






如何批量提取pdf文件名到excel?在现代职场中,处理大量PDF文件是一项常见的任务。这些文件可能包括合同、报告、发票等,归档和管理这些文件的工作常常耗费时间和精力。批量提取PDF文件名到Excel是一个高效的解决方案,可以帮助我们更好地整理和检索文件信息。本文将介绍如何在工作中实现这一过程,以提高工作效率。背景与需求:当你需要管理数百个或数千个PDF文件时,手动记录每个文件的名称既繁琐又容易出错。将所有文件名提取到一个Excel表格中,可以让你迅速浏览文件列表、进行批量操作或进行数据分析。因此,自动化这个过程能够显著提升工作效率和准确性。
下面小编将为大家分享一些包含文件名批量提取功能的软件或者工具,可以帮助我们将大量pdf文件提取到excel表格里,相信这些详细的操作步骤可以帮助你快速学会。

方法一:利用“星优文件名管理器”软件批量提取pdf文件名
软件下载地址:https://www.xingyousoft.com/softcenter/XYRename
步骤1,绝大多数小伙伴是第一次使用“星优文件名管理器”软件,第一次使用是需要将软件下载并安装到电脑上的,安装结束后运行使用,然后点击【文件名提取】功能选项。

步骤2,将需要提取名称的pdf文件准备好,然后点击左上角【添加文件】或者【添加目录】功能按键,随后将准备好的pdf文件导入到软件里,导入成功后会生成文件名列表。
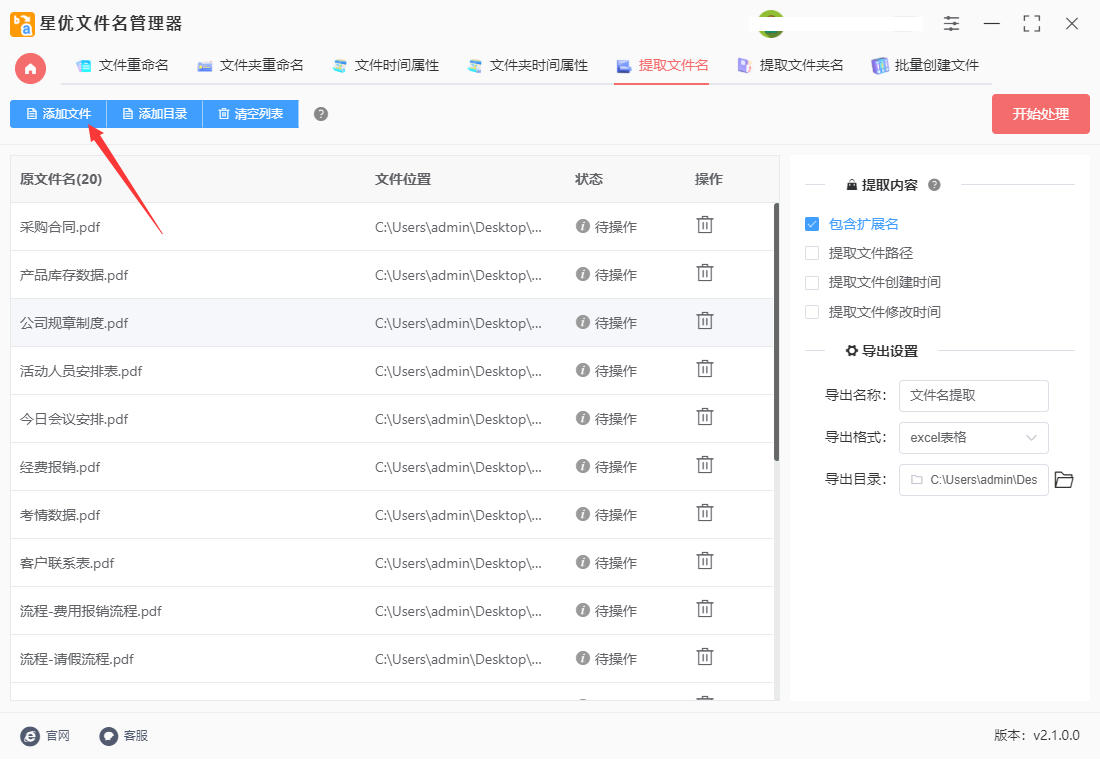
步骤3,提取内容下面有四个选项,如果有提取需要就勾选,没有的话就不要勾选;因为文件名要提取到excel,所以在导出格式右侧选择“excel表格”,此外导出格式还支持word和txt。
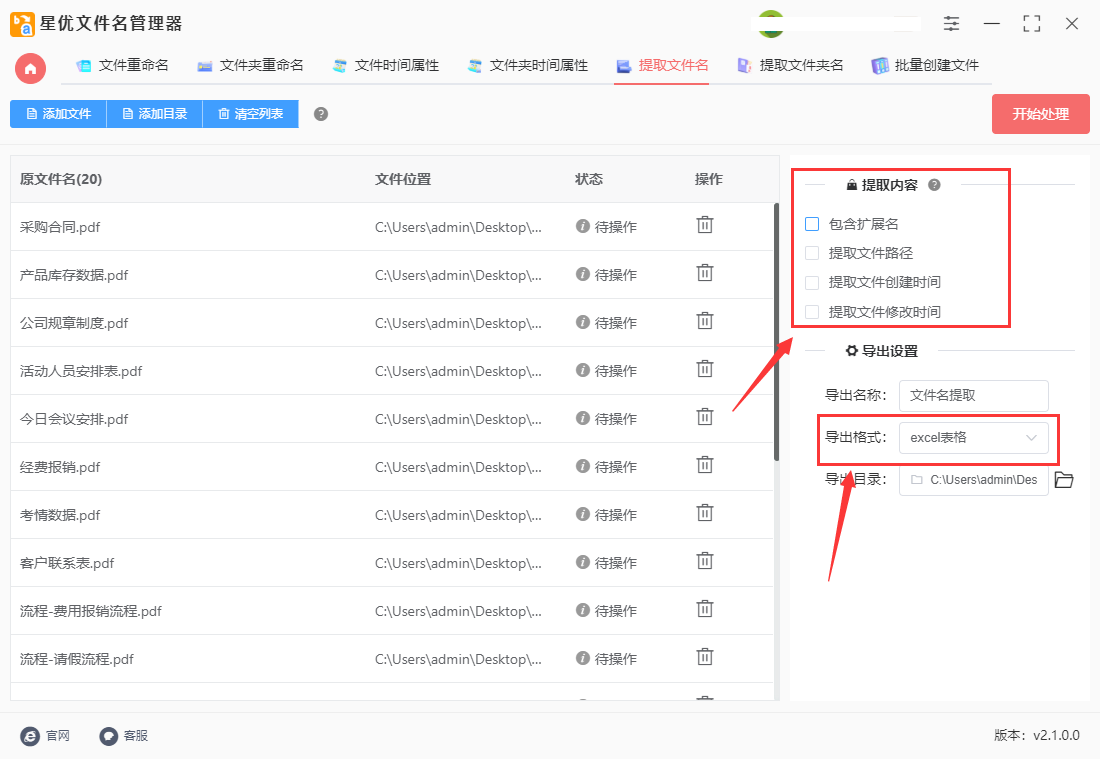
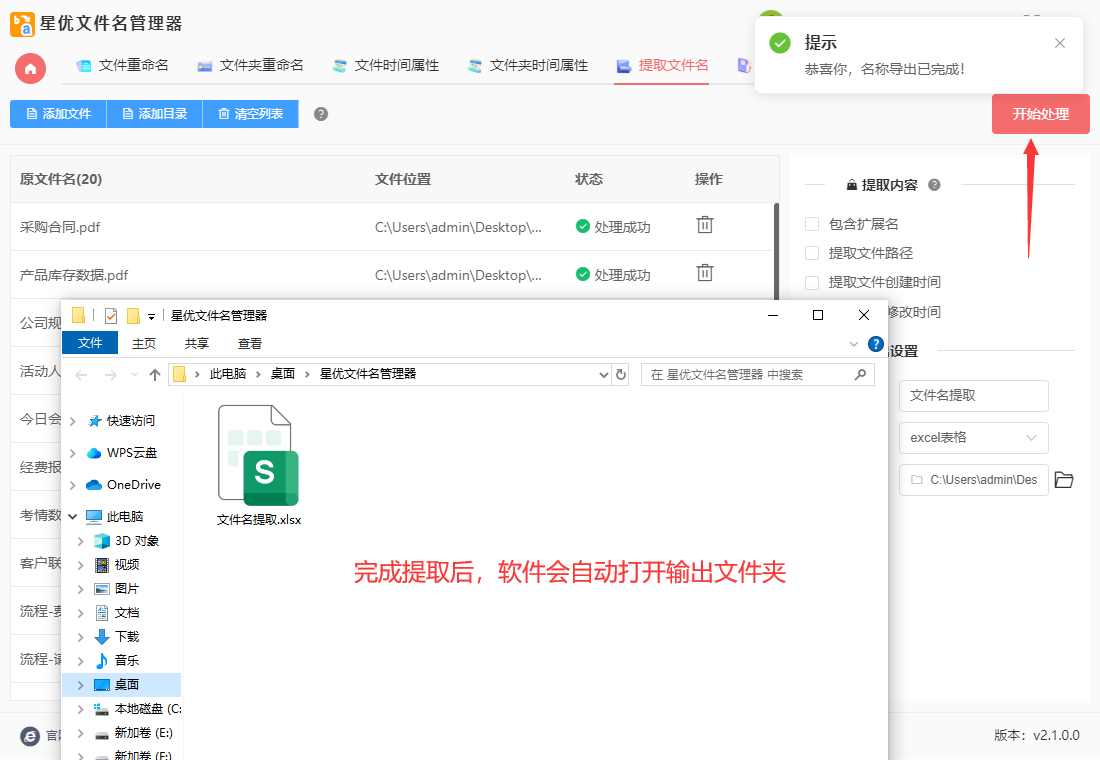
步骤4,完成设置后点击【开始处理】红色按钮,软件便开始启动文件名批量提取程序了,提取完毕后软件会打开保存文件夹,提取后的excel导出文件就保存在这里。
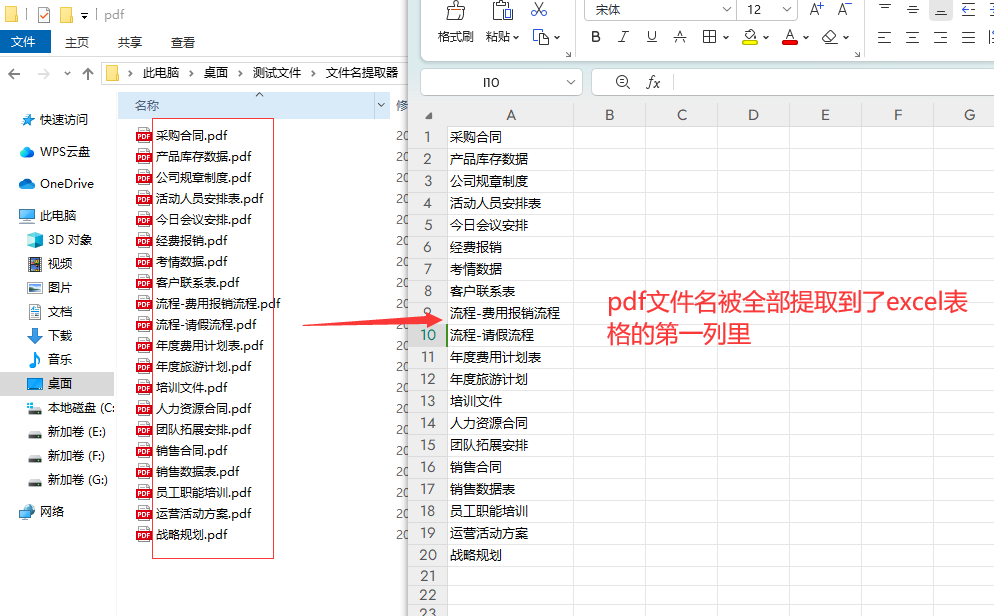
步骤5,打开刚刚导出的excel文件,通过对比可以看到,所有pdf文件的名称按照从上到下的顺序被批量提取到了excel表格的第一列里,一键批量提取效率非常高。
方法二:使用Python脚本
Python是一种强大的编程语言,能够帮助我们轻松完成这个任务。以下是一个简洁而有效的Python脚本,能够批量提取PDF文件名并将其保存到Excel中。
步骤1:安装必要的工具
首先,确保你的计算机上安装了Python和相关库。如果尚未安装,可以通过Python官方网站下载安装包。接下来,通过命令行安装pandas库:
pip install pandas openpyxl
步骤2:编写脚本
打开你的Python编辑器,创建一个新的Python文件,例如extract_pdf_names.py。在文件中输入以下代码:
import os
import pandas as pd
# 设定PDF文件所在的文件夹路径
folder_path = '指定你的PDF文件夹路径'
# 列出所有文件
files = os.listdir(folder_path)
# 过滤出PDF文件
pdf_files = [file for file in files if file.endswith('.pdf')]
# 将文件名列表转为DataFrame
df = pd.DataFrame(pdf_files, columns=['File Name'])
# 将DataFrame保存为Excel文件
output_path = 'pdf_file_names.xlsx'
df.to_excel(output_path, index=False)
print(f'文件名已成功保存到 {output_path}')
在这段代码中:
os.listdir(folder_path) 用于获取指定目录中的所有文件。
pdf_files 列表中存储了所有以.pdf结尾的文件名。
使用pandas.DataFrame将这些文件名转换为表格格式。
df.to_excel(output_path, index=False) 将数据导出为Excel文件,不包含行索引。
步骤3:执行脚本
保存并运行脚本,终端中输入:
python extract_pdf_names.py
运行后,Excel文件pdf_file_names.xlsx将生成在指定目录,里面包含了所有PDF文件的名称。

方法三:手动批量复制
1、打开文件夹:
进入包含PDF文件的文件夹。
2、选择所有PDF文件:
按 Ctrl + A 选择文件夹中的所有PDF文件。
3、复制文件名:
按 Shift 键并右击选择的文件,然后选择“复制为路径”(在一些系统中显示为“Copy as path”)。这样会将所有文件的完整路径复制到剪贴板。
4、粘贴到Excel:
打开Excel并选择一个空白单元格,然后按 Ctrl + V 粘贴内容。
你会看到每个文件的完整路径被粘贴到单元格中。你可以使用Excel的文本分列功能来提取文件名部分。
方法四:使用命令行进行提起
你可以使用命令行来批量复制PDF文件名到Excel,步骤如下:
1. 打开命令提示符
按 Win + R,输入 cmd,然后按 Enter。
2. 导航到包含PDF文件的文件夹
使用 cd 命令切换到目标文件夹,例如:
cd C:\路径\到\你的\文件夹
3. 生成文件名列表并保存到文本文件
运行以下命令将文件名保存到文本文件中:
dir /b *.pdf > filenames.txt
这将创建一个名为 filenames.txt 的文本文件,其中包含所有PDF文件的名称。
4. 将文本文件导入到Excel
① 打开Excel:
启动Excel并打开一个新工作簿。
② 导入文本文件:
转到“数据”选项卡,选择“从文本/CSV”。
选择刚才创建的 filenames.txt 文件,然后点击“导入”。
③ 配置导入设置:
在导入向导中,确保分隔符设置为“无”或“制表符”,然后点击“加载”或“导入”以将文件名导入到Excel工作表中。
这样,你就可以将PDF文件名批量导入到Excel中了。
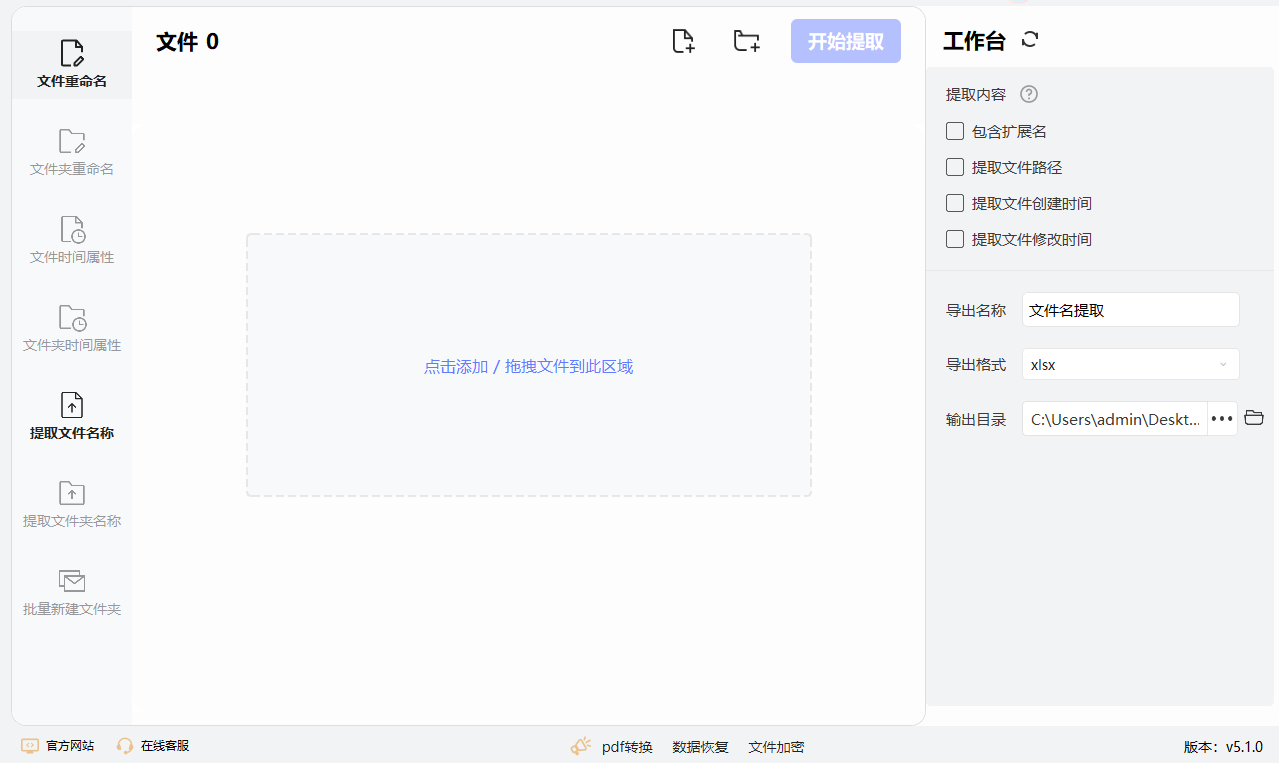
方法五:使用小船文件名批量处理器批量提取
步骤1:启动软件并选择功能
双击电脑桌面上的小船文件名批量处理器图标,启动软件。
在软件的主页面左侧功能栏中,选择点击“提取文件名称”功能。
步骤2:添加PDF文件
点击软件界面上的“添加文件”按钮,或者通过手动拖拽的方式,将需要提取文件名的PDF文件添加到软件中。
确保所有需要提取文件名的PDF文件都已成功添加到软件中。
步骤3:设置提取内容
在文件添加之后,软件右侧会显示“提取内容”设置区域。
在这里,你可以勾选需要提取的内容条件,通常只需要默认设置即可,因为我们的目标是提取文件名。
步骤4:设置导出选项
接下来,你需要设置导出的名称和格式。在软件的相应位置,输入你希望导出的Excel文件的名称。
在导出格式选项中,选择“xlsx”作为导出格式,这是Excel表格的标准格式。
步骤5:开始提取
确认所有设置无误后,点击软件界面上的“开始提取”按钮。
软件将开始批量提取PDF文件的文件名,并将提取结果保存到之前设置的Excel文件中。
步骤6:查看提取结果
提取完成后,软件通常会提示你提取成功,并可能提供前往导出文件夹的快捷方式。
点击“前往导出文件夹”,打开保存提取结果的Excel文件所在的位置。
打开Excel文件,你将看到所有被提取的PDF文件名已经整齐地排列在表格中。
在日常办公中,处理大量PDF文件时,一个常见且实用的需求便是将PDF文件名批量提取到Excel表格中,以便于文件管理和数据分析。这一操作可以极大地提高工作效率,减少手动输入的繁琐与错误。实现这一目标,我们可以借助一些专业的文件管理工具或自动化脚本。对于非技术背景的用户,选择一款界面友好、操作简便的第三方软件会是不错的选择。这些软件通常支持拖放操作,用户只需将需要处理的PDF文件文件夹拖入软件界面,点击“提取”或类似按钮,软件便会自动读取所有文件名,并允许用户直接导出为Excel格式。通过自动化批量提取PDF文件名到Excel的过程,你可以节省大量时间并减少人为错误。这不仅提升了文件管理的效率,还为进一步的数据分析和处理提供了便利。在繁忙的工作环境中,这种自动化工具是提高工作效率的强大助手。上面几个“如何批量提取pdf文件名到excel?”的方法介绍的非常相信,感兴趣的朋友赶紧去试试看吧。















 1199
1199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









