







目录
本文是在原本sql闯关的基础上总结得来,加入了自己的理解以及疑问解答(by GPT4)
数据准备
提取码:grtn
1. 课前小问答
1. 什么是 Windows 函数?(窗口函数)
A:想象一个很基本的数据分析场景:通过每日登录的用户数,分析登录用户总数的趋势
| 日期 | 当日登录人数 |
| 2023-07-01 | 112 |
| 2023-07-02 | 435 |
| 2023-07-03 | 1011 |
我们希望输出的表是
| 日期 | 当日登录人数 |
| 2023-07-01 | 112 |
| 2023-07-02 | 323 |
| 2023-07-03 | 576 |
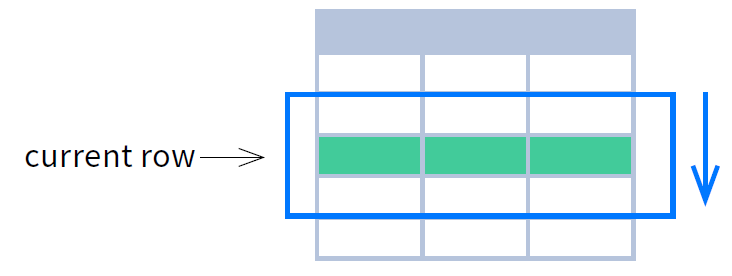
这个时候,我们需要的操作是:针对每一天的日期,计算截止到当天为止的登录人数的累和,因为我们的数据是每天一行,这意味着第一天的数据需要处理 1行,第二天 2 行,第三天 3 行……,以此类推,我们在数据表当中形成了一个“数据框”,这个框限定了我们需要处理和统计的数据范围
在 SQL 语言中,我们把这个 “框” 称之为 Window,如下图所示
2. Window 函数的功能强大之处在哪里呢?
A: Window 函数可以理解为 GROUP BY 函数的一种补充,其精髓在于一个关键词:动态
当我们对于一张表进行 GROUP BY 的时候,只要我们不调整 GROUP BY 字段,那么每次分组出来的结果都是静态的,即每个组内可以被统计的数据在数据表确定的时候已经被固定了
但是当我们遇到上文中的情况,对于每一个分组(日期),我们需要动态的扩张/缩减数据的时候,就需要使用 Windows 的函数。
更多关于 动态 分组的效果的案例,可以继续阅读
严格来说 window 函数(窗口函数)的称呼并不够准确:WINDOW 关键字并不直接出现在函数当中
2. 开始之前的准备
# 导入库
from IPython.display import Markdown as md
import sqlite3
import pandas as pd
import numpy as np
import json
from copy import deepcopy
from datetime import datetime
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 为了更好的展示 Windows 函数的效果,我们选用了【天猫订单成交】的数据集
# 该数据集记录了 2w+ 条目成交订单数据
df = pd.read_csv('./data/tmall_order_report.csv')
# 将表格中 NaN 值替换为 NULL
df = df.where(pd.notnull(df), None)
# 为了简化下面的教程,我们新增一个【订单创建日期】的字段
df['订单创建日期'] = df['订单创建时间'].apply(lambda x:pd.Timestamp(x).date()).astype(str)
# 将数据写入一张名为 example_table 的表
with sqlite3.connect('example.db') as conn:
df.to_sql('example_table', con=conn, if_exists='replace', index=False)
connection = sqlite3.connect('example.db')
# 查看该数据集的字段名称
df.columns
Index(['订单编号', '总金额', '买家实际支付金额', '收货地址 ', '订单创建时间', '订单付款时间 ', '退款金额',
'订单创建日期'],
dtype='object')
df.head()
| 订单编号 | 总金额 | 买家实际支付金额 | 收货地址 | 订单创建时间 | 订单付款时间 | 退款金额 | 订单创建日期 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 178.8 | 0.0 | 上海 | 2020-02-21 00:00:00 | None | 0.0 | 2020-02-21 |
| 1 | 2 | 21.0 | 21.0 | 内蒙古自治区 | 2020-02-20 23:59:54 | 2020-02-21 00:00:02 | 0.0 | 2020-02-20 |
| 2 | 3 | 37.0 | 0.0 | 安徽省 | 2020-02-20 23:59:35 | None | 0.0 | 2020-02-20 |
| 3 | 4 | 157.0 | 157.0 | 湖南省 | 2020-02-20 23:58:34 | 2020-02-20 23:58:44 | 0.0 | 2020-02-20 |
| 4 | 5 | 64.8 | 0.0 | 江苏省 | 2020-02-20 23:57:04 | 2020-02-20 23:57:11 | 64.8 | 2020-02-20 |
3. Window 函数核心:frame
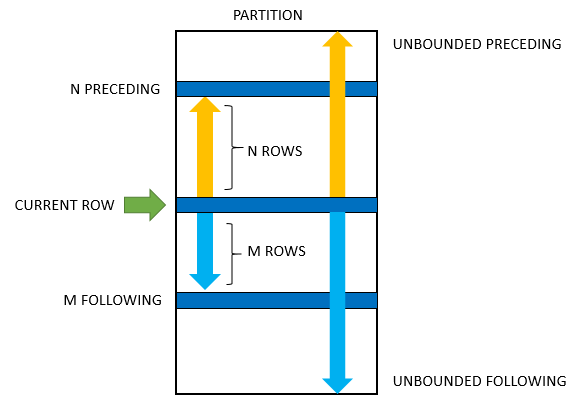
要熟练掌握 window 函数,我们需要先掌握 frame 的概念,一个简单的 frame 可以通过下图表示
一个 frame 可以近似类比为 GROUP BY 中的一个 group,即以某个标准(group 中是 group by 后的条件)下分组产生的一组数据
而为了将 window 的精髓,也就是动态的概念发挥出来,frame 的分组标准从 某个具体的条件 强化到 每一行数据
如何去理解“从 某个具体的条件 强化到 每一行数据”
例如:
当我们使用 GROUP BY user_id 的时候,实际上我们的分组是按照 user_id = ‘a’, user_id=‘b’,… 这些 “具体的条件”开展的
而当我们使用 window 函数的时候,每一行数据都是独立的一组,加入数据表中有两条满足 user_id = ‘a’ 的数据,他们也会被视为单独的两组
因为分组的结果是 “每一行数据一组”,因此所有 window 函数返回的数据行数和处理前的行数 必须是一致的
正因为 window 函数按照每一行作为分组的标准,所以在某个具体的 frame 当中,我们能够找到这个 frame 的“轴”(也就是某一具体行,在上图中用 CURRENT ROW)表示,而基于这个“轴“,我们可以去定义每个分组下的数据范围
再次将 window 函数类比 GROUP BY, 后者是基于某个条件获取一组数据,或者说,该组数据必然全部满足 这个具体的条件,而 window 函数当中,根据 frame 获取的数据也是“必然全部满足”某个条件,而这个条件,就是这些数据的位置在以轴为中心的一个具体的范围内
用一张表格展示这个对比:
| 分组方式 | 分组条件 | 组内数据满足 | 分组数 |
|---|---|---|---|
| GROUP BY | GROUP BY 后的条件的具体取值 | GROUP BY 后的条件 | <= 数据的条目数 |
| WINDOWS 函数 | 无条件,每行数据都是一组 | 处于“轴”的一定范围内 | = 数据的条目数 |
3.1 “轴”的范围控制:frame 参数
如图所示,围绕“轴”,也就是 CURRENT ROW 所框定的范围简单而言可以用两个参数来表示:范围的上界(方框的顶边)和范围的下届(方框的底边)
-
一般的 SQL 语言中,我们可以用 BETWEEN … AND … 去串联上界和下界,即 BETWEEN 范围的上界 AND 范围的下界
-
为了帮助我们更好的描述 上界 和 下界的定义,绝大部分 SQL 语句提供了下面的快捷语法
| 语法 | 表义 | 使用案例 |
|---|---|---|
| N PRECEDING | N 必须是具体的正整数,代表向上取 N 行数据 | BETWEEN 1 PRECEDING AND 1 FOLLOWING |
| N FOLLOWING | N 必须是具体的正整数,代表向下取 N 行数据 | BETWEEN 1 PRECEDING AND 1 FOLLOWING |
| UNBOUNDED | 代表不设条目限制 | BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING |
| CURRENT ROW | 代表当前行,也就是作为分组依据的行 | BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW |
✍️ 小练习 1: 尝试写出上界为当前行向上取 3 行,下界不设限制的表达式
# ...your code...
# ROWS BETWEEN 3 PRECEDING AND UNBOUNDED FOLLOWING
3.2 frame 内数据处理:ROWS,RANGE,ORDER BY
仅仅通过上面的例子,我们可能对于 window 函数的处理能力还有所顾虑,毕竟在现实的数据表当中,每一行需要对应处理的数据组恰好就落在这一行周围的概率太小了
以本教程开头的数据举例,如果数据表的顺序被打乱了,那么对于每一行数据就不能简单的用“统计其前面所有行”来规定 frame 了
每日登录统计表:
| 日期 | 当日登录人数 |
|---|---|
| 2023-07-01 | 112 |
| 2023-07-03 | 576 |
| 2023-07-02 | 323 |
在这种情况下,我们可以在将对应的数据分到具体的 frame 当中之前(只有分配到了 frame 当中之后,才会按照 3.1 中的规则划出需要处理的数据范围),先规定好一些处理的规则。具体而言,绝大部分 SQL 语言都支持如下几种分配规则:
3.2.1 ROWS v.s RANGE
如果我们希望的是分配到每个 frame 的数据和"轴"之间的关系是基于他们在表格当中的位置关系,那么我们可以使用关键字 ROWS 来代表这个规则
例如: ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING 的含义就是
在 frame 当中,取当前行和在表中位于当前行下一行的数据
反之,如果我们希望分配到 frame 的数据和 “轴”之间的关系是 基于某个字段的具体值的大小关系,那么我们可以使用关键字 RANGE 来代表这个规则
例如:RANGE BETWEEN 2 PRECEDING AND CURRENT ROW 的含义就是
在 frame 当中,取当前行和某个字段值小于当前行的该字段值的前两行数据
3.2.2 ORDER BY
上面我们提到了,RANGE 可以针对某个字段值决定进入不同的 frame 的数据,那么如何在 SQL 语句中指定这些字段呢,我们可以使用 ORDER BY 关键字 + 字段名:
例如 3.2.1 中的语句加上 ORDER BY : ORDER BY price RANGE BETWEEN 2 PRECEDING AND CURRENT ROW ,就代表着:
在 frame 当中,取当前行和 price 小于当前行的 price 值的前两行数据
当然,ORDER BY 也可以兼容 ROWS 关键字,这个时候 ORDER BY 起到的作用就变成了 单纯的将数据排序,即 ORDER BY price ROWS BETWEEEN 2 PRECEDING AND CURRENT ROW 代表:
在 frame 当中,先按照 price 字段将数据排序,取当前行和在表中位于当前行的前两行数据
✍️ 小练习 2: 尝试用自己的理解去解读 ORDER BY price, stock_number ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING 代表的数据范围
这段代码是窗口函数的一部分,在SQL查询中使用。它使用了ORDER BY子句来指定排序顺序,以及ROWS BETWEEN子句来定义窗口帧。让我们逐一解析这些部分:
-
ORDER BY price, stock_number:- 这部分指定了数据排序的顺序。首先按照
price字段进行排序,如果有相同的price值,则按照stock_number字段进行排序。 - 默认情况下,排序是升序的。也就是说,如果没有明确指定
ASC(升序)或DESC(降序),则默认为升序。
- 这部分指定了数据排序的顺序。首先按照
-
ROWS BETWEEN UNBOUNDED PRECEDING AND 1:- 这里应该是
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING,因为通常需要指定窗口的结束部分,如1 FOLLOWING。 UNBOUNDED PRECEDING意味着窗口的开始是从当前分区的第一行开始。1 FOLLOWING表示窗口的结束是当前行之后的第一行。- 因此,对于每一行,窗口将包含从分区的开始到当前行之后的第一行的所有行。
- 这里应该是
综上所述,这段代码的含义是:对于每一行数据,它都会得到一个窗口,这个窗口包含了从当前分区的开始到当前行之后的第一行的所有数据。这些数据首先根据price进行排序,如果price相同,则根据stock_number排序。这种窗口定义通常用于执行累积或滚动计算,如累积总和、移动平均等。
3.3 控制分配到 frame 的数据:PARTITION BY, FILTER
在上面的例子中,我们对于一个 frame 内需要处理的数据体量是没有做过限制的,比如,ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING会要求每个 frame 去处理当前行和在表中位于当前行下一行的数据,这意味着,每一个 frame 在通过上下界截取数据之前都会拿到整张表的全量数据
对于数据体量较大的表格,这个操作显然是不尽如人意的,同时,如果只是针对整张表进行处理,那么有些问题并不能被解决
例如,在本教程开头的例子中,我们引入一个新的字段 “是否为新用户”
每日登录统计表:
<table style="border-collapse: collapse;">
<tr>
<th style="padding: 8px; background-color: #499ed4; color: #fff; text-align: center;">日期</th>
<th style="padding: 8px; background-color: #499ed4; color: #fff; text-align: center;">当日登录人数</th>
<th style="padding: 8px; background-color: #499ed4; color: #fff; text-align: center;">是否为新用户</th>
</tr>
<tr>
<td style="padding: 8px;">2023-07-01</td>
<td style="padding: 8px;">112</td>
<td style="padding: 8px;">True</td>
</tr>
<tr>
<td style="padding: 8px;">2023-07-02</td>
<td style="padding: 8px;">323</td>
<td style="padding: 8px;">True</td>
</tr>
<tr>
<td style="padding: 8px;">2023-07-03</td>
<td style="padding: 8px;">576</td>
<td style="padding: 8px;">True</td>
<tr>
<td style="padding: 8px;">2023-07-02</td>
<td style="padding: 8px;">324</td>
<td style="padding: 8px;">False</td>
</tr>
<tr>
<td style="padding: 8px;">2023-07-03</td>
<td style="padding: 8px;">780</td>
<td style="padding: 8px;">False</td>
</tr>
<tr>
<td style="padding: 8px;">2023-07-01</td>
<td style="padding: 8px;">226</td>
<td style="padding: 8px;">False</td>
</tr>
且我们需要按照【是否为新用户】统计累积登录用户数,那么我们需要在满足【是否为新用户 = True】 的 frame 当中只保留【是否为新用户 = True】的数据,而非完整的数据表格
大部分 SQL 语言支持通过 PARTITION BY 和 FILTER 来实现在分配到 frame 前的过滤
3.3.1 PARTITION BY
在指定了 PARTITION BY 后的字段的情况下,分配到每个 frame 的数据必须满足这些字段的值和 frame 中 CURRENT_ROW (也就是“轴”)的值一致,基于 PARTITION BY 的 window 函数近似可以理解为对于全表先做一次 GROUP BY 处理,然后只将某个 GROUP 内的数据分配到具体的 frame 当中
用上面的例子,我们可以这样写
PARTITION BY 是否为新用户 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
这样【是否新用户=True】的 frame 就只会分配到满足 【是否新用户=True】 的数据,反之,【是否新用户=False】也只会分配到 【是否新用户=False】的数据
3.3.2 FILTER
有的时候,我们在分配的时候会希望过滤掉一些脏数据,这个时候 FILTER 关键字可以帮助我们实现这一点
用上面的例子,我们可以这样写
FILTER(WHERE 是否为新用户 = True)
与 PARTITION BY 稍微有些不同的是,FILTER 的语法在结构上相对独立,在下文档会有详细地展开
✍️ 小练习 3: 尝试用自己的理解去解读 PARTITION BY price ORDER BY stock_number ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING 代表的数据范围
这段代码是窗口函数的一部分,在SQL查询中使用。它使用了ORDER BY子句来指定排序顺序,以及ROWS BETWEEN子句来定义窗口帧。让我们逐一解析这些部分:
-
ORDER BY price, stock_number:- 这部分指定了数据排序的顺序。首先按照
price字段进行排序,如果有相同的price值,则按照stock_number字段进行排序。 - 默认情况下,排序是升序的。也就是说,如果没有明确指定
ASC(升序)或DESC(降序),则默认为升序。
- 这部分指定了数据排序的顺序。首先按照
-
ROWS BETWEEN UNBOUNDED PRECEDING AND 1:- 这里应该是
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 FOLLOWING,因为通常需要指定窗口的结束部分,如1 FOLLOWING。 UNBOUNDED PRECEDING意味着窗口的开始是从当前分区的第一行开始。1 FOLLOWING表示窗口的结束是当前行之后的第一行。- 因此,对于每一行,窗口将包含从分区的开始到当前行之后的第一行的所有行。
- 这里应该是
综上所述,这段代码的含义是:对于每一行数据,它都会得到一个窗口,这个窗口包含了从当前分区的开始到当前行之后的第一行的所有数据。这些数据首先根据price进行排序,如果price相同,则根据stock_number排序。这种窗口定义通常用于执行累积或滚动计算,如累积总和、移动平均等。
4. Window 函数的计算:聚合函数
恭喜你,了解完 window 函数最核心的 frame 概念之后,剩下的内容在理解上会简单许多。
回到我们最初使用 window 函数的目的,在拿到了每个 frame 的数据之后,我们希望对于这部分数据进行分析/统计以产出一个结果
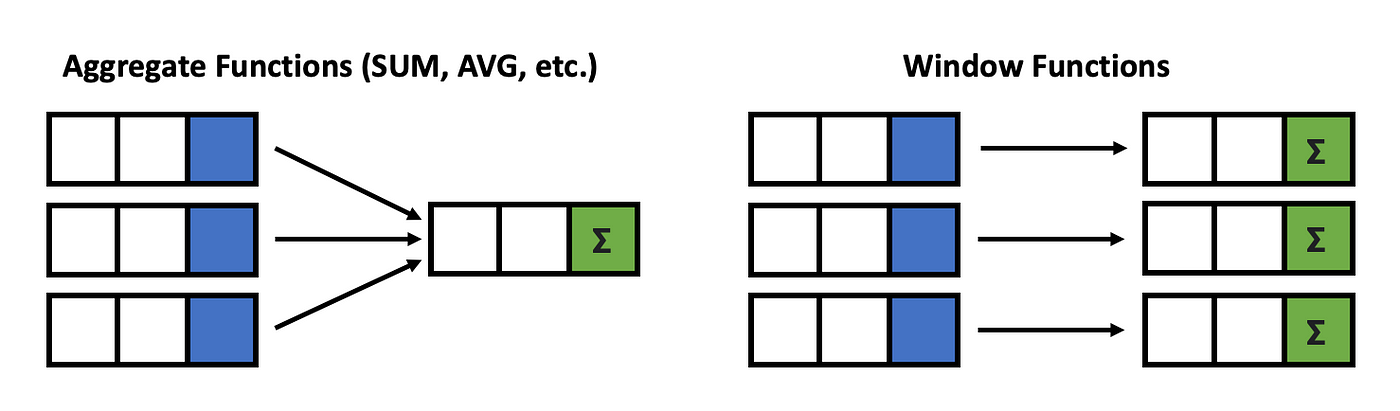
这个时候,我们只需要回归到我们熟悉的聚合函数就行啦 🎉,他们的用法和我们在 GROUP BY 当中的使用没有差别
唯一的区别是, GROUP BY 中的聚合函数返回的结果是按组返回的,Window 函数中的聚合函数是按照行(frame)返回的,如下图所示
特别需要记住的 2 个点是:
-
我们需要在 frame 前加上一个 OVER() 关键字来限定 frame 的定义
-
FILTER 语句在 OVER() 之外,聚合函数之后
### 例1:我们以订单数据为例
### 假设我们需要按照 订单创建日期 计算累积订单量
query = '''
SELECT
t1.order_date
,SUM(orders_num) -- 聚合函数 SUM()
OVER( -- OVER 关键字,()内定 frame
ORDER BY order_date -- 按照 order_date 排序
ROWS -- 按照表当中的相对位置
BETWEEN -- 界定上下界
UNBOUNDED PRECEDING -- 上界,不设限制
AND
CURRENT ROW -- 下界,当前行
) AS running_total
FROM
(
SELECT "订单创建日期" AS order_date
,COUNT("订单编号") AS orders_num
FROM example_table
GROUP BY "订单创建日期"
)AS t1 -- 按照日期生成当日订单量
'''
result = connection.execute(query).fetchall()
result
[('2020-02-01', 176),
('2020-02-02', 398),
('2020-02-03', 665),
('2020-02-04', 1134),
('2020-02-05', 1503),
('2020-02-06', 1647),
('2020-02-07', 1824),
('2020-02-09', 2228),
('2020-02-10', 2255),
('2020-02-11', 2270),
('2020-02-12', 2271),
('2020-02-13', 2276),
('2020-02-14', 2283),
('2020-02-15', 2288),
('2020-02-17', 2678),
('2020-02-18', 3693),
('2020-02-19', 4718),
('2020-02-20', 6063),
('2020-02-21', 8131),
('2020-02-22', 10158),
('2020-02-23', 12358),
('2020-02-24', 14356),
('2020-02-25', 17772),
('2020-02-26', 20621),
('2020-02-27', 23207),
('2020-02-28', 25898),
('2020-02-29', 28010)]
### 例2:
### 假设我们需要按照 订单创建日期 计算累积订单量
### 同时我们希望按照,收获地址展现累计值
### 只返回 北京 和 上海 的结果
query = '''
SELECT
t1.order_date
,t1.address
,SUM(orders_num) -- 聚合函数 SUM()
OVER( -- OVER 关键字,()内定 frame
PARTITION BY address -- 每个 frame 内只有 address 相同的数据
ORDER BY order_date -- 按照 order_date 排序
ROWS -- 按照表当中的相对位置
BETWEEN -- 界定上下界
UNBOUNDED PRECEDING -- 上界,不设限制
AND
CURRENT ROW -- 下界,当前行
) AS running_total
FROM
(SELECT "订单创建日期" AS order_date
,"收货地址 " AS address -- 注意这里是"收货地址 " 而非 "收货地址"
,COUNT("订单编号") AS orders_num
FROM example_table
GROUP BY "订单创建日期","收货地址 "
)AS t1 -- 按照日期,收获地址生成当日订单量
WHERE t1.address IN ('北京','上海')
'''
result = connection.execute(query).fetchall()
result
[('2020-02-01', '上海', 48),
('2020-02-02', '上海', 114),
('2020-02-03', '上海', 197),
('2020-02-04', '上海', 330),
('2020-02-05', '上海', 414),
('2020-02-06', '上海', 459),
('2020-02-07', '上海', 499),
('2020-02-09', '上海', 596),
('2020-02-10', '上海', 603),
('2020-02-11', '上海', 608),
('2020-02-13', '上海', 609),
('2020-02-14', '上海', 612),
('2020-02-17', '上海', 685),
('2020-02-18', '上海', 834),
('2020-02-19', '上海', 963),
('2020-02-20', '上海', 1090),
('2020-02-21', '上海', 1291),
('2020-02-22', '上海', 1508),
('2020-02-23', '上海', 1717),
('2020-02-24', '上海', 1957),
('2020-02-25', '上海', 2260),
('2020-02-26', '上海', 2571),
('2020-02-27', '上海', 2862),
('2020-02-28', '上海', 3148),
('2020-02-29', '上海', 3353),
('2020-02-01', '北京', 10),
('2020-02-02', '北京', 23),
('2020-02-03', '北京', 36),
('2020-02-04', '北京', 59),
('2020-02-05', '北京', 94),
('2020-02-06', '北京', 98),
('2020-02-07', '北京', 108),
('2020-02-09', '北京', 147),
('2020-02-10', '北京', 151),
('2020-02-11', '北京', 153),
('2020-02-17', '北京', 178),
('2020-02-18', '北京', 271),
('2020-02-19', '北京', 388),
('2020-02-20', '北京', 521),
('2020-02-21', '北京', 691),
('2020-02-22', '北京', 849),
('2020-02-23', '北京', 1025),
('2020-02-24', '北京', 1163),
('2020-02-25', '北京', 1361),
('2020-02-26', '北京', 1547),
('2020-02-27', '北京', 1727),
('2020-02-28', '北京', 1894),
('2020-02-29', '北京', 2054)]
print(sqlite3.version)
2.6.0
✍️ 小练习 4: 执行下面的代码前,猜猜会发生什么
### 例 3:
### 在例 2 的基础上,加上 FILTER
query = '''
SELECT
t1.order_date
,t1.address
,SUM(orders_num) -- 聚合函数 SUM()
FILTER(
WHERE t1.address ='北京') -- 只保留 address = ‘北京’
OVER( -- OVER 关键字,()内定 frame
PARTITION BY address -- 每个 frame 内只有 address 相同的数据
ORDER BY order_date -- 按照 order_date 排序
ROWS -- 按照表当中的相对位置
BETWEEN -- 界定上下界
UNBOUNDED PRECEDING -- 上界,不设限制
AND
CURRENT ROW -- 下界,当前行
) AS running_total
FROM
(SELECT "订单创建日期" AS order_date
,"收货地址 " AS address
,COUNT("订单编号") AS orders_num
FROM example_table
GROUP BY "订单创建日期","收货地址 "
)AS t1 -- 按照日期,收获地址生成当日订单量
WHERE t1.address IN ('北京','上海')
'''
result = connection.execute(query).fetchall()
result
[('2020-02-01', '上海', None),
('2020-02-02', '上海', None),
('2020-02-03', '上海', None),
('2020-02-04', '上海', None),
('2020-02-05', '上海', None),
('2020-02-06', '上海', None),
('2020-02-07', '上海', None),
('2020-02-09', '上海', None),
('2020-02-10', '上海', None),
('2020-02-11', '上海', None),
('2020-02-13', '上海', None),
('2020-02-14', '上海', None),
('2020-02-17', '上海', None),
('2020-02-18', '上海', None),
('2020-02-19', '上海', None),
('2020-02-20', '上海', None),
('2020-02-21', '上海', None),
('2020-02-22', '上海', None),
('2020-02-23', '上海', None),
('2020-02-24', '上海', None),
('2020-02-25', '上海', None),
('2020-02-26', '上海', None),
('2020-02-27', '上海', None),
('2020-02-28', '上海', None),
('2020-02-29', '上海', None),
('2020-02-01', '北京', 10),
('2020-02-02', '北京', 23),
('2020-02-03', '北京', 36),
('2020-02-04', '北京', 59),
('2020-02-05', '北京', 94),
('2020-02-06', '北京', 98),
('2020-02-07', '北京', 108),
('2020-02-09', '北京', 147),
('2020-02-10', '北京', 151),
('2020-02-11', '北京', 153),
('2020-02-17', '北京', 178),
('2020-02-18', '北京', 271),
('2020-02-19', '北京', 388),
('2020-02-20', '北京', 521),
('2020-02-21', '北京', 691),
('2020-02-22', '北京', 849),
('2020-02-23', '北京', 1025),
('2020-02-24', '北京', 1163),
('2020-02-25', '北京', 1361),
('2020-02-26', '北京', 1547),
('2020-02-27', '北京', 1727),
('2020-02-28', '北京', 1894),
('2020-02-29', '北京', 2054)]
上面的例子中可以发现, FILTER() 函数并不在 frame 的定义里面,但是这个函数确实影响了整个 window 函数的结果
此外,上述代码在mysql8.0及以上版本,以及postgresql中可以直接运行
5. Window 函数效果展示
5.1 窗口统计值
window 函数最常见的使用范例:统计某个窗口内的数据平均值
# 对于订单数据
# 我们想要统计每个城市的 3日平均消费
query = '''
SELECT t1.order_date
,t1.address
,avg(total_payment) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) as three_day_avg
FROM (SELECT "订单创建日期" AS order_date
,"收货地址 " AS address
,SUM("总金额") AS total_payment
FROM example_table
GROUP BY "订单创建日期","收货地址 ") AS t1
'''
result = connection.execute(query).fetchall()
result[:20]
[('2020-02-01', '上海', 5855.0),
('2020-02-02', '上海', 6296.333333333333),
('2020-02-03', '上海', 9247.116666666667),
('2020-02-04', '上海', 9204.783333333333),
('2020-02-05', '上海', 8137.783333333333),
('2020-02-06', '上海', 5008.0),
('2020-02-07', '上海', 4962.666666666667),
('2020-02-09', '上海', 4688.0),
('2020-02-10', '上海', 3320.0),
('2020-02-11', '上海', 1099.3333333333333),
('2020-02-13', '上海', 67.0),
('2020-02-14', '上海', 2471.8233333333333),
('2020-02-17', '上海', 7250.646666666668),
('2020-02-18', '上海', 11132.52666666667),
('2020-02-19', '上海', 13485.703333333333),
('2020-02-20', '上海', 16202.313333333332),
('2020-02-21', '上海', 19493.533333333333),
('2020-02-22', '上海', 21403.966666666667),
('2020-02-23', '上海', 85819.23333333332),
('2020-02-24', '上海', 89782.89999999998)]
5.2 抛开 JOIN :Titanic 乘客生存率方差
我们在上一个教程,曾经通过 JOIN 和 GROUP BY 的方式去计算 Titanic 数据集当中,不同 Pclass 的用户的生存率方差
df = pd.read_csv('./data/train.csv')
# 将表格中 NaN 值替换为 NULL
df = df.where(pd.notnull(df), None)
# 将数据写入一张名为 titanic 的表
with sqlite3.connect('example.db') as conn:
df.to_sql('titanic', con=conn, if_exists='replace', index=False)
# 计算方差的查询
query1 = '''
SELECT t1.Pclass
,avg((t2.Survived-t1.mean_survived)*(t2.Survived-t1.mean_survived)) AS std -- 方差计算
FROM
(SELECT Pclass
,avg(Survived) AS mean_survived
FROM titanic
GROUP BY Pclass) AS t1
JOIN titanic AS t2
ON t1.Pclass = t2.Pclass
GROUP BY t1.Pclass
'''
result = connection.execute(query1).fetchall()
result
[(1, 0.23319615912208574), (2, 0.24926157844990615), (3, 0.18362293171174757)]
提问:你好,请为我解析这段代码,我不清楚为什么计算方差时计算的是t1每个Pclass下所有Survived的值减去平均生存率。我认为子查询中,t2与t1进行了内连接,那么得到的数据应该是交集,得到的交集里t2所有的survived都能得到保留吗
这段SQL代码的目的是计算泰坦尼克号数据集中,不同乘客等级(Pclass)的生存率的方差。代码中使用了子查询和内连接。下面我将逐步解析这段代码,以帮助您理解其工作原理:
-
子查询(t1):
- 这部分的代码从
titanic表中选取了Pclass(乘客等级)和Survived(生存情况)两个字段。 - 对每个
Pclass等级,计算了Survived的平均值,即每个等级的平均生存率。这个平均值在查询中被命名为mean_survived。 - 结果是一个临时表
t1,它包含每个Pclass的平均生存率。
- 这部分的代码从
-
内连接:
- 子查询
t1与原始的titanic表(在这里被命名为t2)进行了内连接。 - 连接的条件是
t1.Pclass = t2.Pclass,意味着对每个Pclass等级,将t1中的平均生存率与t2中的每个相应等级的乘客记录进行匹配。
- 子查询
-
方差计算:
- 对于每个
Pclass等级,计算方差。方差的计算方式是对该等级中的每个乘客,计算其生存情况(t2.Survived)与该等级平均生存率(t1.mean_survived)的差的平方,然后求这些平方值的平均数。 - 这实际上是在计算每个等级中个体生存情况与该等级平均生存率之间差异的程度。
- 对于每个
-
结果:
- 该查询返回每个
Pclass等级的方差,这表明了在每个等级中个体生存情况的变异性。
- 该查询返回每个
您的担忧点在于内连接的结果是否会包含t2中所有的Survived数据。答案是会的。内连接确保了只有那些在两个表中都有匹配Pclass的记录会被选中。由于t1是从t2(即titanic表)派生出来的,且t1中包含了t2中所有可能的Pclass值,因此t2中关于每个Pclass的每条记录都会被保留,并用于方差的计算。
让我们试着用 window 函数改写一下上面的计算
# 计算方差的查询 -- window 函数 版本
query2 = '''
SELECT t1.Pclass
,avg((t1.err)*(t1.err)) AS std
FROM
(SELECT
Pclass
,(Survived - -- window 函数的结果可以直接被引用
avg(Survived) -- avg() 聚合函数
OVER(
PARTITION BY Pclass -- 每个 frame 只保留 Pclass相同的数据
)
) err
FROM titanic) AS t1
GROUP BY t1.Pclass
'''
result = connection.execute(query2).fetchall()
result
[(1, 0.23319615912208574), (2, 0.24926157844990615), (3, 0.18362293171174757)]
这段SQL代码的目的与前一个查询相似,即计算泰坦尼克号数据集中不同乘客等级(Pclass)的生存率的方差。然而,这个查询使用了SQL的窗口函数来实现。我将逐步解释这段代码:
-
子查询(t1):
- 这部分代码首先选取了
Pclass(乘客等级)和Survived(生存情况)字段。 - 使用窗口函数
avg(Survived) OVER (PARTITION BY Pclass)来计算每个Pclass等级的平均生存率。窗口函数允许您在每个Pclass组内进行计算,而不是对整个表进行计算。这里的PARTITION BY Pclass确保了平均值是在每个Pclass等级内部独立计算的。 - 计算每个乘客的生存情况与其所在等级的平均生存率之间的差异,这个差异在查询中被命名为
err。
- 这部分代码首先选取了
-
方差计算:
- 在外层查询中,对子查询
t1的结果进行处理。对于每个Pclass等级,计算err的平方的平均值,即方差。这通过avg((t1.err)*(t1.err))实现。 - 与标准方差公式一致,这里计算的是每个乘客的生存情况偏离其所在等级平均生存率的程度。
- 在外层查询中,对子查询
-
结果:
- 该查询返回每个
Pclass等级的方差,展示了每个等级中个体生存情况的变异性。
- 该查询返回每个
总的来说,这个查询使用窗口函数而不是内连接来计算每个Pclass等级的平均生存率,然后计算方差。窗口函数是处理此类问题的强大工具,它可以在不必对原始数据集进行多次分组和连接的情况下计算复杂的聚合统计。
💡 我们可以发现,用了 window 函数之后原来复杂的 JOIN 语法竟然不见了,同时在计算最终结果的场合写法也更加凝练了一些
这便是 window 函数的一大优势:对于需要自 JOIN 的表格可以做到书写上的精简
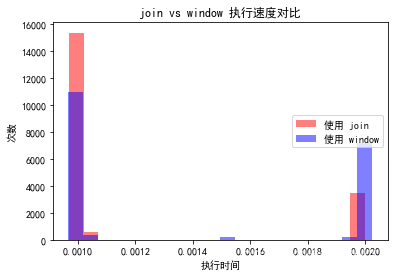
当然,从执行效率上来说,window 相较于 join 可能会有一些劣势,如下图
import time
window = []
join = []
for i in range(100):
start_time = time.time()
_ = connection.execute(query1).fetchall()
join.append(time.time()-start_time)
for i in range(100):
start_time = time.time()
_ = connection.execute(query2).fetchall()
window.append(time.time()-start_time)
# 通过 matplotlib 看时间分布的变化
# 蓝色为使用 window ,红色为使用 join
fig, ax = plt.subplots()
ax.set_xlabel('执行时间')
ax.set_ylabel('次数')
ax.set_title(r'join vs window 执行速度对比')
plt.rcParams["figure.figsize"] = (12,8)
plt.hist(join,bins =20,alpha=0.5,color='r',label='使用 join',density=True)
plt.hist(window,bins = 20,alpha=0.5,color='b',label='使用 window',density=True)
ax.legend(loc='right')
plt.show()
5.3 首次出现 / 最后一次出现
原文:window 函数的另一个用处,是可以很方便的定位某一数据第一次和最后一次出现的位置/时间
但是并没有理解下述代码为啥可以实现首次出现/最后一次出现的判定,有没有大佬解释一下的
# 对于订单数据
# 我们想要统计每个城市的首次有订单总金额 > 2000 的日期
query = '''
SELECT
address
,order_date
FROM
(SELECT
"收货地址 " AS address
,"订单创建日期" AS order_date
,min("订单创建日期") -- min() 聚合函数
OVER( -- 定义 frame
PARTITION BY "收货地址 " -- frame 数据中只保留地址相同的
ORDER BY "订单创建日期" ASC -- 按照创建日期排序
ROWS -- 按照表中的相对位置取数
BETWEEN
1 PRECEDING -- 前一行数据
AND CURRENT ROW
) AS last_order_date -- 取出每条数据的“前一行”日期
FROM example_table
WHERE "总金额">2000)
WHERE last_order_date = order_date
'''
result = connection.execute(query).fetchall()
result
[('上海', '2020-02-04'),
('内蒙古自治区', '2020-02-26'),
('安徽省', '2020-02-28'),
('安徽省', '2020-02-28'),
('山东省', '2020-02-22'),
('广东省', '2020-02-09'),
('江苏省', '2020-02-18'),
('河北省', '2020-02-23'),
('河北省', '2020-02-23'),
('河南省', '2020-02-02'),
('重庆', '2020-02-29'),
('重庆', '2020-02-29'),
('陕西省', '2020-02-18')]
这段SQL代码使用了窗口函数(Window Function)来查询某个条件下的订单信息。它的目的是找出那些订单金额超过2000,并且该订单是收货地址相同的连续两个订单中的后一个订单的情况。我将逐步解析这段代码:
-
内部查询:
SELECT "收货地址 " AS address, "订单创建日期" AS order_date, min("订单创建日期") OVER (...) AS last_order_date:这部分是一个选择语句,它选取了收货地址、订单创建日期,并使用窗口函数计算每个地址的最早订单日期。min("订单创建日期") OVER (PARTITION BY "收货地址 " ORDER BY "订单创建日期" ASC ROWS BETWEEN 1 PRECEDING AND CURRENT ROW):这是一个窗口函数。它的作用是对于每个"收货地址 ",按照"订单创建日期"升序排列,并查找当前行及其前一行(即两个连续订单)中的最早订单日期。FROM example_table WHERE "总金额">2000:从example_table表中选择那些"总金额"超过2000的记录。
-
外部查询:
SELECT address, order_date FROM (...) WHERE last_order_date = order_date:这部分从内部查询的结果中选取address和order_date,但只有在last_order_date(前一个订单的日期)等于当前行的order_date时才会选择这行数据。这实际上是在查找那些作为连续订单的第二个订单的情况。
-
执行与结果:
result = connection.execute(query).fetchall():这部分代码执行上面的SQL查询,并获取所有符合条件的结果。result:这将包含所有满足条件的记录,即那些订单金额超过2000,并且是相同地址连续订单中的后一个订单的记录。
总的来说,这段代码的目的是在一个订单数据表中查找对于每个地址而言,每一对连续订单中的第二个订单,且这些订单的总金额超过2000。
出现重复值的原因可能与数据本身或窗口函数的定义有关。考虑到您的查询逻辑,这里有几个可能导致重复值出现的原因:
-
数据本身的重复:如果在原始数据
example_table中,对于同一地址在相同的日期有多个订单总金额超过2000,这些记录都会在内部查询中被选中,因此在最终结果中会出现重复。 -
窗口函数的行为:在您的窗口函数定义中,使用了
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW,这意味着对于每一行,窗口包含了当前行和它前面的一行。如果有两行数据是连续的并且它们的订单日期相同,那么在计算last_order_date时,它们都会考虑到对方,从而在最终结果中出现重复。 -
查询逻辑:在最外层的查询中,您是根据
last_order_date = order_date来筛选记录的。这意味着如果有两个连续的订单具有相同的日期,并且都满足内部查询的条件(即总金额超过2000),它们都会被选中,因为对于这两个订单来说,last_order_date(前一个订单的日期)等于自己的order_date。
要解决这个问题,您可能需要进一步精确您的查询条件。例如,如果您希望每个地址只保留一个符合条件的记录,您可以进一步使用聚合函数去重,或者根据具体的需求调整窗口函数的定义。如果您能提供更具体的需求或数据结构,我可以帮助您调整查询以避免这种重复。
6. 小结 🥡
在本教程中,我们从 frame 和 聚合函数的视角去解读了 window 函数的基本概念了和具体的用法,并且着重强调了 window 函数和 group by 函数的一些异同点
window 函数是一个需要在实践当中大量使用才能熟练掌握的技巧,特别是对于 frame 这一概念的理解和熟练应用很大程度上会决定你对于 window 函数的使用深度
正如 5.2 和 5.3 中所展示的,window 函数的功能远不止于进行“数据统计”或是“数据处理”那么简单,例如其对于 JOIN 函数的替代可以在大量的场合减少代码编写的压力
希望你能够在本教程后去更多了解 window 函数的用法和技巧,或者持续关注相关 workshop 的内容更新~
7. 闯关题
Q1:在订单数据集中,从订单创建 {时间} 上首次出现“单笔交易总金额>5000”最晚的城市/省份是?
方法一做题思路及解析:
先子查询获取收获地址,以及对应条件下对应地域的frame中最小订单创建日期
然后再对最小订单日期做降序,获取这里边对应地域
# 方法一:
query1 = '''
SELECT
address,
last_order_date
FROM
(SELECT
"收货地址 " AS address
,min("订单创建日期")
OVER(
PARTITION BY "收货地址 "
ORDER BY "订单创建日期"
) AS last_order_date
FROM example_table
WHERE "总金额">5000)
ORDER BY last_order_date DESC
LIMIT 1
'''
result = connection.execute(query1).fetchall() # [('内蒙古自治区',)]
result[0][0]
'内蒙古自治区'
查询解析
-
子查询:
- 您的子查询首先过滤出所有“总金额”大于5000的订单。
- 然后,对于每个“收货地址”,它使用窗口函数
min("订单创建日期") OVER (PARTITION BY "收货地址 " ORDER BY "订单创建日期")来找出每个地址首次出现总金额大于5000的订单日期。这里的窗口函数正确地实现了“首次出现”的逻辑。
-
外部查询:
- 这一部分从子查询结果中选择地址和相应的日期。
- 然后,它按照日期降序排序,以找出最晚的日期。
-
最终选择:
LIMIT 1,找出单个最晚的城市或省份。
-
窗口函数理解:
- 窗口函数
min("订单创建日期") OVER (PARTITION BY "收货地址 " ORDER BY "订单创建日期")正确地为每个地址找到了首次交易金额超过5000的日期。
- 窗口函数
方法二做题思路及解析:
# 方法二:参考答案,虽然能实现相同的结果但不理解原理
query1 = '''
WITH tmp AS
(
SELECT
"收货地址 " AS address
,"订单创建日期" AS order_timestamp
,max("订单创建日期") OVER(PARTITION BY "收货地址 " ORDER BY "订单创建时间" ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS next_order_ts
FROM example_table
WHERE "总金额">5000
)
SELECT
order_timestamp
,address
FROM tmp
WHERE next_order_ts = order_timestamp
ORDER BY order_timestamp DESC
LIMIT 1
'''
result = connection.execute(query1).fetchall()
result[0][1]
'内蒙古自治区'
您提供的SQL查询旨在找出首次出现单笔交易总金额超过5000的最晚城市或省份,但是使用了一个不同的方法来实现这一目的。让我来帮您解析这段代码的运行流程:
查询解析
-
临时表
tmp:- 这个临时表(
WITH tmp AS)首先从example_table中选择了所有单笔交易总金额超过5000的订单。 - 在选择的字段中,包括“收货地址”(重命名为
address)、原始的“订单创建日期”(重命名为order_timestamp)。 - 关键部分是窗口函数
max("订单创建日期") OVER(PARTITION BY "收货地址 " ORDER BY "订单创建时间" ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING)。这个函数的目的是对于每个地址,查找当前行及其下一行(即两个连续的订单)中的最晚订单日期。
- 这个临时表(
-
tmp表的外部查询:- 这一部分从临时表
tmp中选择订单日期和地址。 - 通过
WHERE next_order_ts = order_timestamp条件,它筛选出那些没有比当前订单更晚的订单的记录。这实际上找出了每个地址中最后一笔超过5000的订单。
- 这一部分从临时表
-
最终选择:
- 查询按照订单日期降序排序,并通过
LIMIT 1只返回最晚的记录。
- 查询按照订单日期降序排序,并通过
代码的逻辑问题
这段代码尝试找出每个地址中最后一笔超过5000的订单,然后从中选择最晚的一笔。但是,这种方法实际上并不准确地反映了“首次出现单笔交易总金额超过5000”的查询要求。相反,它似乎是在寻找最晚的最后一笔交易总金额超过5000的订单,这可能并不符合原始的查询目的。
如果您的目标是找出“首次”单笔交易总金额超过5000的最晚城市或省份,原先的查询方法(使用min窗口函数)更为合适。这是因为min函数能够正确地定位到每个地址的首次超过5000的订单,而max函数则定位到最后一次,这在逻辑上有本质的不同。
# ...your code...
a1 = '内蒙古自治区' # 在 = 后面填入你的结果,如 a1 = "江苏省"
Q2:在订单数据集中,哪个城市/省份的订单金额(“总金额”字段)的方差最大?
思路及解析:
做题思路:直接在已有的方差代码上修改的
计划是先子查询出地域,以及针对地域的frame,计算每单的总金额与其所在地域的平均总金额之间的差异,这个差异在查询中被命名为err
然后求出方差并按降序排序,以找到对应方差最大的地域
query2 = '''
SELECT t1.address
,avg((t1.err)*(t1.err)) AS std
FROM
(SELECT
"收货地址 " AS address
,("总金额" - -- window 函数的结果可以直接被引用
avg("总金额") -- avg() 聚合函数
OVER(
PARTITION BY "收货地址 " -- 每个 frame 只保留 address 相同的数据
)
) err
FROM example_table) AS t1
GROUP BY t1.address
ORDER BY avg((t1.err)*(t1.err)) DESC
LIMIT 1
'''
result = connection.execute(query2).fetchall()
result
[('上海', 10577678.603002107)]
# ...your code...
a2 = '上海' # 在 '' 中填入你的结果,如 a2 = "江苏省"
Q3. 在订单数据集中,计算北京和上海的累计平均订单金额这一指标,两地这一指标差距最大的日期是几号?
方法一做题思路及解析:
累计平均订单金额 = 累计订单总金额 / 累计订单数
这个查询的流程如下:
- 首先,使用
WITH语句创建一个临时的结果集BeijingShanghaiAvgPayments,包含北京和上海的累计平均订单金额。 - 然后,分别创建两个临时结果集
BeijingAvg和ShanghaiAvg,分别包含北京和上海每日的累计平均订单金额。 - 接着,
Diff临时结果集计算北京和上海在每个相同日期的累计平均订单金额之差。 - 最后,从
Diff中选择差异最大的日期。
这个查询将返回累计平均订单金额差距最大的那个日期。
query3 = '''
WITH DailyAvgPayments AS (
SELECT
"收货地址 " AS address,
"订单创建日期" AS order_date,
SUM("总金额") AS daily_total,
COUNT("订单编号") AS daily_order_count
FROM example_table
WHERE "收货地址 " in ('北京', '上海')
GROUP BY "收货地址 ", "订单创建日期"
),
CumulativeAvgPayments AS (
SELECT
address,
order_date,
SUM(daily_total) OVER(PARTITION BY address ORDER BY order_date) /
SUM(daily_order_count) OVER(PARTITION BY address ORDER BY order_date) AS cumulative_avg_payment
FROM DailyAvgPayments
),
BeijingData AS (
SELECT order_date, cumulative_avg_payment
FROM CumulativeAvgPayments
WHERE address = '北京'
),
ShanghaiData AS (
SELECT order_date, cumulative_avg_payment
FROM CumulativeAvgPayments
WHERE address = '上海'
),
Diff AS (
SELECT
BeijingData.order_date,
ABS(BeijingData.cumulative_avg_payment - ShanghaiData.cumulative_avg_payment) AS difference
FROM BeijingData
JOIN ShanghaiData ON BeijingData.order_date = ShanghaiData.order_date
)
SELECT order_date, difference
FROM Diff
ORDER BY difference DESC
-- LIMIT 1;
'''
result = connection.execute(query3).fetchall()
result
[('2020-02-24', 87.65238560257924),
('2020-02-25', 74.52541065913273),
('2020-02-26', 64.39660004168617),
('2020-02-27', 60.138257495841316),
('2020-02-28', 53.690752194786185),
('2020-02-29', 50.02295812786353),
('2020-02-02', 32.110602593440134),
('2020-02-01', 28.02916666666667),
('2020-02-03', 25.438804286520025),
('2020-02-04', 22.365657421674385),
('2020-02-05', 16.073480316579307),
('2020-02-07', 14.248953648036817),
('2020-02-06', 11.669101196033964),
('2020-02-21', 9.977065490689725),
('2020-02-11', 9.35837063553491),
('2020-02-10', 9.010339252962567),
('2020-02-23', 8.87058515561742),
('2020-02-17', 7.2659448864102245),
('2020-02-22', 7.240816274724807),
('2020-02-18', 5.6922594618032605),
('2020-02-20', 4.803068499181165),
('2020-02-09', 3.533039880381679),
('2020-02-19', 2.08935529541489)]
方法二做题思路及解析:
# 方法二:请为我解析这段代码:#### Q3. 在订单数据集中,计算北京和上海的累计平均订单金额这一指标,两地这一指标差距最大的日期是几号?
query = '''
WITH tmp AS
(
SELECT
"收货地址 " AS address
,"订单创建日期" AS order_date
,SUM("总金额") AS daily_total
,COUNT("总金额") AS daily_order_count
FROM example_table
WHERE "收货地址 " IN ('北京','上海')
GROUP BY "收货地址 ","订单创建日期"
)
,tmp1 AS
(
SELECT
order_date
,SUM(daily_total) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_daily_total
,SUM(daily_order_count) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_order_counts
,address
FROM tmp
)
,tmp2 AS
(
SELECT
order_date
/*
思路:
因为不需要知道是个城市,所以只需要对于 order_date 分组,得出每组下的差值(值 - 最小值 >= 0)
*/
,cum_daily_total/cum_order_counts - min(cum_daily_total/cum_order_counts) OVER(PARTITION BY order_date) AS margin
FROM tmp1
)
SELECT order_date
,margin
FROM tmp2
ORDER BY margin DESC
--limit 1;
'''
result = connection.execute(query).fetchall()
result
[('2020-02-24', 87.65238560257924),
('2020-02-25', 74.52541065913273),
('2020-02-26', 64.39660004168617),
('2020-02-27', 60.138257495841316),
('2020-02-28', 53.690752194786185),
('2020-02-29', 50.02295812786353),
('2020-02-02', 32.110602593440134),
('2020-02-01', 28.02916666666667),
('2020-02-03', 25.438804286520025),
('2020-02-04', 22.365657421674385),
('2020-02-05', 16.073480316579307),
('2020-02-07', 14.248953648036817),
('2020-02-06', 11.669101196033964),
('2020-02-21', 9.977065490689725),
('2020-02-11', 9.35837063553491),
('2020-02-10', 9.010339252962567),
('2020-02-23', 8.87058515561742),
('2020-02-17', 7.2659448864102245),
('2020-02-22', 7.240816274724807),
('2020-02-18', 5.6922594618032605),
('2020-02-20', 4.803068499181165),
('2020-02-09', 3.533039880381679),
('2020-02-19', 2.08935529541489),
('2020-02-01', 0.0),
('2020-02-02', 0.0),
('2020-02-03', 0.0),
('2020-02-04', 0.0),
('2020-02-05', 0.0),
('2020-02-06', 0.0),
('2020-02-07', 0.0),
('2020-02-09', 0.0),
('2020-02-10', 0.0),
('2020-02-11', 0.0),
('2020-02-13', 0.0),
('2020-02-14', 0.0),
('2020-02-17', 0.0),
('2020-02-18', 0.0),
('2020-02-19', 0.0),
('2020-02-20', 0.0),
('2020-02-21', 0.0),
('2020-02-22', 0.0),
('2020-02-23', 0.0),
('2020-02-24', 0.0),
('2020-02-25', 0.0),
('2020-02-26', 0.0),
('2020-02-27', 0.0),
('2020-02-28', 0.0),
('2020-02-29', 0.0)]
这段SQL代码旨在计算北京和上海在不同日期的累计平均订单金额,并找出两城市间累计平均订单金额差距最大的日期。我将逐步解析这段代码:
代码解析
-
临时表
tmp:- 这个临时表从
example_table中选择了地址为北京或上海的订单。 - 对每个地址和日期组合,它计算了当天的总金额(
SUM("总金额"))和订单数量(COUNT("总金额"))。 - 这个步骤是为了准备计算每个地址每天的累计平均订单金额。
- 这个临时表从
-
临时表
tmp1:- 在
tmp1中,对tmp中的数据按地址分区,并按日期排序。 - 然后,计算每个地址到每个日期为止的累计总金额(
SUM(price) OVER...)和累计订单数(SUM(orders) OVER...)。 - 这步是关键,因为它提供了计算累计平均订单金额所需的累计值。
- 在
-
临时表
tmp2:-
累计平均订单金额:首先,对于每个城市的每个日期,计算其累计平均订单金额(
cum_price / cum_orders)。 -
计算差异(
margin):然后,从这个累计平均订单金额中减去同一日期下所有城市中最小的累计平均订单金额。这是通过MIN(cum_price / cum_orders) OVER (PARTITION BY order_date)来实现的,它在同一日期内找到最小的累计平均订单金额。 -
得到的
margin:因此,margin代表的是在特定日期内,每个城市的累计平均订单金额与当天最小累计平均订单金额之间的差距。 -
这个过程的目的是为了找出哪天这两个城市(北京和上海)在累计平均订单金额上的差距最大。
-
通过这种方式,我们能够了解每个日期中两城市累计平均订单金额的相对差距,而不仅仅是两城市间直接的差异。
-
最终,通过降序排列
margin,我们可以找出差异最大的那天,也就是两城市间累计平均订单金额差距最大的日期。
-
-
最终查询:
- 从
tmp2中选择日期和差异值,然后按差异值降序排序。 - 这样可以找到累计平均订单金额差距最大的那一天。
- 从
需要注意的地方
- 差值计算逻辑:这个查询计算的是两城市间每天的累计平均订单金额的差异,而不是绝对差值。它使用的是“差值 - 当天两城市中较小的累计平均订单金额”,这可能不是您期望的绝对差异计算方式。
- 处理数据缺失:如果某一天某个城市没有订单,这种方法可能会导致计算错误或不准确的结果。在实际应用中,需要考虑这种情况并相应地调整查询。
最终,这个查询将返回差异值最大的日期和相应的差异值。如果您希望计算的是两城市间的累计平均订单金额的绝对差值,那么可能需要对计算差值的方式进行修改。
两种方法关键代码解析(重要):
代码段1:
SELECT
address,
order_date,
SUM(daily_total) OVER(PARTITION BY address ORDER BY order_date) /
SUM(daily_count) OVER(PARTITION BY address ORDER BY order_date) AS cumulative_avg_payment
FROM DailyAvgPayments
代码段2:
SELECT
address,
order_date,
SUM(daily_total) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_daily_total,
SUM(daily_count) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_order_counts
FROM DailyAvgPayments
在SQL的窗口函数中,如果没有明确指定窗口的范围,那么默认的窗口范围就是 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。这意味着窗口将包括从分区的开始(即最早的行)到当前行的所有行。
在您提供的两段代码中:
- 代码段1没有明确指定窗口范围,但它默认使用的就是
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。 - 代码段2则明确指定了相同的窗口范围。
因此,即使代码段1中省略了这个部分,它的行为和代码段2在计算累计数据时是一样的。这个默认行为使得窗口函数可以更简洁地编写,同时仍然保持清晰和直观。
# ...your code...
a3 = '24' # 在 '' 中填入你的结果,如 a3 = '1'
Q4: 在 Q3 的数据中,北京有多少天的数据是高于上海的?
方法一做题思路及解析:
query4 = '''
WITH DailyAvgPayments AS (
SELECT
"收货地址 " AS address,
"订单创建日期" AS order_date,
SUM("总金额") AS daily_total,
COUNT("订单编号") AS daily_order_count
FROM example_table
WHERE "收货地址 " in ('北京', '上海')
GROUP BY "收货地址 ", "订单创建日期"
),
CumulativeAvgPayments AS (
SELECT
address,
order_date,
SUM(daily_total) OVER(PARTITION BY address ORDER BY order_date) /
SUM(daily_order_count) OVER(PARTITION BY address ORDER BY order_date) AS cumulative_avg_payment
FROM DailyAvgPayments
),
BeijingData AS (
SELECT order_date, cumulative_avg_payment
FROM CumulativeAvgPayments
WHERE address = '北京'
),
ShanghaiData AS (
SELECT order_date, cumulative_avg_payment
FROM CumulativeAvgPayments
WHERE address = '上海'
),
Comparison AS (
SELECT
BeijingData.order_date,
CASE
WHEN BeijingData.cumulative_avg_payment > ShanghaiData.cumulative_avg_payment THEN 1
ELSE 0
END AS Beijing_higher
FROM BeijingData
JOIN ShanghaiData ON BeijingData.order_date = ShanghaiData.order_date
)
SELECT COUNT(*)
FROM Comparison
WHERE Beijing_higher = 1;
'''
result = connection.execute(query4).fetchall() # [(122131,)]
result[0][0]
4
这个查询首先在DailyAvgPayments中为每个地址和每个日期计算了日均总额和订单数。然后,在CumulativeAvgPayments中计算每个地址到每个日期为止的累计平均订单金额。之后的步骤与之前相同,比较北京和上海的累计平均订单金额,最后统计北京高于上海的天数。这样可以确保每个日期只被计算一次。
方法二做题思路及解析:
# 方法二:请为我解析这段代码:### Q4: 在 Q3 的数据中,北京有多少天的数据是高于上海的?
query = '''
WITH tmp AS
(
SELECT
"收货地址 " AS address
,"订单创建日期" AS order_date
,SUM("总金额") AS price
,COUNT("总金额") AS orders
FROM example_table
WHERE "收货地址 " IN ('北京','上海')
GROUP BY "收货地址 ","订单创建日期"
)
,tmp1 AS
(
SELECT
order_date
/*
按照 address 字段计算 累积总金额 (cum_price) 和 累积总订单数 (cum_orders)
*/
,SUM(price) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_price
,SUM(orders) OVER(PARTITION BY address ORDER BY order_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cum_orders
,address
FROM tmp
)
,tmp2 AS
(
SELECT
order_date
,address
/*
代码设计思路:
1. cum_price/cum_orders 是我们要计算的指标,下面简称【指标 A】
2. min(cum_price/cum_orders)... : 我们在两个城市当中选择该指标较小的值,如果这个值和当前行的值是一样的,说明这一行是“小”的值
,反之,如果两个值不一样,说明当前行的值时两个比较值中较大的
3. FILTER(WHERE address<>"北京") 并不是必须的,其主要目的是为了让输出的结果可以更好的被引用(可以去掉这个 FILTER 看看效果)
4. 在 min 聚合函数当中只保留 “上海” 的数据,意味着只要 北京>上海,则输出结果一定为 > 0 【且】 “上海”的结果一定为 0
5. 这样我们可以通过 a. 筛选地址 b.筛选数值 的形式得出我们要的结果
6. 同时,也可以直接通过排序 (ORDER BY) 来获得结果,不使用 FILTER 的话,上海 > 北京 部分的数据会扰乱排序
*/
,cum_price/cum_orders - min(cum_price/cum_orders) FILTER(WHERE address <> "北京") OVER(PARTITION BY order_date) AS bj_is_large
FROM tmp1
ORDER BY cum_price/cum_orders - min(cum_price/cum_orders) FILTER(WHERE address <> "北京") OVER(PARTITION BY order_date) DESC
)
SELECT *
FROM tmp2
WHERE bj_is_large>0
'''
result = connection.execute(query).fetchall()
result
[('2020-02-21', '北京', 9.977065490689725),
('2020-02-23', '北京', 8.87058515561742),
('2020-02-22', '北京', 7.240816274724807),
('2020-02-20', '北京', 4.803068499181165)]
这段SQL代码的目的是在北京和上海的订单数据集中计算每一天北京的累计平均订单金额是否高于上海,并且返回所有日期及其相应的比较结果。我将逐步解析这段代码:
代码解析
-
临时表
tmp:- 这个临时表从
example_table中选取了地址为北京或上海的订单。 - 对每个地址和日期组合,它计算了当天的总金额(
SUM("总金额"))和订单数量(COUNT("总金额"))。 - 这是为了准备计算每个地址每天的累计平均订单金额。
- 这个临时表从
-
临时表
tmp1:- 在
tmp1中,对tmp中的数据按地址分区,并按日期排序。 - 然后,计算每个地址到每个日期为止的累计总金额(
SUM(price) OVER...)和累计订单数(SUM(orders) OVER...)。 - 这为每个地址的每一天提供了累计平均订单金额的所需数据。
- 在
-
临时表
tmp2:tmp2的目的是比较北京和上海在每个日期的累计平均订单金额。- 通过计算
cum_price/cum_orders - min(cum_price/cum_orders) FILTER(WHERE address <> "北京") OVER(PARTITION BY order_date),可以得到每天北京累计平均订单金额是否高于上海。 - 这里的关键是使用
FILTER子句来确保min函数只考虑上海的数据。这意味着如果计算结果大于0,则表示北京的累计平均订单金额高于上海。
-
最终查询:
- 选择了日期、地址以及北京是否高于上海的比较结果。
- 注释掉的
WHERE bj_is_large>0可以用来过滤出北京高于上海的日期,但在您提供的查询中,这一行是被注释掉的。
注意点
- 逻辑和解释:这个查询的核心在于比较每天北京和上海的累计平均订单金额。如果北京高于上海,则
bj_is_large的值为正数;如果低于或等于上海,则为0或负数。 FILTER子句的作用:FILTER(WHERE address <> "北京")确保在计算最小累计平均订单金额时只考虑上海的数据,这是比较逻辑的关键部分。- 结果解释:最终的结果将展示每一天的日期、地址和
bj_is_large的值,显示北京是否高于上海。如果要仅显示北京高于上海的天数,可以取消注释WHERE bj_is_large>0。
总的来说,这段代码有效地比较了北京和上海每天的累计平均订单金额,并可以通过调整查询来获得北京高于上海的具体天数。
# ...your code...
a4 = '4' # 在 '' 中填入你的结果,如 a4 = '100'














 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









