testCases_v2 import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset,load_extra_datasets
np.random.seed(1)
noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()
datasets = {"noisy_circles": noisy_circles,
"noisy_moons": noisy_moons,
"blobs": blobs,
"gaussian_quantiles": gaussian_quantiles,
'no_structure':no_structure }
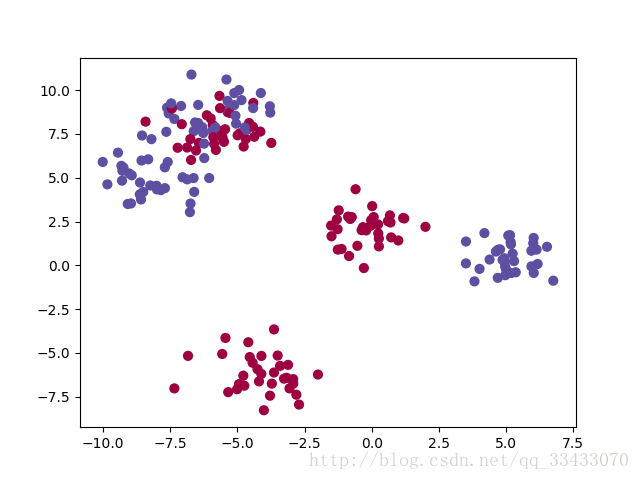
dataset='blobs'
X,Y=datasets[dataset]
X, Y = X.T, Y.reshape(1, Y.shape[0])
#X, Y = load_planar_dataset()
if dataset == "blobs":
Y = Y%2
plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral)
shape_X=X.shape
shape_Y=Y.shape
m=X.shape[1]
'''
clf=sklearn.linear_model.LogisticRegressionCV()
clf.fit(X.T,Y.T)
plot_decision_boundary(lambda x:clf.predict(x),X,Y)
plt.title('Logistic Regression')
LR_predictions=clf.predict(X.T)
print ('Accuracy of logistic regression: %d ' % float((np.dot(Y,LR_predictions) + np.dot(1-Y,1-LR_predictions))/float(Y.size)*100) +
'% ' + "(percentage of correctly labelled datapoints)")
'''
def lay_sizes(X,Y):
n_x=X.shape[0]
n_h=4
n_y=Y.shape[0]
return (n_x,n_h,n_y)
def initial_parameters(n_x,n_h,n_y):
np.random.seed(2)
W1=np.random.randn(n_h,n_x)*0.01
b1=np.zeros((n_h,1))
W2=np.random.randn(n_y,n_h)
b2=np.zeros((n_y,1))
parameters={'W1':W1,'b1':b1,'W2':W2,'b2':b2}
return parameters
def forward_propagation(X,parameters):
W1=parameters['W1']
b1=parameters['b1']
W2=parameters['W2']
b2=parameters['b2']
Z1=np.dot(W1,X)+b1
A1=np.tanh(Z1)
Z2=np.dot(W2,A1)+b2
A2=sigmoid(Z2)
cache={
'Z1':Z1,
'A1':A1,
'Z2':Z2,
'A2':A2
}
return A2,cache
def compute_cost(A2,Y,parameters):
m=Y.shape[1]
logprobs=np.multiply(np.log(A2),Y)+np.multiply(np.log(1-A2),(1-Y))
cost=-np.sum(logprobs)/m
cost=np.squeeze(cost)
return cost
def backward_propagation(parameters,cache,X,Y):
m=X.shape[1]
W1=parameters['W1']
W2=parameters['W2']
A2,cache=forward_propagation(X,parameters)
A1=cache['A1']
dZ2=A2-Y
dW2=np.dot(dZ2,A1.T)/m
db2=1/m*np.sum(dZ2,axis=1,keepdims=True)
dZ1=np.multiply(np.dot(W2.T,dZ2),(1-np.power(A1,2)))
dW1=1/m*np.dot(dZ1,X.T)
db1=1/m*np.sum(dZ1,axis=1,keepdims=True)
grads={
'dW1':dW1,
'db1':db1,
'dW2':dW2,
'db2':db2
}
return grads
def update_parameters(parameters,grads,learn_rate=1.2):
W1=parameters['W1']
b1=parameters['b1']
W2=parameters['W2']
b2=parameters['b2']
dW1=grads['dW1']
db1=grads['db1']
dW2=grads['dW2']
db2=grads['db2']
W1=W1-learn_rate*dW1
W2=W2-learn_rate*dW2
b1=b1-learn_rate*db1
b2=b2-learn_rate*db2
parameters={
'W1':W1,
'W2':W2,
'b1':b1,
'b2':b2
}
return parameters
def nn_model(X,Y,n_h,num_iterations=10000,print_cost=False):
np.random.seed(3)
n_x,tmp,n_y=lay_sizes(X,Y)
parameters=initial_parameters(n_x,n_h,n_y)
W1=parameters['W1']
b1=parameters['b1']
W2=parameters['W2']
b2=parameters['b2']
for i in range(0,num_iterations):
A2,cache=forward_propagation(X,parameters)
cost=compute_cost(A2,Y,parameters)
grads=backward_propagation(parameters,cache,X,Y)
parameters=update_parameters(parameters,grads,learn_rate=0.7)
if print_cost and i%1000==0:
print ("Cost after iteration %i: %f" %(i, cost))
return parameters
def predict(parameters,X):
A2,cache=forward_propagation(X,parameters)
predictions=np.around(A2)
return predictions
'''
parameters = nn_model(X, Y, n_h = 10, num_iterations = 10000, print_cost=True)
print(parameters)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('Accuracy: %d' % float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100) + '%')
'''
plt.figure(figsize=(32, 32))
hidden_layer_sizes = [1, 10, 20,30]
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(2, 2, i+1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations = 10000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y,predictions.T) + np.dot(1-Y,1-predictions.T))/float(Y.size)*100)
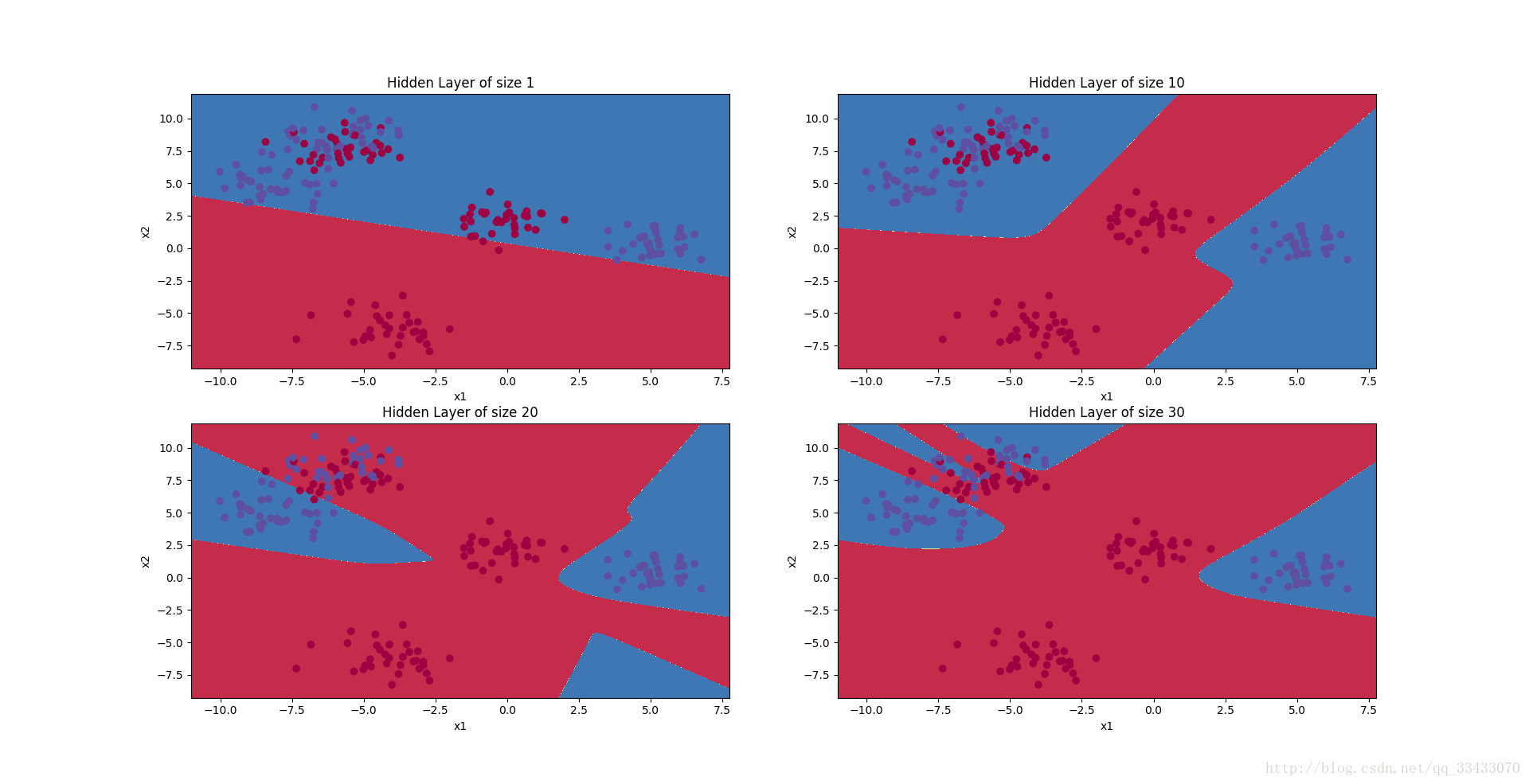
print ("Accuracy for {} hidden units: {} %".format(n_h, accuracy))
plt.show()测试结果:
原始数据
训练结果:
训练/测试数据集下载链接
注:我找到的testCases_v2发现与coursera上的测试数据并不一样,不过不影响结果。
程序中可设定hidden layer的个数不要设置的过大,可能把电脑跑死,我试过50可以100就不行了,而且训练效果会下降,过拟合了。

















 2267
2267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









