






如何将一个mp3音频分成两个?在现代数字音频处理中,将一个MP3音频文件分成两个部分是一种常见的需求。这种操作通常出现在需要剪辑、编辑音频的场景中,无论是为了创建铃声、制作音乐混音,还是简单地从一段音频中提取特定部分。这篇文章将探讨如何实现这一操作以及其应用场景。首先,MP3是一种广泛使用的音频格式,其压缩算法使得文件相对较小,同时保持了高质量的音频表现。然而,有时候我们可能只需要音频中的某一部分,或者想要将其分割成多个独立的部分以便于个别处理或整合到其他作品中。
应广大粉丝朋友的请求,小编今天将为大家介绍几个将MP3音频分割成两个的办法,每个方法都有详细的教程,相信对大家是有很大帮助的,赶紧试一试吧。

方法一:使用“星优音频助手”软件将mp3分成两个
软件下载地址:https://www.xingyousoft.com/softcenter/XYAudio
步骤1,本次操作开始前请大家将用到的“星优音频助手”这个软件下载好并进行安装,随后打开软件到首页,并点击首页里的【音频分割】功能选项。
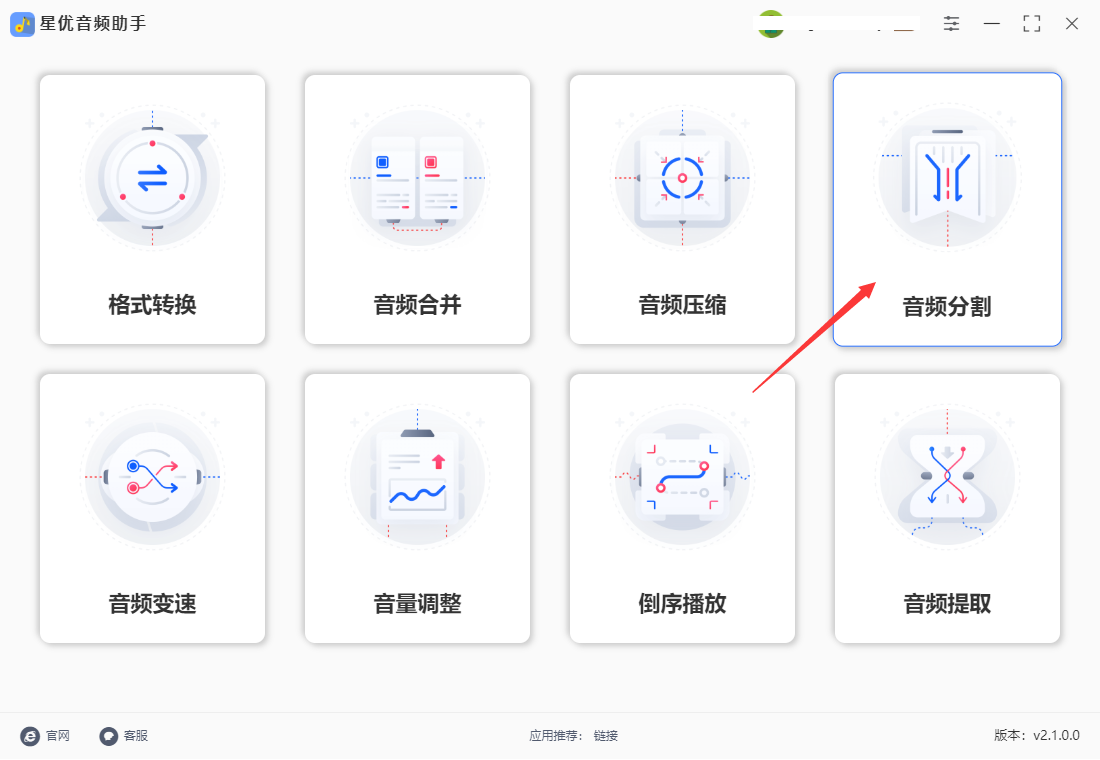
步骤2,跳转到音频分割的操作界面后,点击【添加文件】按钮,将需要分割的mp3音频文件添加到软件里。当然软件是支持批量处理的。
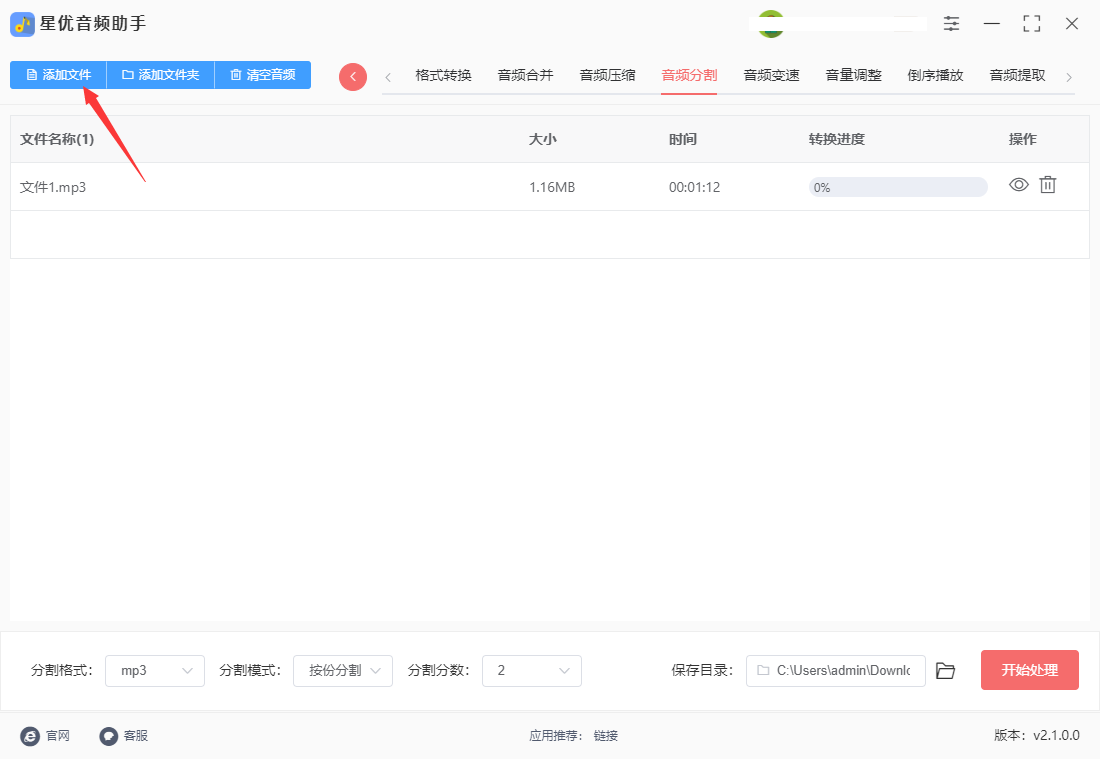
步骤3,先设置分割后的格式,建议大家选择mp3,当然你也可以设置为其它格式。
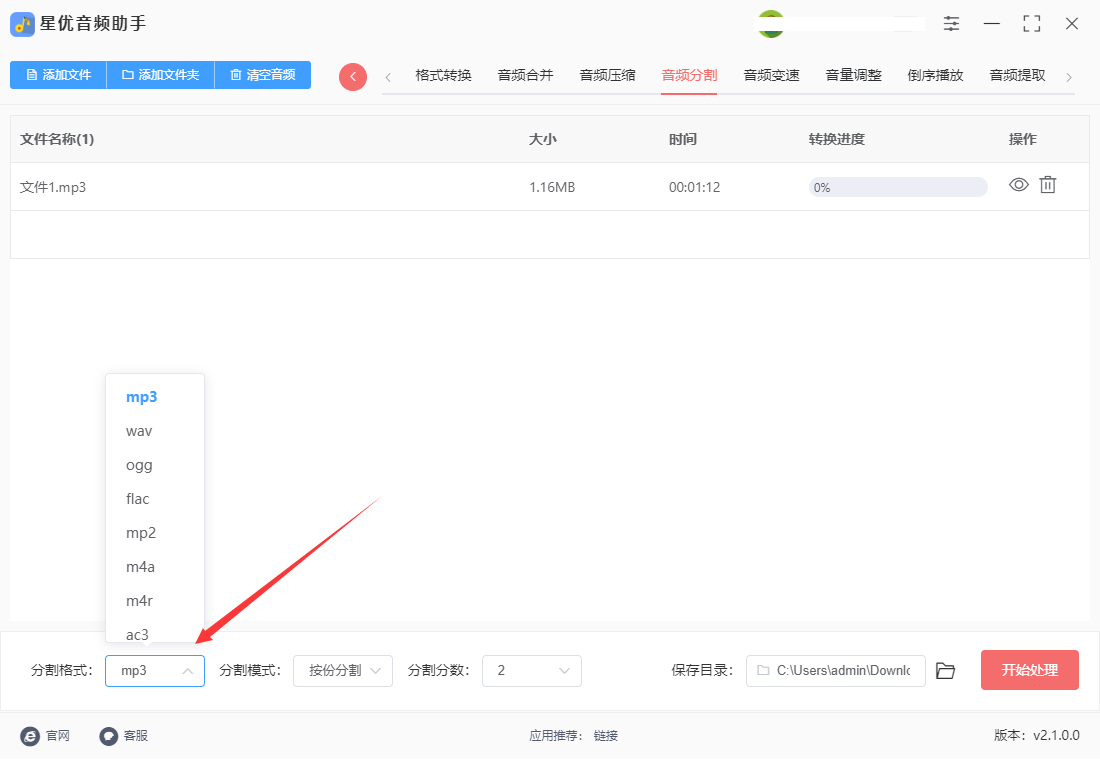
步骤4,然后设置分割模式,本次我们选择为“按份分割”;另外将分割分数设置为“2”。
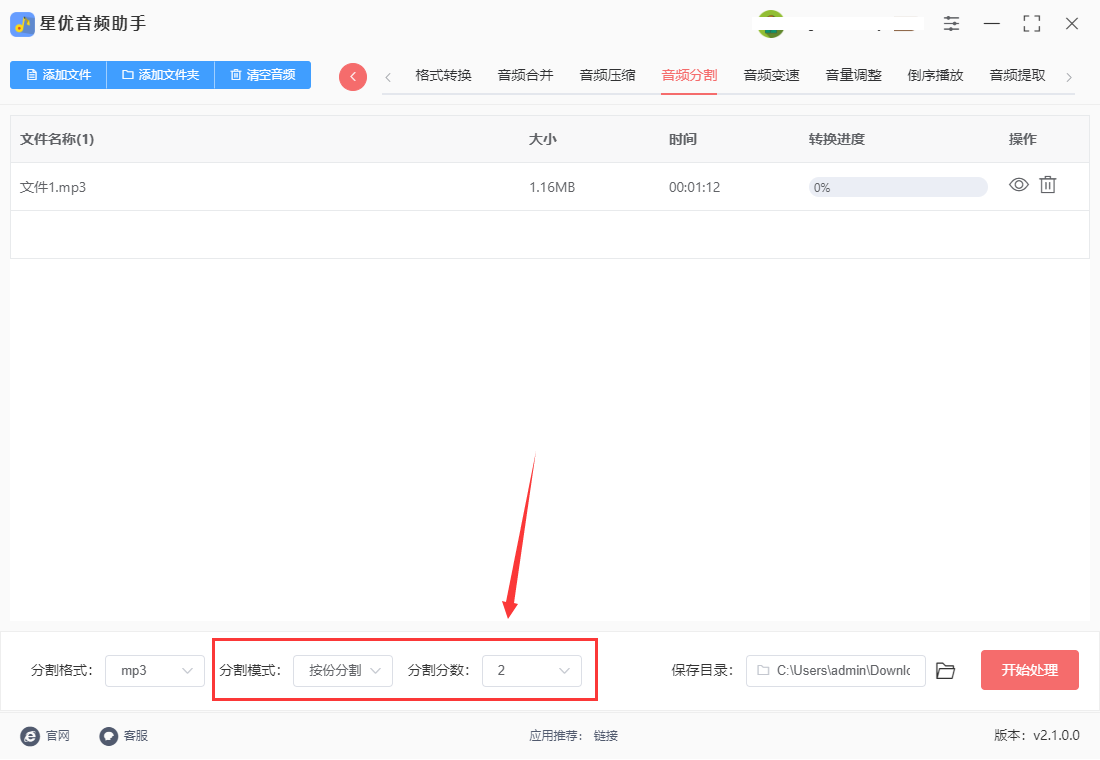
步骤5,设置结束后点击软件右下角【开始处理】红色按钮启动分割程序,分割速度是比较快的,分割结束后软件会立即打开保存文件夹,便于我们查看分割成的mp3音频文件。
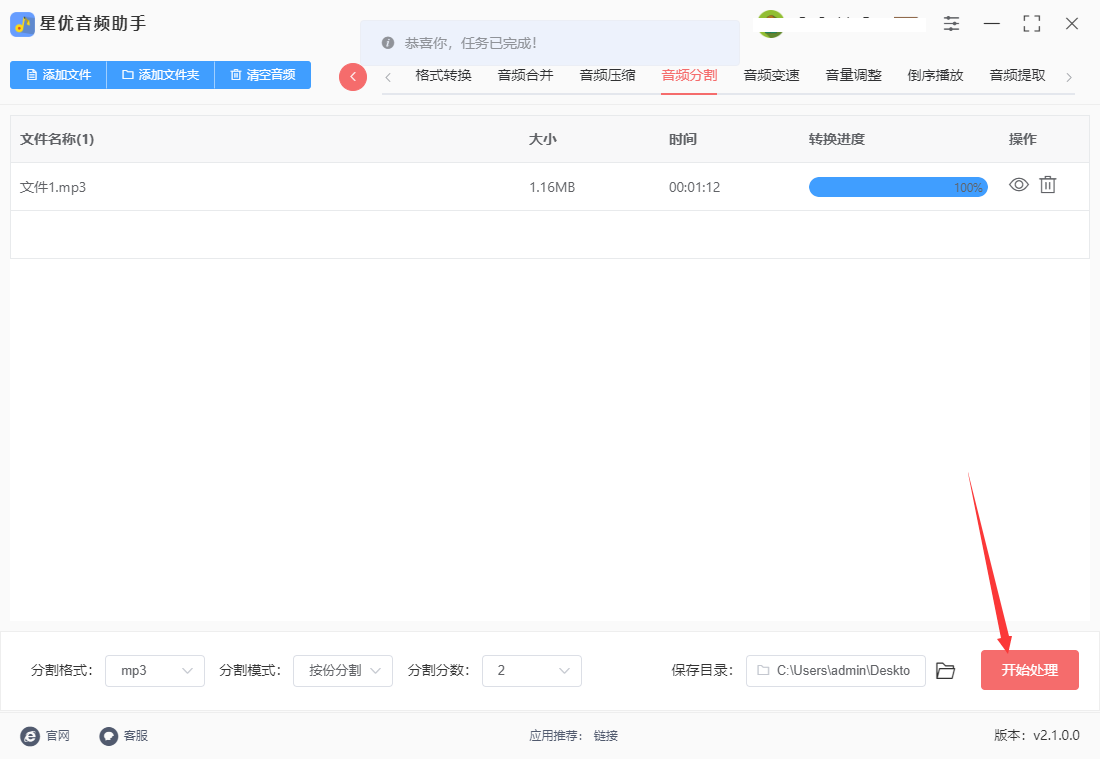
步骤6,随后从下图可以看到,本次操作中软件成帮助我们将一个mp3音频分割为了两个单独的mp3文件,证明方法使用正确。
方法二:使用小光音频转换器将mp3分成两个
步骤1,请大家在使用前将用到的这个音频软件下载好并进行安装,打开之后在左侧区域能够看到五个功能,请你点击其中的【音频分割】功能选项。
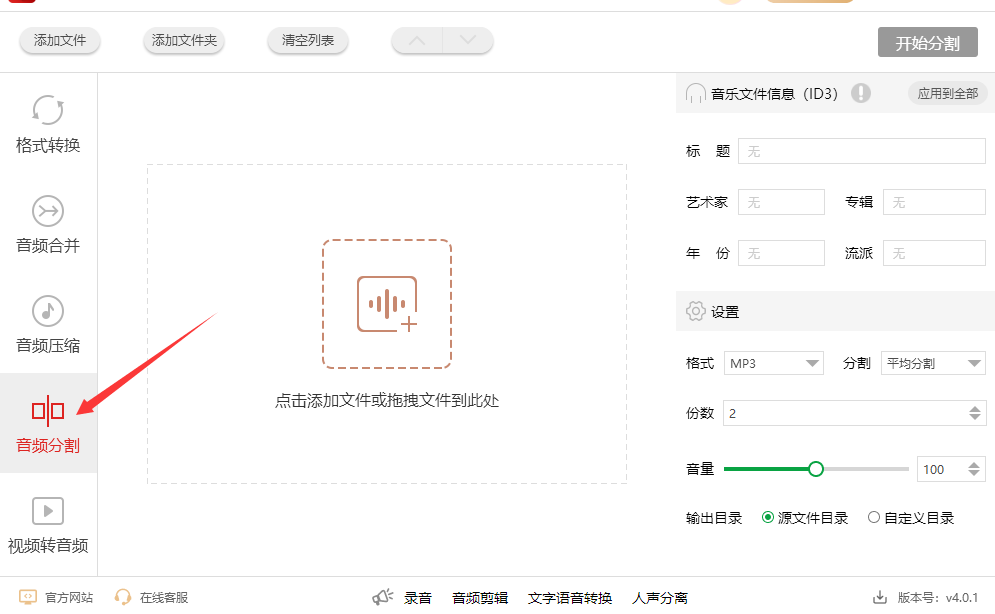
步骤2,将需要分割的mp3音频文件添加到软件里,你可以点击左上角“添加文件”按钮进行添加,也可以点击软件中间的图标进行添加。
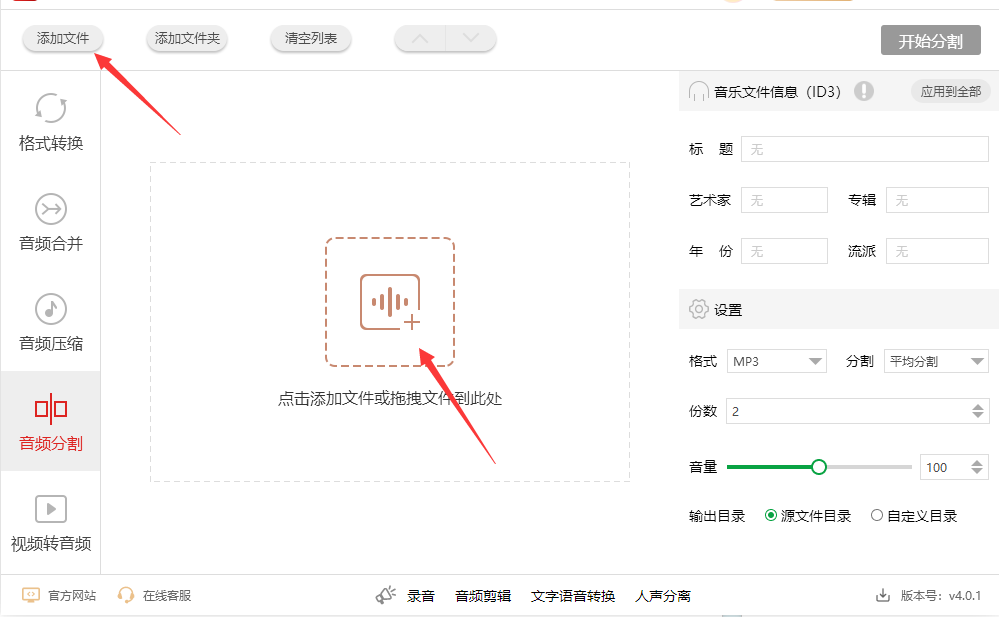
步骤3,右侧有很多的参数,我们只需要设置两个即可,先在分割右侧下拉框中选择“平均分割”;随后将分割后的份数设置为“2”。
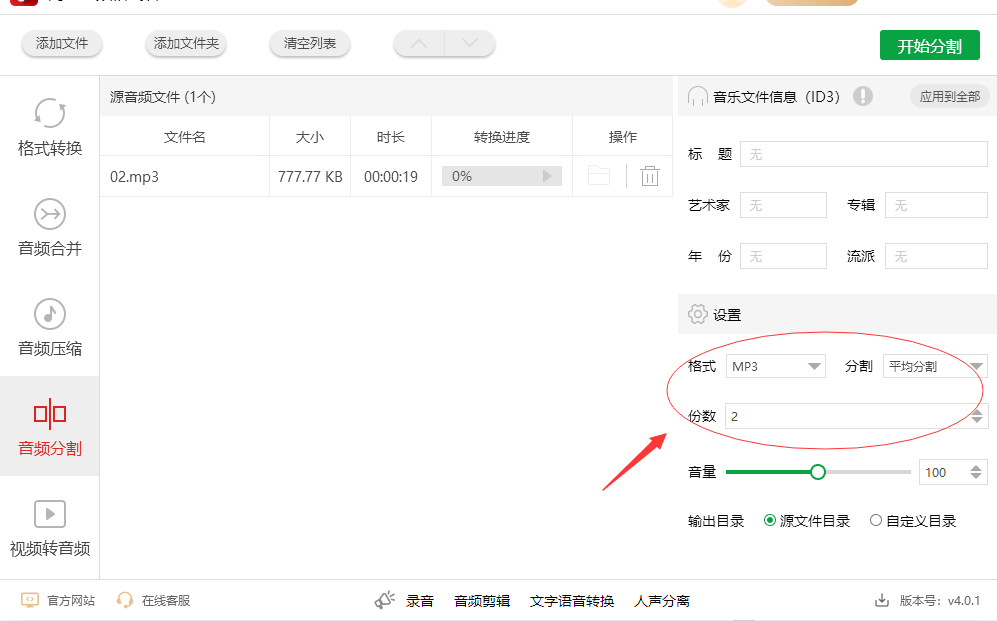
步骤4,这时候点击右上角【开始分割】按钮即可启动软件,软件便开始对mp3文件进行分割了 ,分割结束后会弹出一个提示框,点击提示框里的绿色功能按钮你可打开输出目录文件夹,在输出文件夹里可以找到分割后的mp3音频文件。
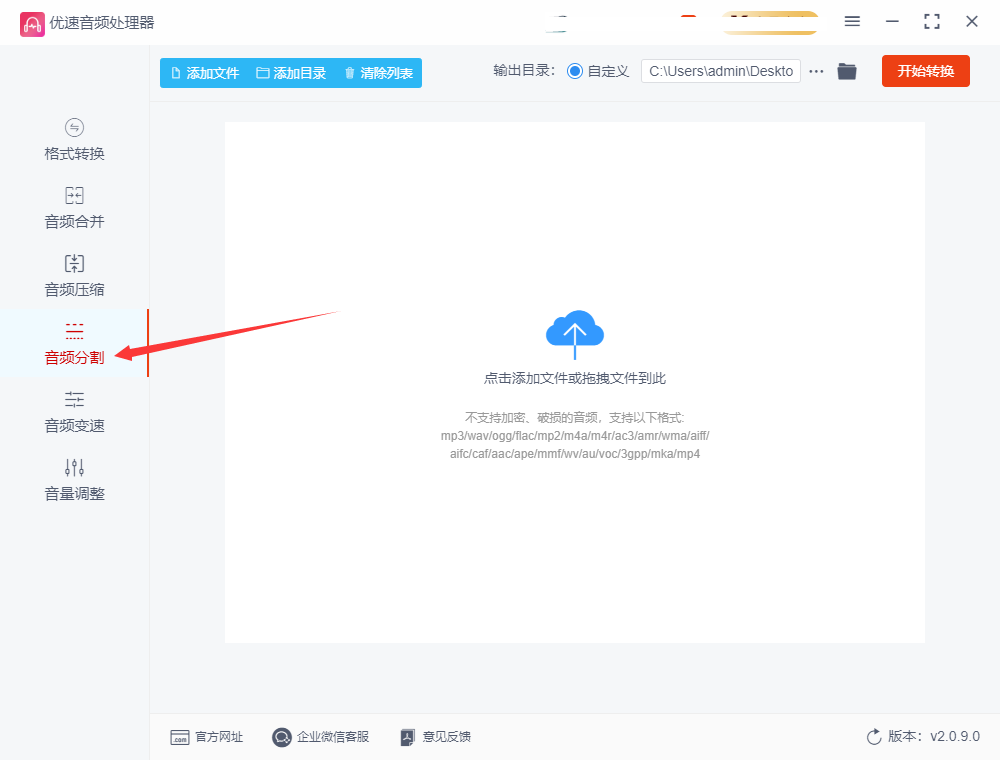
方法三:使用“优速音频处理器”软件将mp3分成两个
1、下载并安装软件
首先,确保你已经在电脑上下载并安装了优速音频处理器。可以从官方网站或可信的软件下载平台获取最新版本。
2、打开软件并选择功能
双击桌面上的优速音频处理器图标,打开软件。
在软件界面的左侧功能选项中,找到并点击“音频分割”功能。
3、添加音频文件
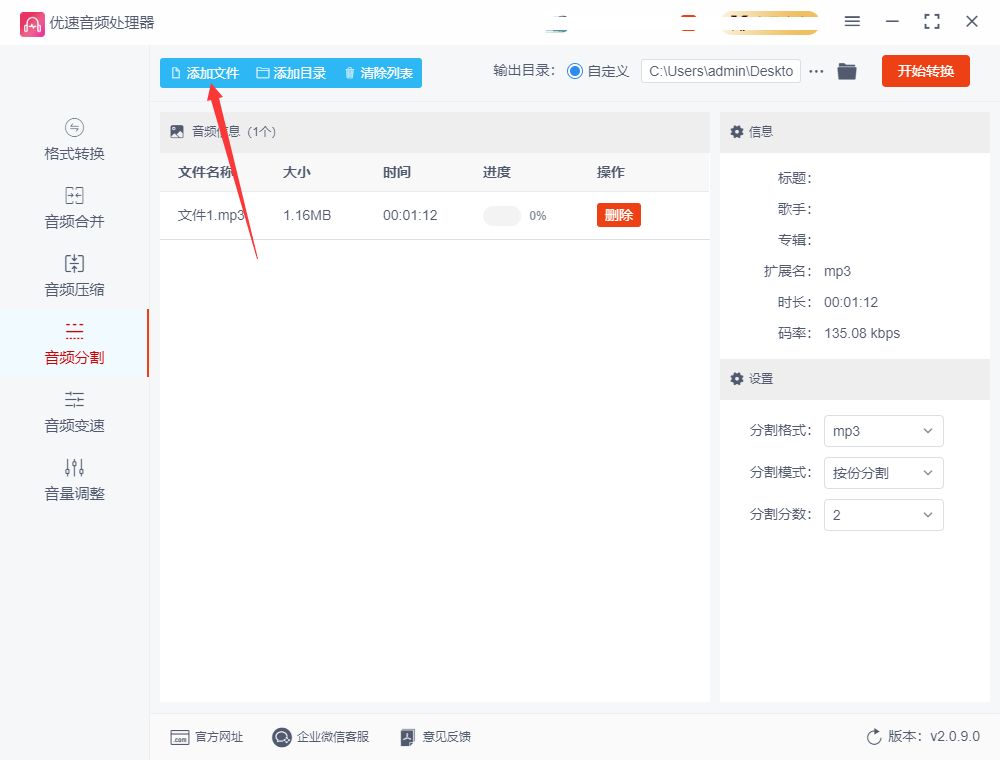
点击软件界面上的“添加文件”按钮,将需要分割的MP3音频文件上传到软件中。
你也可以通过拖拽的方式将文件直接添加到软件中。
4、设置分割参数
在文件添加完毕后,你需要设置分割参数。优速音频处理器支持多种分割方式,包括平均分割和按时长分割。
若要进行平均分割,选择“按份分割”作为分割模式,并在下方的设置框中填写分割份数“2”。
如果你希望按照特定的时长来分割音频,可以选择“按时长分割”并设置相应的时长。
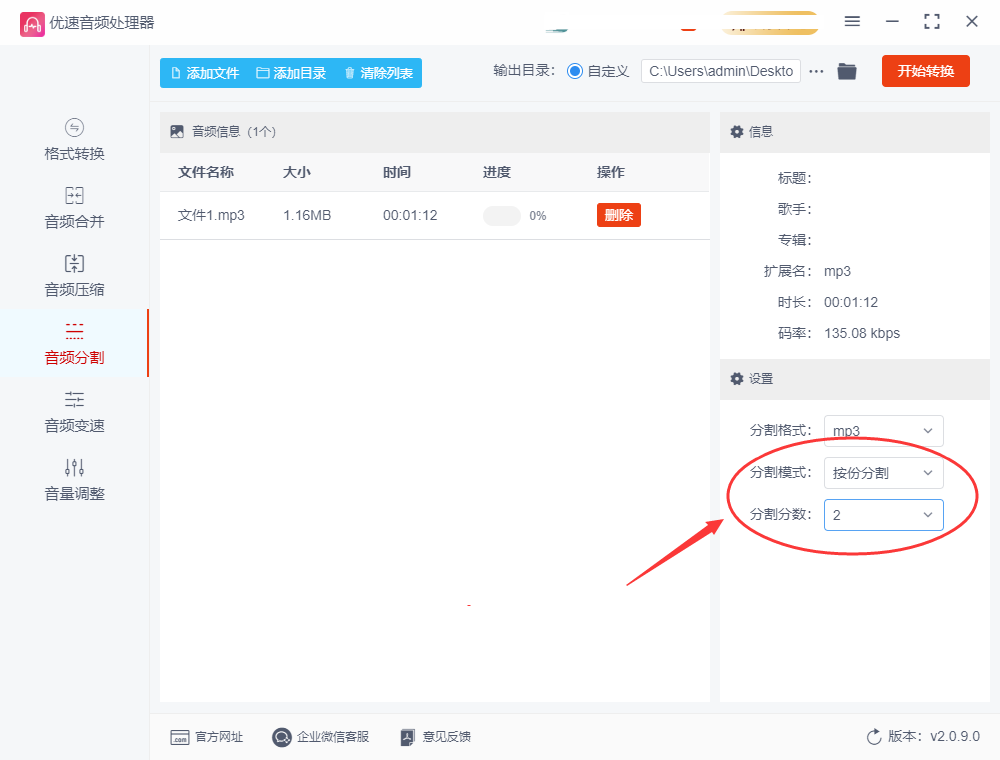
5、选择输出目录(可选)
在进行分割之前,你还需要设置输出目录,即分割后的音频文件保存的位置。
点击软件界面上的“输出目录”选项,选择一个合适的文件夹作为保存路径。
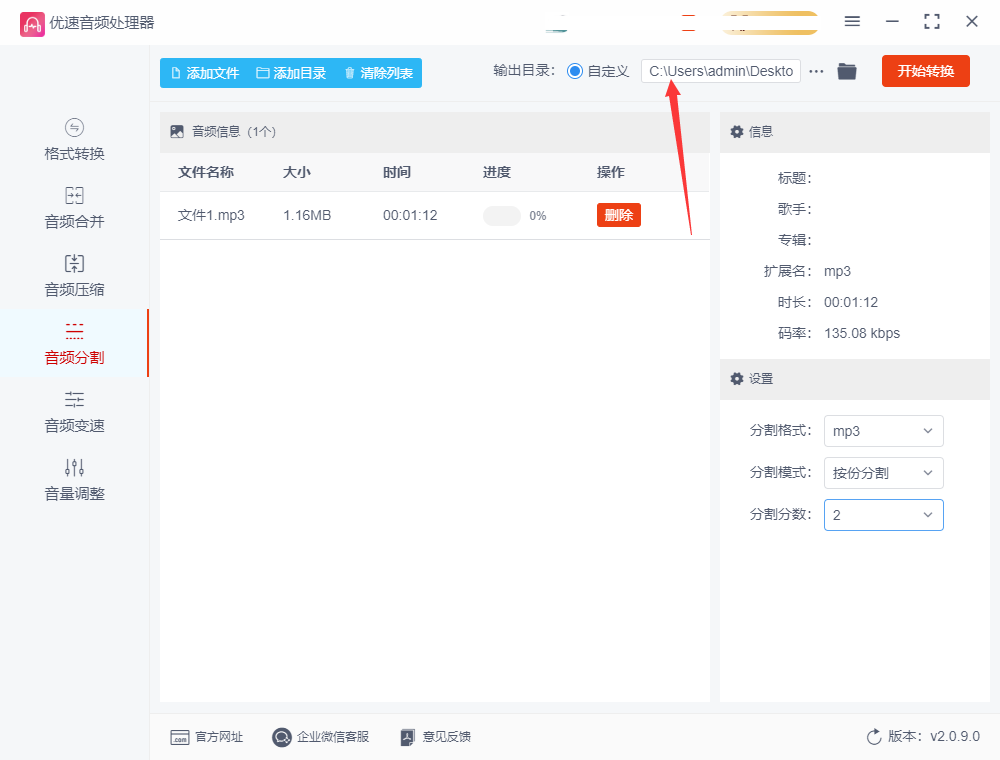
6、开始分割
设置完成后,点击软件界面上的“开始转换”或类似的按钮,启动分割程序。
分割过程可能需要一些时间,具体时间取决于音频文件的大小和电脑的性能。
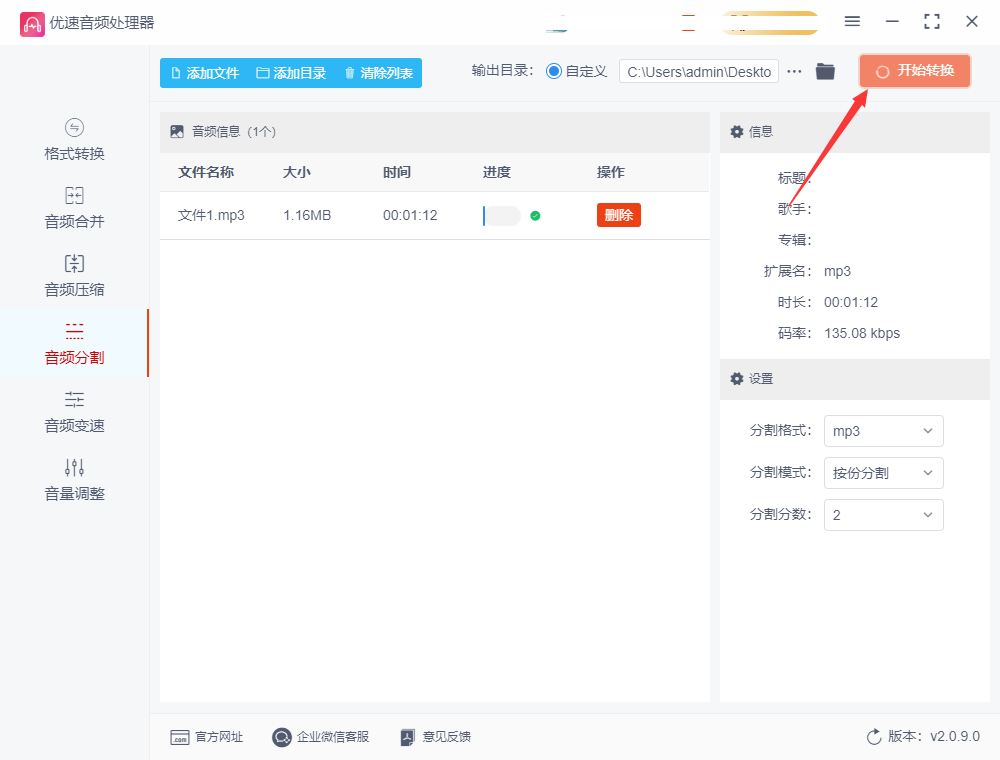
7、查看分割结果
分割完成后,软件会自动打开输出文件夹,你可以在其中找到已经分割好的音频文件。
确认分割结果无误后,你就可以根据需要对分割后的音频文件进行进一步处理或使用了。
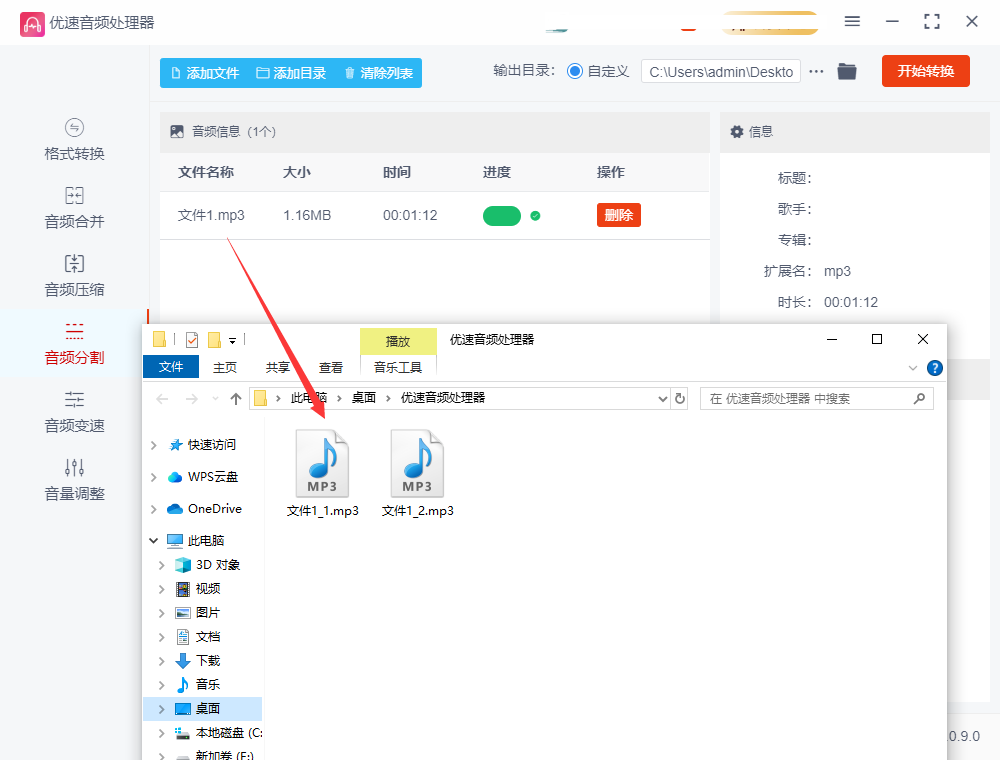
注意事项
在进行音频分割之前,请确保你的电脑已经连接了稳定的电源,以避免在分割过程中因电量不足而导致操作中断。
如果你对分割结果不满意,可以尝试调整分割参数并重新进行分割。
优速音频处理器还支持多种音频处理功能,如格式转换、合并、压缩等,你可以根据需要选择相应的功能进行操作。
方法四:使用FFmpeg命令将mp3分成两个
使用 FFmpeg 将一个 MP3 文件分割成两个部分是一个常见的任务,可以通过命令行完成。以下是详细的步骤:
1. 安装 FFmpeg
如果你还没有安装 FFmpeg,请先安装它。
① Windows:
下载 FFmpeg 的 Windows 版本 从官方网站。
解压下载的压缩包到一个目录。
将 FFmpeg 的 bin 目录添加到系统的环境变量 PATH 中,以便从命令行访问。
② macOS:
使用 Homebrew 安装 FFmpeg:
brew install ffmpeg
③ Linux:
使用包管理器安装 FFmpeg,例如在 Ubuntu 上:
sudo apt update
sudo apt install ffmpeg
2. 确定分割点
你需要决定要将 MP3 文件分割成两个部分的具体时间点。例如,假设你有一个名为 input.mp3 的文件,并且你想将它分割为两个部分:第一个部分从开始到 30 秒,第二部分从 30 秒到文件结束。
3. 使用 FFmpeg 分割 MP3 文件
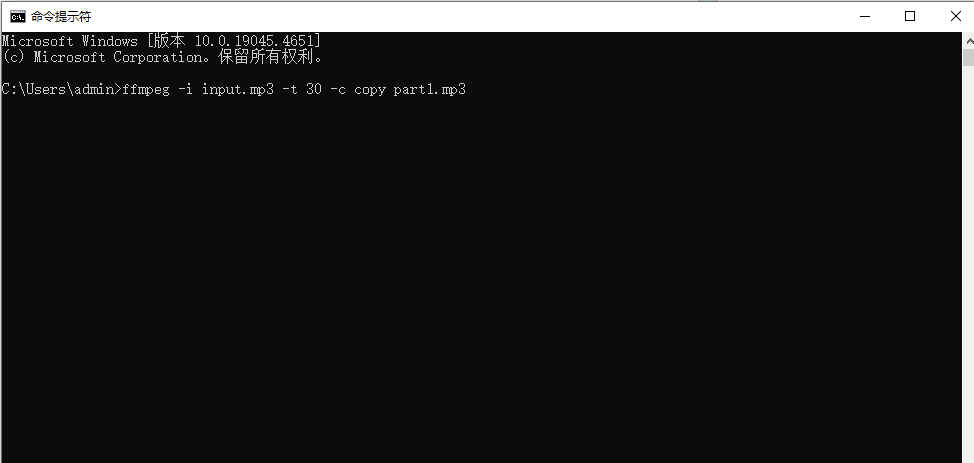
分割成第一个部分
打开终端或命令提示符,使用以下命令将 MP3 文件的前半部分分割出来。
ffmpeg -i input.mp3 -t 30 -c copy part1.mp3
-i input.mp3 指定输入文件。
-t 30 指定输出文件的持续时间为 30 秒。
-c copy 表示直接复制音频数据而不进行转码。
part1.mp3 是第一个分割出的部分的文件名。
分割成第二个部分
为了提取第二部分,你需要先确定文件的总时长。使用以下命令获取文件时长:
ffmpeg -i input.mp3
在输出信息中找到类似于 Duration: 00:01:00.00 的字段,这表示文件的总时长。例如,总时长为 1 分钟(60 秒)。
假设第二部分从 30 秒开始到文件结束,可以使用以下命令提取:
ffmpeg -i input.mp3 -ss 30 -c copy part2.mp3
-ss 30 指定从 30 秒开始提取。
-c copy 表示直接复制音频数据。
part2.mp3 是第二个分割出的部分的文件名。
4. 验证分割结果
分割完成后,你可以使用任何音频播放器来播放 part1.mp3 和 part2.mp3 文件,确认它们是否按照预期的时间段正确分割。
总结
安装 FFmpeg(如果尚未安装)。
确定分割点。
使用 FFmpeg 命令来分割 MP3 文件。
这些步骤可以帮助你将 MP3 文件分割成两个部分,满足你的需求。如果有进一步的问题或需要处理更复杂的音频分割任务,FFmpeg 提供了丰富的选项和功能,可以参考 FFmpeg 官方文档 进行深入学习。
方法五:使用Logic Pro X将mp3分成两个
Apple的专业音频制作软件,提供高端音频编辑、录制、混音和母带处理功能,具有丰富的虚拟乐器和插件。在Logic Pro X中分割MP3文件,可以按照以下步骤进行:
1. 打开Logic Pro X
启动Logic Pro X应用程序。
2. 创建新项目
在Logic Pro X中,选择“新建项目”。
3. 导入MP3文件
将MP3文件拖入工作区,或者使用“文件”>“导入”>“音频文件”来导入你的MP3。
4. 将音频添加到轨道
将导入的MP3拖到时间轴上的音频轨道。
5. 定位分割点
在时间轴上找到你要分割的位置。可以使用播放头或设置标记来帮助定位。
6. 分割音频
选择音频轨道上的MP3文件,然后按Command + T键,或者在顶部菜单中选择“编辑”>“剪切”来进行分割。
7. 导出分割后的音频
导出第一个部分:
选择分割后的第一部分,点击“文件”>“导出”>“所选区域为音频文件”,然后选择MP3格式和保存位置。
导出第二部分:
选择第二部分,重复上述导出步骤,将其保存为另一个MP3文件。
8. 保存项目(可选)
如果需要,可以保存你的Logic Pro X项目,以便以后继续编辑。
将MP3音频分成两个或多个部分的应用场景广泛:音乐制作人常常需要从长音轨中提取特定的音频段落或者将不同的音频片段进行组合和混音。在录音室或者广播节目中,编辑人员可能需要剪辑主持人或嘉宾的讲话,去除噪音或者提取高亮片段。教育工作者可以根据课程需要,从录制的音频教材中提取出关键的教学片段,以便于学生的学习和复习。将MP3音频文件分成两个或多个部分,不仅提升了音频处理的灵活性和效率,还拓展了其在不同领域的应用。随着音频处理技术的进步和软件工具的普及,用户可以更加方便地实现对音频内容的精确控制和个性化定制。这种技术不仅适用于专业音频工作者,也能够为普通用户带来更多创意和娱乐体验的可能性。那么今天关于“如何将一个mp3音频分成两个?”的音频处理技巧分享就全部到这里了,学会了的小伙伴一定要点赞支持一下哦。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









